 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Unlearning via Group Relative Policy Optimization
Jan 28, 2026During pretraining, LLMs inadvertently memorize sensitive or copyrighted data, posing significant compliance challenges under legal frameworks like the GDPR and the EU AI Act. Fulfilling these mandates demands techniques that can remove information from a deployed model without retraining from scratch. Existing unlearning approaches attempt to address this need, but often leak the very data they aim to erase, sacrifice fluency and robustness, or depend on costly external reward models. We introduce PURGE (Policy Unlearning through Relative Group Erasure), a novel method grounded in the Group Relative Policy Optimization framework that formulates unlearning as a verifiable problem. PURGE uses an intrinsic reward signal that penalizes any mention of forbidden concepts, allowing safe and consistent unlearning. Our approach reduces token usage per target by up to a factor of 46 compared with SotA methods, while improving fluency by 5.48 percent and adversarial robustness by 12.02 percent over the base model. On the Real World Knowledge Unlearning (RWKU) benchmark, PURGE achieves 11 percent unlearning effectiveness while preserving 98 percent of original utility. PURGE shows that framing LLM unlearning as a verifiable task, enables more reliable, efficient, and scalable forgetting, suggesting a promising new direction for unlearning research that combines theoretical guarantees, improved safety, and practical deployment efficiency.
Moral Lenses, Political Coordinates: Towards Ideological Positioning of Morally Conditioned LLMs
Jan 13, 2026While recent research has systematically documented political orientation in large language models (LLMs), existing evaluations rely primarily on direct probing or demographic persona engineering to surface ideological biases. In social psychology, however, political ideology is also understood as a downstream consequence of fundamental moral intuitions. In this work, we investigate the causal relationship between moral values and political positioning by treating moral orientation as a controllable condition. Rather than simply assigning a demographic persona, we condition models to endorse or reject specific moral values and evaluate the resulting shifts on their political orientations, using the Political Compass Test. By treating moral values as lenses, we observe how moral conditioning actively steers model trajectories across economic and social dimensions. Our findings show that such conditioning induces pronounced, value-specific shifts in models' political coordinates. We further notice that these effects are systematically modulated by role framing and model scale, and are robust across alternative assessment instruments instantiating the same moral value. This highlights that effective alignment requires anchoring political assessments within the context of broader social values including morality, paving the way for more socially grounded alignment techniques.
Injecting Falsehoods: Adversarial Man-in-the-Middle Attacks Undermining Factual Recall in LLMs
Nov 08, 2025LLMs are now an integral part of information retrieval. As such, their role as question answering chatbots raises significant concerns due to their shown vulnerability to adversarial man-in-the-middle (MitM) attacks. Here, we propose the first principled attack evaluation on LLM factual memory under prompt injection via Xmera, our novel, theory-grounded MitM framework. By perturbing the input given to "victim" LLMs in three closed-book and fact-based QA settings, we undermine the correctness of the responses and assess the uncertainty of their generation process. Surprisingly, trivial instruction-based attacks report the highest success rate (up to ~85.3%) while simultaneously having a high uncertainty for incorrectly answered questions. To provide a simple defense mechanism against Xmera, we train Random Forest classifiers on the response uncertainty levels to distinguish between attacked and unattacked queries (average AUC of up to ~96%). We believe that signaling users to be cautious about the answers they receive from black-box and potentially corrupt LLMs is a first checkpoint toward user cyberspace safety.
Structured Universal Adversarial Attacks on Object Detection for Video Sequences
Oct 16, 2025Video-based object detection plays a vital role in safety-critical applications. While deep learning-based object detectors have achieved impressive performance, they remain vulnerable to adversarial attacks, particularly those involving universal perturbations. In this work, we propose a minimally distorted universal adversarial attack tailored for video object detection, which leverages nuclear norm regularization to promote structured perturbations concentrated in the background. To optimize this formulation efficiently, we employ an adaptive, optimistic exponentiated gradient method that enhances both scalability and convergence. Our results demonstrate that the proposed attack outperforms both low-rank projected gradient descent and Frank-Wolfe based attacks in effectiveness while maintaining high stealthiness. All code and data are publicly available at https://github.com/jsve96/AO-Exp-Attack.
CURE: Controlled Unlearning for Robust Embeddings -- Mitigating Conceptual Shortcuts in Pre-Trained Language Models
Sep 05, 2025Pre-trained language models have achieved remarkable success across diverse applications but remain susceptible to spurious, concept-driven correlations that impair robustness and fairness. In this work, we introduce CURE, a novel and lightweight framework that systematically disentangles and suppresses conceptual shortcuts while preserving essential content information. Our method first extracts concept-irrelevant representations via a dedicated content extractor reinforced by a reversal network, ensuring minimal loss of task-relevant information. A subsequent controllable debiasing module employs contrastive learning to finely adjust the influence of residual conceptual cues, enabling the model to either diminish harmful biases or harness beneficial correlations as appropriate for the target task. Evaluated on the IMDB and Yelp datasets using three pre-trained architectures, CURE achieves an absolute improvement of +10 points in F1 score on IMDB and +2 points on Yelp, while introducing minimal computational overhead. Our approach establishes a flexible, unsupervised blueprint for combating conceptual biases, paving the way for more reliable and fair language understanding systems.
Probabilistic Aggregation and Targeted Embedding Optimization for Collective Moral Reasoning in Large Language Models
Jun 18, 2025Large Language Models (LLMs) have shown impressive moral reasoning abilities. Yet they often diverge when confronted with complex, multi-factor moral dilemmas. To address these discrepancies, we propose a framework that synthesizes multiple LLMs' moral judgments into a collectively formulated moral judgment, realigning models that deviate significantly from this consensus. Our aggregation mechanism fuses continuous moral acceptability scores (beyond binary labels) into a collective probability, weighting contributions by model reliability. For misaligned models, a targeted embedding-optimization procedure fine-tunes token embeddings for moral philosophical theories, minimizing JS divergence to the consensus while preserving semantic integrity. Experiments on a large-scale social moral dilemma dataset show our approach builds robust consensus and improves individual model fidelity. These findings highlight the value of data-driven moral alignment across multiple models and its potential for safer, more consistent AI systems.
SCISSOR: Mitigating Semantic Bias through Cluster-Aware Siamese Networks for Robust Classification
Jun 17, 2025Shortcut learning undermines model generalization to out-of-distribution data. While the literature attributes shortcuts to biases in superficial features, we show that imbalances in the semantic distribution of sample embeddings induce spurious semantic correlations, compromising model robustness. To address this issue, we propose SCISSOR (Semantic Cluster Intervention for Suppressing ShORtcut), a Siamese network-based debiasing approach that remaps the semantic space by discouraging latent clusters exploited as shortcuts. Unlike prior data-debiasing approaches, SCISSOR eliminates the need for data augmentation and rewriting. We evaluate SCISSOR on 6 models across 4 benchmarks: Chest-XRay and Not-MNIST in computer vision, and GYAFC and Yelp in NLP tasks. Compared to several baselines, SCISSOR reports +5.3 absolute points in F1 score on GYAFC, +7.3 on Yelp, +7.7 on Chest-XRay, and +1 on Not-MNIST. SCISSOR is also highly advantageous for lightweight models with ~9.5% improvement on F1 for ViT on computer vision datasets and ~11.9% for BERT on NLP. Our study redefines the landscape of model generalization by addressing overlooked semantic biases, establishing SCISSOR as a foundational framework for mitigating shortcut learning and fostering more robust, bias-resistant AI systems.
Position: Uncertainty Quantification Needs Reassessment for Large-language Model Agents
May 28, 2025Large-language models (LLMs) and chatbot agents are known to provide wrong outputs at times, and it was recently found that this can never be fully prevented. Hence, uncertainty quantification plays a crucial role, aiming to quantify the level of ambiguity in either one overall number or two numbers for aleatoric and epistemic uncertainty. This position paper argues that this traditional dichotomy of uncertainties is too limited for the open and interactive setup that LLM agents operate in when communicating with a user, and that we need to research avenues that enrich uncertainties in this novel scenario. We review the literature and find that popular definitions of aleatoric and epistemic uncertainties directly contradict each other and lose their meaning in interactive LLM agent settings. Hence, we propose three novel research directions that focus on uncertainties in such human-computer interactions: Underspecification uncertainties, for when users do not provide all information or define the exact task at the first go, interactive learning, to ask follow-up questions and reduce the uncertainty about the current context, and output uncertainties, to utilize the rich language and speech space to express uncertainties as more than mere numbers. We expect that these new ways of dealing with and communicating uncertainties will lead to LLM agent interactions that are more transparent, trustworthy, and intuitive.
Graph Style Transfer for Counterfactual Explainability
May 23, 2025Counterfactual explainability seeks to uncover model decisions by identifying minimal changes to the input that alter the predicted outcome. This task becomes particularly challenging for graph data due to preserving structural integrity and semantic meaning. Unlike prior approaches that rely on forward perturbation mechanisms, we introduce Graph Inverse Style Transfer (GIST), the first framework to re-imagine graph counterfactual generation as a backtracking process, leveraging spectral style transfer. By aligning the global structure with the original input spectrum and preserving local content faithfulness, GIST produces valid counterfactuals as interpolations between the input style and counterfactual content. Tested on 8 binary and multi-class graph classification benchmarks, GIST achieves a remarkable +7.6% improvement in the validity of produced counterfactuals and significant gains (+45.5%) in faithfully explaining the true class distribution. Additionally, GIST's backtracking mechanism effectively mitigates overshooting the underlying predictor's decision boundary, minimizing the spectral differences between the input and the counterfactuals. These results challenge traditional forward perturbation methods, offering a novel perspective that advances graph explainability.
Gender Bias in Explainability: Investigating Performance Disparity in Post-hoc Methods
May 02, 2025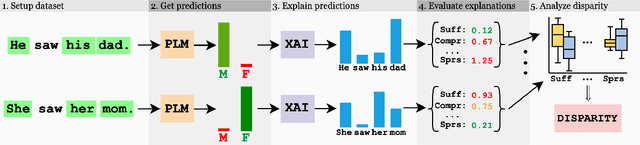


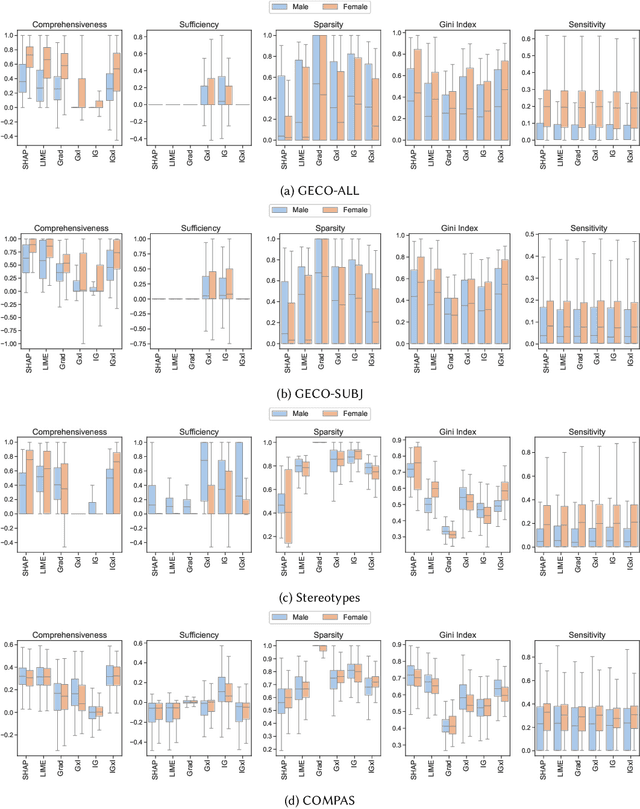
While research on applications and evaluations of explanation methods continues to expand, fairness of the explanation methods concerning disparities in their performance across subgroups remains an often overlooked aspect. In this paper, we address this gap by showing that, across three tasks and five language models, widely used post-hoc feature attribution methods exhibit significant gender disparity with respect to their faithfulness, robustness, and complexity. These disparities persist even when the models are pre-trained or fine-tuned on particularly unbiased datasets, indicating that the disparities we observe are not merely consequences of biased training data. Our results highlight the importance of addressing disparities in explanations when developing and applying explainability methods, as these can lead to biased outcomes against certain subgroups, with particularly critical implications in high-stakes contexts. Furthermore, our findings underscore the importance of incorporating the fairness of explanations, alongside overall model fairness and explainability, as a requirement in regulatory frameworks.