 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurkicNLP: An NLP Toolkit for Turkic Languages
Feb 22, 2026Natural language processing for the Turkic language family, spoken by over 200 million people across Eurasia, remains fragmented, with most languages lacking unified tooling and resources. We present TurkicNLP, an open-source Python library providing a single, consistent NLP pipeline for Turkic languages across four script families: Latin, Cyrillic, Perso-Arabic, and Old Turkic Runic. The library covers tokenization, morphological analysis, part-of-speech tagging, dependency parsing, named entity recognition, bidirectional script transliteration, cross-lingual sentence embeddings, and machine translation through one language-agnostic API. A modular multi-backend architecture integrates rule-based finite-state transducers and neural models transparently, with automatic script detection and routing between script variants. Outputs follow the CoNLL-U standard for full interoperability and extension. Code and documentation are hosted at https://github.com/turkic-nlp/turkicnlp .
Order in the Evaluation Court: A Critical Analysis of NLG Evaluation Trends
Jan 12, 2026Despite advances in Natural Language Generation (NLG), evaluation remains challenging. Although various new metrics and LLM-as-a-judge (LaaJ) methods are proposed, human judgment persists as the gold standard. To systematically review how NLG evaluation has evolved, we employ an automatic information extraction scheme to gather key information from NLG papers, focusing on different evaluation methods (metrics, LaaJ and human evaluation). With extracted metadata from 14,171 papers across four major conferences (ACL, EMNLP, NAACL, and INLG) over the past six years, we reveal several critical findings: (1) Task Divergence: While Dialogue Generation demonstrates a rapid shift toward LaaJ (>40% in 2025), Machine Translation remains locked into n-gram metrics, and Question Answering exhibits a substantial decline in the proportion of studies conducting human evaluation. (2) Metric Inertia: Despite the development of semantic metrics, general-purpose metrics (e.g., BLEU, ROUGE) continue to be widely used across tasks without empirical justification, often lacking the discriminative power to distinguish between specific quality criteria. (3) Human-LaaJ Divergence: Our association analysis challenges the assumption that LLMs act as mere proxies for humans; LaaJ and human evaluations prioritize very different signals, and explicit validation is scarce (<8% of papers comparing the two), with only moderate to low correlation. Based on these observations, we derive practical recommendations to improve the rigor of future NLG evaluation.
From Templates to Natural Language: Generalization Challenges in Instruction-Tuned LLMs for Spatial Reasoning
May 20, 2025



Instruction-tuned large language models (LLMs) have shown strong performance on a variety of tasks; however, generalizing from synthetic to human-authored instructions in grounded environments remains a challenge for them. In this work, we study generalization challenges in spatial grounding tasks where models interpret and translate instructions for building object arrangements on a $2.5$D grid. We fine-tune LLMs using only synthetic instructions and evaluate their performance on a benchmark dataset containing both synthetic and human-written instructions. Our results reveal that while models generalize well on simple tasks, their performance degrades significantly on more complex tasks. We present a detailed error analysis of the gaps in instruction generalization.
clem:todd: A Framework for the Systematic Benchmarking of LLM-Based Task-Oriented Dialogue System Realisations
May 08, 2025The emergence of instruction-tuned large language models (LLMs) has advanced the field of dialogue systems, enabling both realistic user simulations and robust multi-turn conversational agents. However, existing research often evaluates these components in isolation-either focusing on a single user simulator or a specific system design-limiting the generalisability of insights across architectures and configurations. In this work, we propose clem todd (chat-optimized LLMs for task-oriented dialogue systems development), a flexible framework for systematically evaluating dialogue systems under consistent conditions. clem todd enables detailed benchmarking across combinations of user simulators and dialogue systems, whether existing models from literature or newly developed ones. It supports plug-and-play integration and ensures uniform datasets, evaluation metrics, and computational constraints. We showcase clem todd's flexibility by re-evaluating existing task-oriented dialogue systems within this unified setup and integrating three newly proposed dialogue systems into the same evaluation pipeline. Our results provide actionable insights into how architecture, scale, and prompting strategies affect dialogue performance, offering practical guidance for building efficient and effective conversational AI systems.
Playpen: An Environment for Exploring Learning Through Conversational Interaction
Apr 11, 2025
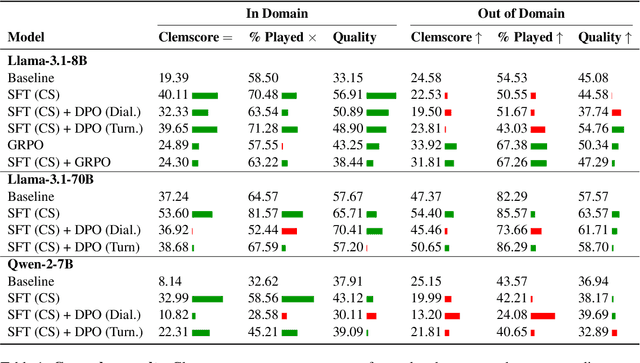


Are we running out of learning signal? Predicting the next word in an existing text has turned out to be a powerful signal, at least at scale. But there are signs that we are running out of this resource. In recent months, interaction between learner and feedback-giver has come into focus, both for "alignment" (with a reward model judging the quality of instruction following attempts) and for improving "reasoning" (process- and outcome-based verifiers judging reasoning steps). In this paper, we explore to what extent synthetic interaction in what we call Dialogue Games -- goal-directed and rule-governed activities driven predominantly by verbal actions -- can provide a learning signal, and how this signal can be used. We introduce an environment for producing such interaction data (with the help of a Large Language Model as counterpart to the learner model), both offline and online. We investigate the effects of supervised fine-tuning on this data, as well as reinforcement learning setups such as DPO, and GRPO; showing that all of these approaches achieve some improvements in in-domain games, but only GRPO demonstrates the ability to generalise to out-of-domain games as well as retain competitive performance in reference-based tasks. We release the framework and the baseline training setups in the hope that this can foster research in this promising new direction.
Plant in Cupboard, Orange on Table, Book on Shelf. Benchmarking Practical Reasoning and Situation Modelling in a Text-Simulated Situated Environment
Feb 17, 2025



Large language models (LLMs) have risen to prominence as 'chatbots' for users to interact via natural language. However, their abilities to capture common-sense knowledge make them seem promising as language-based planners of situated or embodied action as well. We have implemented a simple text-based environment -- similar to others that have before been used for reinforcement-learning of agents -- that simulates, very abstractly, a household setting. We use this environment and the detailed error-tracking capabilities we implemented for targeted benchmarking of LLMs on the problem of practical reasoning: Going from goals and observations to actions. Our findings show that environmental complexity and game restrictions hamper performance, and concise action planning is demanding for current LLMs.
Ad-hoc Concept Forming in the Game Codenames as a Means for Evaluating Large Language Models
Feb 17, 2025



This study utilizes the game Codenames as a benchmarking tool to evaluate large language models (LLMs) with respect to specific linguistic and cognitive skills. LLMs play each side of the game, where one side generates a clue word covering several target words and the other guesses those target words. We designed various experiments by controlling the choice of words (abstract vs. concrete words, ambiguous vs. monosemic) or the opponent (programmed to be faster or slower in revealing words). Recent commercial and open-weight models were compared side-by-side to find out factors affecting their performance. The evaluation reveals details about their strategies, challenging cases, and limitations of LLMs.
Towards No-Code Programming of Cobots: Experiments with Code Synthesis by Large Code Models for Conversational Programming
Sep 18, 2024



While there has been a lot of research recently on robots in household environments, at the present time, most robots in existence can be found on shop floors, and most interactions between humans and robots happen there. ``Collaborative robots'' (cobots) designed to work alongside humans on assembly lines traditionally require expert programming, limiting ability to make changes, or manual guidance, limiting expressivity of the resulting programs. To address these limitations, we explore using Large Language Models (LLMs), and in particular, their abilities of doing in-context learning, for conversational code generation. As a first step, we define RATS, the ``Repetitive Assembly Task'', a 2D building task designed to lay the foundation for simulating industry assembly scenarios. In this task, a `programmer' instructs a cobot, using natural language, on how a certain assembly is to be built; that is, the programmer induces a program, through natural language. We create a dataset that pairs target structures with various example instructions (human-authored, template-based, and model-generated) and example code. With this, we systematically evaluate the capabilities of state-of-the-art LLMs for synthesising this kind of code, given in-context examples. Evaluating in a simulated environment, we find that LLMs are capable of generating accurate `first order code' (instruction sequences), but have problems producing `higher-order code' (abstractions such as functions, or use of loops).
Free-text Rationale Generation under Readability Level Control
Jul 01, 2024Free-text rationales justify model decisions in natural language and thus become likable and accessible among approaches to explanation across many tasks. However, their effectiveness can be hindered by misinterpretation and hallucination. As a perturbation test, we investigate how large language models (LLMs) perform the task of natural language explanation (NLE) under the effects of readability level control, i.e., being prompted for a rationale targeting a specific expertise level, such as sixth grade or college. We find that explanations are adaptable to such instruction, but the requested readability is often misaligned with the measured text complexity according to traditional readability metrics. Furthermore, the quality assessment shows that LLMs' ratings of rationales across text complexity exhibit a similar pattern of preference as observed in natural language generation (NLG). Finally, our human evaluation suggests a generally satisfactory impression on rationales at all readability levels, with high-school-level readability being most commonly perceived and favored.
Two Giraffes in a Dirt Field: Using Game Play to Investigate Situation Modelling in Large Multimodal Models
Jun 20, 2024



While the situation has improved for text-only models, it again seems to be the case currently that multimodal (text and image) models develop faster than ways to evaluate them. In this paper, we bring a recently developed evaluation paradigm from text models to multimodal models, namely evaluation through the goal-oriented game (self) play, complementing reference-based and preference-based evaluation. Specifically, we define games that challenge a model's capability to represent a situation from visual information and align such representations through dialogue. We find that the largest closed models perform rather well on the games that we define, while even the best open-weight models struggle with them. On further analysis, we find that the exceptional deep captioning capabilities of the largest models drive some of the performance. There is still room to grow for both kinds of models, ensuring the continued relevance of the benchmark.