 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersona Prompting as a Lens on LLM Social Reasoning
Jan 28, 2026For socially sensitive tasks like hate speech detection, the quality of explanations from Large Language Models (LLMs) is crucial for factors like user trust and model alignment. While Persona prompting (PP) is increasingly used as a way to steer model towards user-specific generation, its effect on model rationales remains underexplored. We investigate how LLM-generated rationales vary when conditioned on different simulated demographic personas. Using datasets annotated with word-level rationales, we measure agreement with human annotations from different demographic groups, and assess the impact of PP on model bias and human alignment. Our evaluation across three LLMs results reveals three key findings: (1) PP improving classification on the most subjective task (hate speech) but degrading rationale quality. (2) Simulated personas fail to align with their real-world demographic counterparts, and high inter-persona agreement shows models are resistant to significant steering. (3) Models exhibit consistent demographic biases and a strong tendency to over-flag content as harmful, regardless of PP. Our findings reveal a critical trade-off: while PP can improve classification in socially-sensitive tasks, it often comes at the cost of rationale quality and fails to mitigate underlying biases, urging caution in its application.
Order in the Evaluation Court: A Critical Analysis of NLG Evaluation Trends
Jan 12, 2026Despite advances in Natural Language Generation (NLG), evaluation remains challenging. Although various new metrics and LLM-as-a-judge (LaaJ) methods are proposed, human judgment persists as the gold standard. To systematically review how NLG evaluation has evolved, we employ an automatic information extraction scheme to gather key information from NLG papers, focusing on different evaluation methods (metrics, LaaJ and human evaluation). With extracted metadata from 14,171 papers across four major conferences (ACL, EMNLP, NAACL, and INLG) over the past six years, we reveal several critical findings: (1) Task Divergence: While Dialogue Generation demonstrates a rapid shift toward LaaJ (>40% in 2025), Machine Translation remains locked into n-gram metrics, and Question Answering exhibits a substantial decline in the proportion of studies conducting human evaluation. (2) Metric Inertia: Despite the development of semantic metrics, general-purpose metrics (e.g., BLEU, ROUGE) continue to be widely used across tasks without empirical justification, often lacking the discriminative power to distinguish between specific quality criteria. (3) Human-LaaJ Divergence: Our association analysis challenges the assumption that LLMs act as mere proxies for humans; LaaJ and human evaluations prioritize very different signals, and explicit validation is scarce (<8% of papers comparing the two), with only moderate to low correlation. Based on these observations, we derive practical recommendations to improve the rigor of future NLG evaluation.
iFlip: Iterative Feedback-driven Counterfactual Example Refinement
Jan 04, 2026Counterfactual examples are minimal edits to an input that alter a model's prediction. They are widely employed in explainable AI to probe model behavior and in natural language processing (NLP) to augment training data. However, generating valid counterfactuals with large language models (LLMs) remains challenging, as existing single-pass methods often fail to induce reliable label changes, neglecting LLMs' self-correction capabilities. To explore this untapped potential, we propose iFlip, an iterative refinement approach that leverages three types of feedback, including model confidence, feature attribution, and natural language. Our results show that iFlip achieves an average 57.8% higher validity than the five state-of-the-art baselines, as measured by the label flipping rate. The user study further corroborates that iFlip outperforms baselines in completeness, overall satisfaction, and feasibility. In addition, ablation studies demonstrate that three components are paramount for iFlip to generate valid counterfactuals: leveraging an appropriate number of iterations, pointing to highly attributed words, and early stopping. Finally, counterfactuals generated by iFlip enable effective counterfactual data augmentation, substantially improving model performance and robustness.
Can Large Language Models Still Explain Themselves? Investigating the Impact of Quantization on Self-Explanations
Jan 01, 2026Quantization is widely used to accelerate inference and streamline the deployment of large language models (LLMs), yet its effects on self-explanations (SEs) remain unexplored. SEs, generated by LLMs to justify their own outputs, require reasoning about the model's own decision-making process, a capability that may exhibit particular sensitivity to quantization. As SEs are increasingly relied upon for transparency in high-stakes applications, understanding whether and to what extent quantization degrades SE quality and faithfulness is critical. To address this gap, we examine two types of SEs: natural language explanations (NLEs) and counterfactual examples, generated by LLMs quantized using three common techniques at distinct bit widths. Our findings indicate that quantization typically leads to moderate declines in both SE quality (up to 4.4\%) and faithfulness (up to 2.38\%). The user study further demonstrates that quantization diminishes both the coherence and trustworthiness of SEs (up to 8.5\%). Compared to smaller models, larger models show limited resilience to quantization in terms of SE quality but better maintain faithfulness. Moreover, no quantization technique consistently excels across task accuracy, SE quality, and faithfulness. Given that quantization's impact varies by context, we recommend validating SE quality for specific use cases, especially for NLEs, which show greater sensitivity. Nonetheless, the relatively minor deterioration in SE quality and faithfulness does not undermine quantization's effectiveness as a model compression technique.
Parallel Universes, Parallel Languages: A Comprehensive Study on LLM-based Multilingual Counterfactual Example Generation
Jan 01, 2026Counterfactuals refer to minimally edited inputs that cause a model's prediction to change, serving as a promising approach to explaining the model's behavior. Large language models (LLMs) excel at generating English counterfactuals and demonstrate multilingual proficiency. However, their effectiveness in generating multilingual counterfactuals remains unclear. To this end, we conduct a comprehensive study on multilingual counterfactuals. We first conduct automatic evaluations on both directly generated counterfactuals in the target languages and those derived via English translation across six languages. Although translation-based counterfactuals offer higher validity than their directly generated counterparts, they demand substantially more modifications and still fall short of matching the quality of the original English counterfactuals. Second, we find the patterns of edits applied to high-resource European-language counterfactuals to be remarkably similar, suggesting that cross-lingual perturbations follow common strategic principles. Third, we identify and categorize four main types of errors that consistently appear in the generated counterfactuals across languages. Finally, we reveal that multilingual counterfactual data augmentation (CDA) yields larger model performance improvements than cross-lingual CDA, especially for lower-resource languages. Yet, the imperfections of the generated counterfactuals limit gains in model performance and robustness.
Multilingual Datasets for Custom Input Extraction and Explanation Requests Parsing in Conversational XAI Systems
Aug 20, 2025Conversational explainable artificial intelligence (ConvXAI) systems based on large language models (LLMs) have garnered considerable attention for their ability to enhance user comprehension through dialogue-based explanations. Current ConvXAI systems often are based on intent recognition to accurately identify the user's desired intention and map it to an explainability method. While such methods offer great precision and reliability in discerning users' underlying intentions for English, a significant challenge in the scarcity of training data persists, which impedes multilingual generalization. Besides, the support for free-form custom inputs, which are user-defined data distinct from pre-configured dataset instances, remains largely limited. To bridge these gaps, we first introduce MultiCoXQL, a multilingual extension of the CoXQL dataset spanning five typologically diverse languages, including one low-resource language. Subsequently, we propose a new parsing approach aimed at enhancing multilingual parsing performance, and evaluate three LLMs on MultiCoXQL using various parsing strategies. Furthermore, we present Compass, a new multilingual dataset designed for custom input extraction in ConvXAI systems, encompassing 11 intents across the same five languages as MultiCoXQL. We conduct monolingual, cross-lingual, and multilingual evaluations on Compass, employing three LLMs of varying sizes alongside BERT-type models.
Infherno: End-to-end Agent-based FHIR Resource Synthesis from Free-form Clinical Notes
Jul 16, 2025



For clinical data integration and healthcare services, the HL7 FHIR standard has established itself as a desirable format for interoperability between complex health data. Previous attempts at automating the translation from free-form clinical notes into structured FHIR resources rely on modular, rule-based systems or LLMs with instruction tuning and constrained decoding. Since they frequently suffer from limited generalizability and structural inconformity, we propose an end-to-end framework powered by LLM agents, code execution, and healthcare terminology database tools to address these issues. Our solution, called Infherno, is designed to adhere to the FHIR document schema and competes well with a human baseline in predicting FHIR resources from unstructured text. The implementation features a front end for custom and synthetic data and both local and proprietary models, supporting clinical data integration processes and interoperability across institutions.
Capturing Polysemanticity with PRISM: A Multi-Concept Feature Description Framework
Jun 18, 2025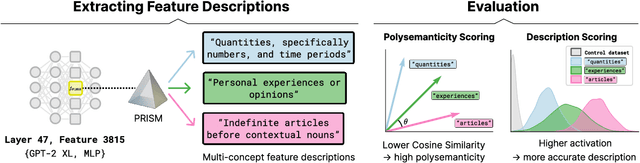

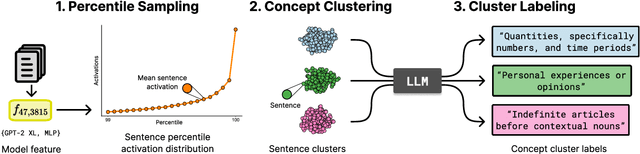

Automated interpretability research aims to identify concepts encoded in neural network features to enhance human understanding of model behavior. Current feature description methods face two critical challenges: limited robustness and the flawed assumption that each neuron encodes only a single concept (monosemanticity), despite growing evidence that neurons are often polysemantic. This assumption restricts the expressiveness of feature descriptions and limits their ability to capture the full range of behaviors encoded in model internals. To address this, we introduce Polysemantic FeatuRe Identification and Scoring Method (PRISM), a novel framework that captures the inherent complexity of neural network features. Unlike prior approaches that assign a single description per feature, PRISM provides more nuanced descriptions for both polysemantic and monosemantic features. We apply PRISM to language models and, through extensive benchmarking against existing methods, demonstrate that our approach produces more accurate and faithful feature descriptions, improving both overall description quality (via a description score) and the ability to capture distinct concepts when polysemanticity is present (via a polysemanticity score).
Truth or Twist? Optimal Model Selection for Reliable Label Flipping Evaluation in LLM-based Counterfactuals
May 20, 2025Counterfactual examples are widely employed to enhance the performance and robustness of large language models (LLMs) through counterfactual data augmentation (CDA). However, the selection of the judge model used to evaluate label flipping, the primary metric for assessing the validity of generated counterfactuals for CDA, yields inconsistent results. To decipher this, we define four types of relationships between the counterfactual generator and judge models. Through extensive experiments involving two state-of-the-art LLM-based methods, three datasets, five generator models, and 15 judge models, complemented by a user study (n = 90), we demonstrate that judge models with an independent, non-fine-tuned relationship to the generator model provide the most reliable label flipping evaluations. Relationships between the generator and judge models, which are closely aligned with the user study for CDA, result in better model performance and robustness. Nevertheless, we find that the gap between the most effective judge models and the results obtained from the user study remains considerably large. This suggests that a fully automated pipeline for CDA may be inadequate and requires human intervention.
Through a Compressed Lens: Investigating the Impact of Quantization on LLM Explainability and Interpretability
May 20, 2025Quantization methods are widely used to accelerate inference and streamline the deployment of large language models (LLMs). While prior research has extensively investigated the degradation of various LLM capabilities due to quantization, its effects on model explainability and interpretability, which are crucial for understanding decision-making processes, remain unexplored. To address this gap, we conduct comprehensive experiments using three common quantization techniques at distinct bit widths, in conjunction with two explainability methods, counterfactual examples and natural language explanations, as well as two interpretability approaches, knowledge memorization analysis and latent multi-hop reasoning analysis. We complement our analysis with a thorough user study, evaluating selected explainability methods. Our findings reveal that, depending on the configuration, quantization can significantly impact model explainability and interpretability. Notably, the direction of this effect is not consistent, as it strongly depends on (1) the quantization method, (2) the explainability or interpretability approach, and (3) the evaluation protocol. In some settings, human evaluation shows that quantization degrades explainability, while in others, it even leads to improvements. Our work serves as a cautionary tale, demonstrating that quantization can unpredictably affect model transparency. This insight has important implications for deploying LLMs in applications where transparency is a critical requirement.