 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlaypen: An Environment for Exploring Learning Through Conversational Interaction
Apr 11, 2025
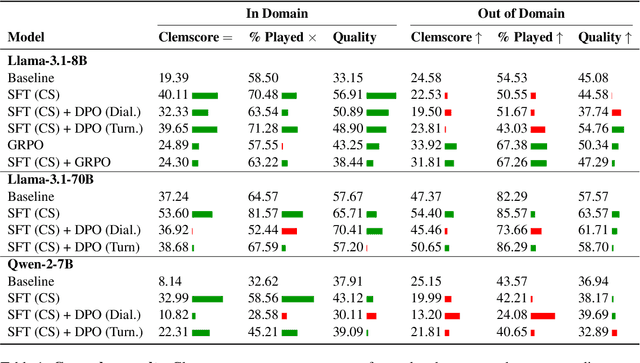


Are we running out of learning signal? Predicting the next word in an existing text has turned out to be a powerful signal, at least at scale. But there are signs that we are running out of this resource. In recent months, interaction between learner and feedback-giver has come into focus, both for "alignment" (with a reward model judging the quality of instruction following attempts) and for improving "reasoning" (process- and outcome-based verifiers judging reasoning steps). In this paper, we explore to what extent synthetic interaction in what we call Dialogue Games -- goal-directed and rule-governed activities driven predominantly by verbal actions -- can provide a learning signal, and how this signal can be used. We introduce an environment for producing such interaction data (with the help of a Large Language Model as counterpart to the learner model), both offline and online. We investigate the effects of supervised fine-tuning on this data, as well as reinforcement learning setups such as DPO, and GRPO; showing that all of these approaches achieve some improvements in in-domain games, but only GRPO demonstrates the ability to generalise to out-of-domain games as well as retain competitive performance in reference-based tasks. We release the framework and the baseline training setups in the hope that this can foster research in this promising new direction.
The Unreasonable Ineffectiveness of Nucleus Sampling on Mitigating Text Memorization
Aug 29, 2024



This work analyses the text memorization behavior of large language models (LLMs) when subjected to nucleus sampling. Stochastic decoding methods like nucleus sampling are typically applied to overcome issues such as monotonous and repetitive text generation, which are often observed with maximization-based decoding techniques. We hypothesize that nucleus sampling might also reduce the occurrence of memorization patterns, because it could lead to the selection of tokens outside the memorized sequence. To test this hypothesis we create a diagnostic dataset with a known distribution of duplicates that gives us some control over the likelihood of memorization of certain parts of the training data. Our analysis of two GPT-Neo models fine-tuned on this dataset interestingly shows that (i) an increase of the nucleus size reduces memorization only modestly, and (ii) even when models do not engage in "hard" memorization -- a verbatim reproduction of training samples -- they may still display "soft" memorization whereby they generate outputs that echo the training data but without a complete one-by-one resemblance.
clembench-2024: A Challenging, Dynamic, Complementary, Multilingual Benchmark and Underlying Flexible Framework for LLMs as Multi-Action Agents
May 31, 2024



It has been established in recent work that Large Language Models (LLMs) can be prompted to "self-play" conversational games that probe certain capabilities (general instruction following, strategic goal orientation, language understanding abilities), where the resulting interactive game play can be automatically scored. In this paper, we take one of the proposed frameworks for setting up such game-play environments, and further test its usefulness as an evaluation instrument, along a number of dimensions: We show that it can easily keep up with new developments while avoiding data contamination, we show that the tests implemented within it are not yet saturated (human performance is substantially higher than that of even the best models), and we show that it lends itself to investigating additional questions, such as the impact of the prompting language on performance. We believe that the approach forms a good basis for making decisions on model choice for building applied interactive systems, and perhaps ultimately setting up a closed-loop development environment of system and simulated evaluator.
Sharing the Cost of Success: A Game for Evaluating and Learning Collaborative Multi-Agent Instruction Giving and Following Policies
Mar 26, 2024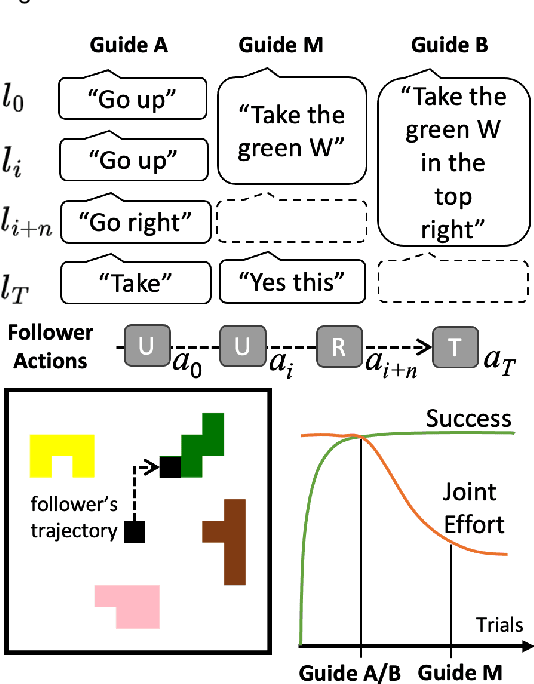
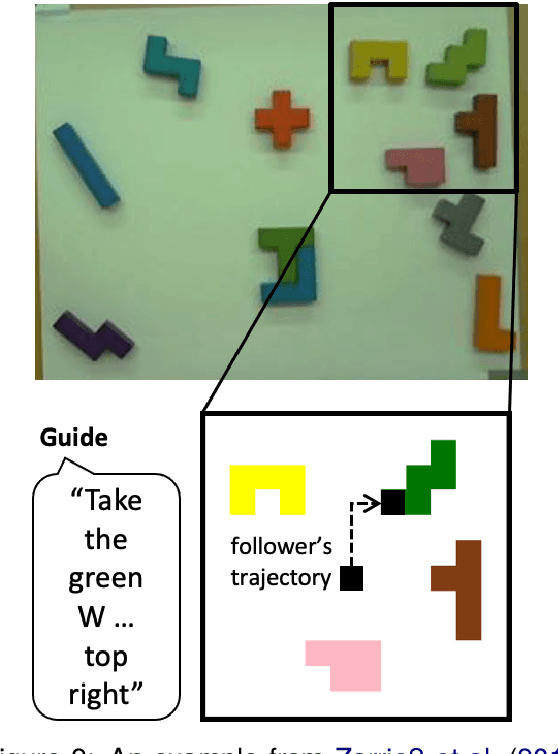
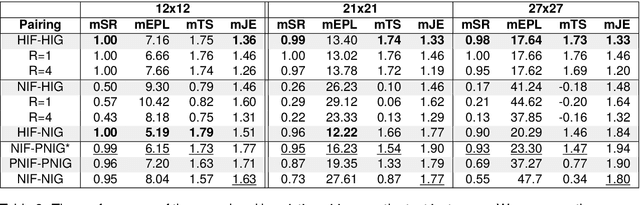
In collaborative goal-oriented settings, the participants are not only interested in achieving a successful outcome, but do also implicitly negotiate the effort they put into the interaction (by adapting to each other). In this work, we propose a challenging interactive reference game that requires two players to coordinate on vision and language observations. The learning signal in this game is a score (given after playing) that takes into account the achieved goal and the players' assumed efforts during the interaction. We show that a standard Proximal Policy Optimization (PPO) setup achieves a high success rate when bootstrapped with heuristic partner behaviors that implement insights from the analysis of human-human interactions. And we find that a pairing of neural partners indeed reduces the measured joint effort when playing together repeatedly. However, we observe that in comparison to a reasonable heuristic pairing there is still room for improvement -- which invites further research in the direction of cost-sharing in collaborative interactions.
Learning Communication Policies for Different Follower Behaviors in a Collaborative Reference Game
Feb 07, 2024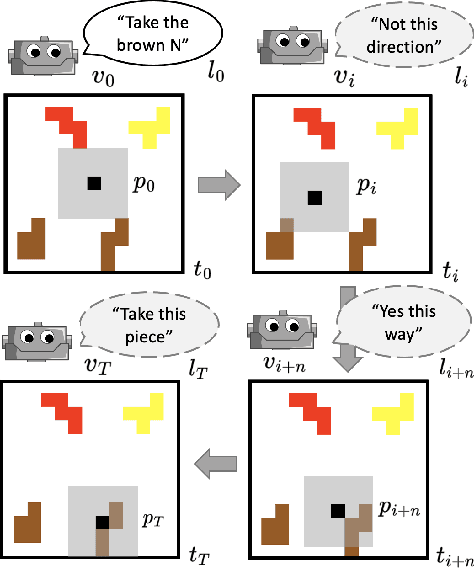
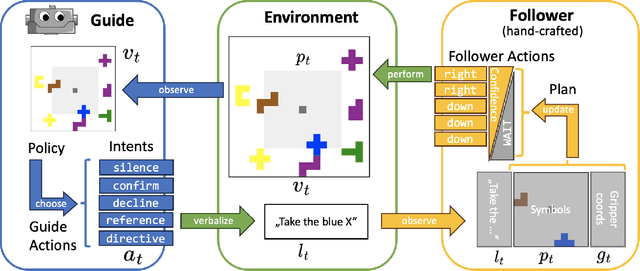
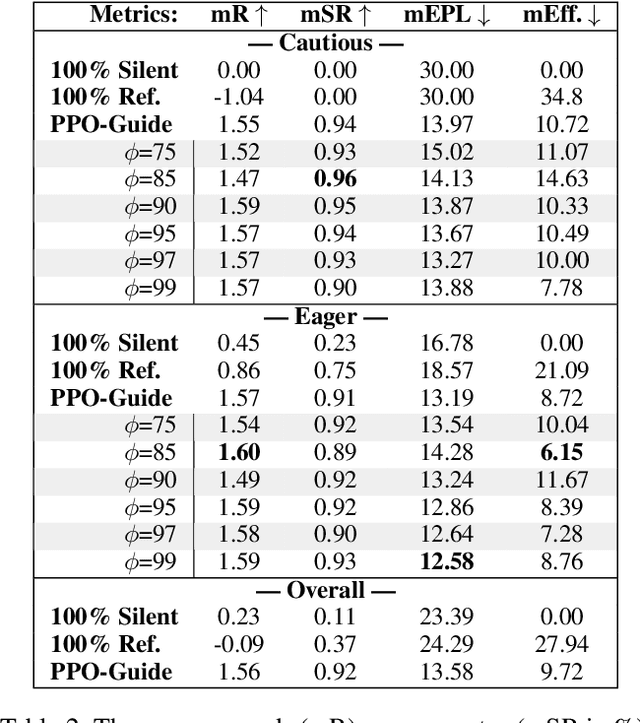
Albrecht and Stone (2018) state that modeling of changing behaviors remains an open problem "due to the essentially unconstrained nature of what other agents may do". In this work we evaluate the adaptability of neural artificial agents towards assumed partner behaviors in a collaborative reference game. In this game success is achieved when a knowledgeable Guide can verbally lead a Follower to the selection of a specific puzzle piece among several distractors. We frame this language grounding and coordination task as a reinforcement learning problem and measure to which extent a common reinforcement training algorithm (PPO) is able to produce neural agents (the Guides) that perform well with various heuristic Follower behaviors that vary along the dimensions of confidence and autonomy. We experiment with a learning signal that in addition to the goal condition also respects an assumed communicative effort. Our results indicate that this novel ingredient leads to communicative strategies that are less verbose (staying silent in some of the steps) and that with respect to that the Guide's strategies indeed adapt to the partner's level of confidence and autonomy.
Pento-DIARef: A Diagnostic Dataset for Learning the Incremental Algorithm for Referring Expression Generation from Examples
May 24, 2023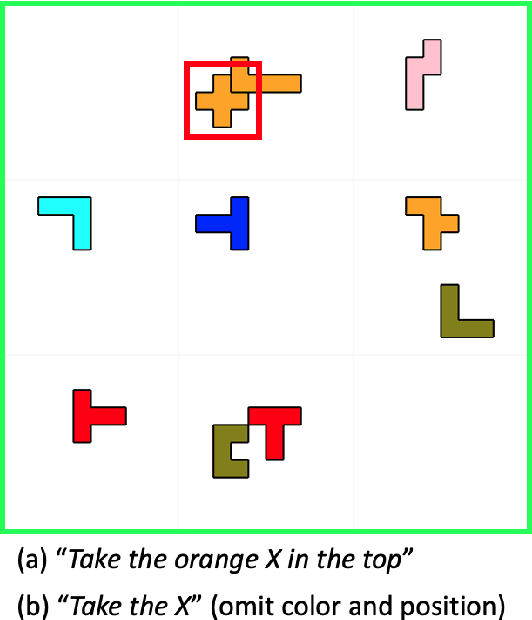

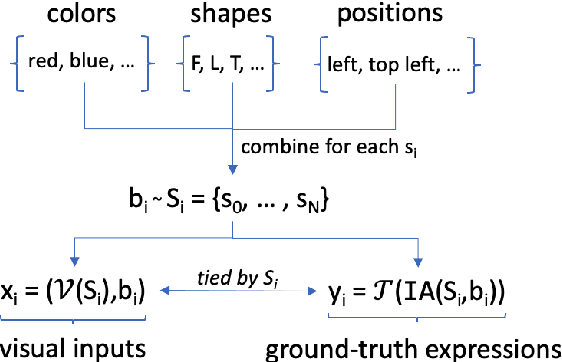
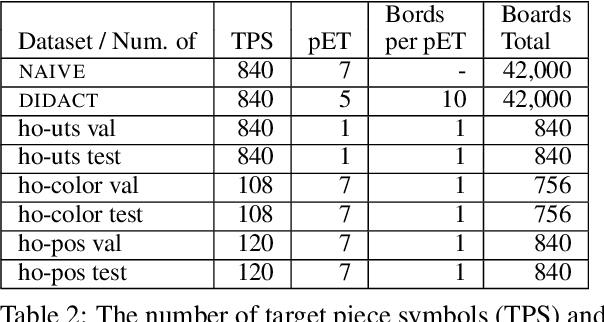
NLP tasks are typically defined extensionally through datasets containing example instantiations (e.g., pairs of image i and text t), but motivated intensionally through capabilities invoked in verbal descriptions of the task (e.g., "t is a description of i, for which the content of i needs to be recognised and understood"). We present Pento-DIARef, a diagnostic dataset in a visual domain of puzzle pieces where referring expressions are generated by a well-known symbolic algorithm (the "Incremental Algorithm"), which itself is motivated by appeal to a hypothesised capability (eliminating distractors through application of Gricean maxims). Our question then is whether the extensional description (the dataset) is sufficient for a neural model to pick up the underlying regularity and exhibit this capability given the simple task definition of producing expressions from visual inputs. We find that a model supported by a vision detection step and a targeted data generation scheme achieves an almost perfect BLEU@1 score and sentence accuracy, whereas simpler baselines do not.
clembench: Using Game Play to Evaluate Chat-Optimized Language Models as Conversational Agents
May 22, 2023
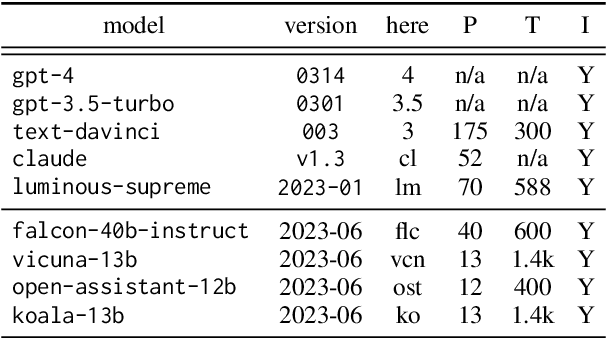
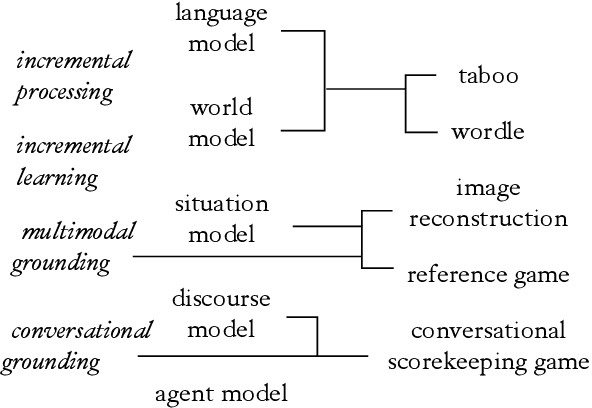
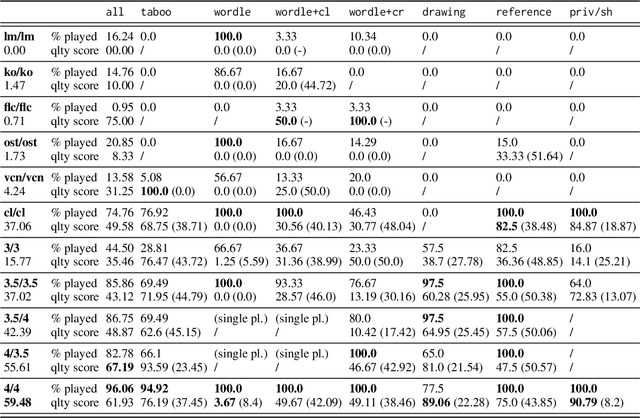
Recent work has proposed a methodology for the systematic evaluation of "Situated Language Understanding Agents"-agents that operate in rich linguistic and non-linguistic contexts-through testing them in carefully constructed interactive settings. Other recent work has argued that Large Language Models (LLMs), if suitably set up, can be understood as (simulators of) such agents. A connection suggests itself, which this paper explores: Can LLMs be evaluated meaningfully by exposing them to constrained game-like settings that are built to challenge specific capabilities? As a proof of concept, this paper investigates five interaction settings, showing that current chat-optimised LLMs are, to an extent, capable to follow game-play instructions. Both this capability and the quality of the game play, measured by how well the objectives of the different games are met, follows the development cycle, with newer models performing better. The metrics even for the comparatively simple example games are far from being saturated, suggesting that the proposed instrument will remain to have diagnostic value. Our general framework for implementing and evaluating games with LLMs is available at https://github.com/clp-research/clembench.
Yes, this Way! Learning to Ground Referring Expressions into Actions with Intra-episodic Feedback from Supportive Teachers
May 22, 2023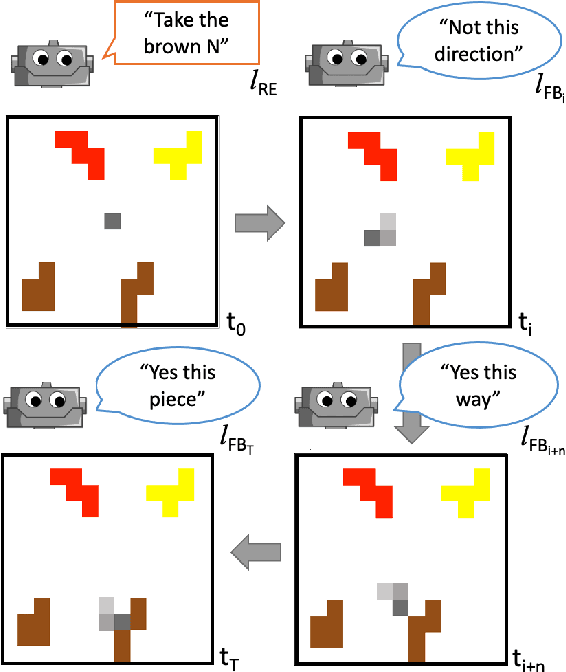
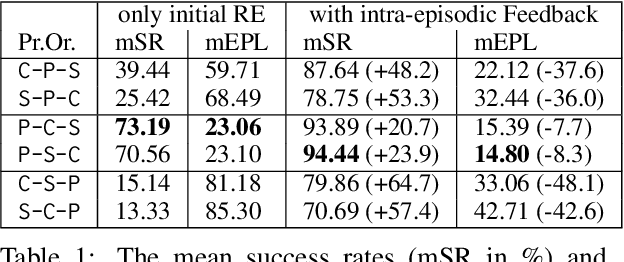
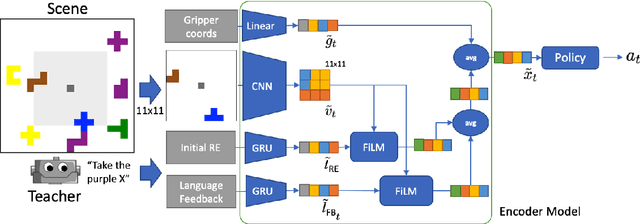
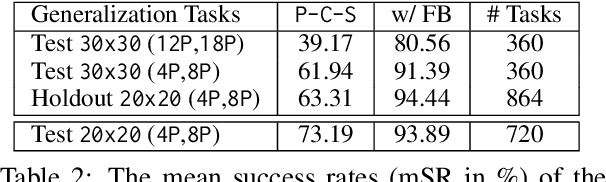
The ability to pick up on language signals in an ongoing interaction is crucial for future machine learning models to collaborate and interact with humans naturally. In this paper, we present an initial study that evaluates intra-episodic feedback given in a collaborative setting. We use a referential language game as a controllable example of a task-oriented collaborative joint activity. A teacher utters a referring expression generated by a well-known symbolic algorithm (the "Incremental Algorithm") as an initial instruction and then monitors the follower's actions to possibly intervene with intra-episodic feedback (which does not explicitly have to be requested). We frame this task as a reinforcement learning problem with sparse rewards and learn a follower policy for a heuristic teacher. Our results show that intra-episodic feedback allows the follower to generalize on aspects of scene complexity and performs better than providing only the initial statement.
Spatial Attention as an Interface for Image Captioning Models
Sep 29, 2020

The internal workings of modern deep learning models stay often unclear to an external observer, although spatial attention mechanisms are involved. The idea of this work is to translate these spatial attentions into natural language to provide a simpler access to the model's function. Thus, I took a neural image captioning model and measured the reactions to external modification in its spatial attention for three different interface methods: a fixation over the whole generation process, a fixation for the first time-steps and an addition to the generator's attention. The experimental results for bounding box based spatial attention vectors have shown that the captioning model reacts to method dependent changes in up to 52.65% and includes in 9.00% of the cases object categories, which were otherwise unmentioned. Afterwards, I established such a link to a hierarchical co-attention network for visual question answering by extraction of its word, phrase and question level spatial attentions. Here, generated captions for the word level included details of the question-answer pairs in up to 55.20% of the cases. This work indicates that spatial attention seen as an external interface for image caption generators is an useful method to access visual functions in natural language.
Can Neural Image Captioning be Controlled via Forced Attention?
Nov 10, 2019



Learned dynamic weighting of the conditioning signal (attention) has been shown to improve neural language generation in a variety of settings. The weights applied when generating a particular output sequence have also been viewed as providing a potentially explanatory insight into the internal workings of the generator. In this paper, we reverse the direction of this connection and ask whether through the control of the attention of the model we can control its output. Specifically, we take a standard neural image captioning model that uses attention, and fix the attention to pre-determined areas in the image. We evaluate whether the resulting output is more likely to mention the class of the object in that area than the normally generated caption. We introduce three effective methods to control the attention and find that these are producing expected results in up to 28.56% of the cases.