 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeclembench-2024: A Challenging, Dynamic, Complementary, Multilingual Benchmark and Underlying Flexible Framework for LLMs as Multi-Action Agents
May 31, 2024



It has been established in recent work that Large Language Models (LLMs) can be prompted to "self-play" conversational games that probe certain capabilities (general instruction following, strategic goal orientation, language understanding abilities), where the resulting interactive game play can be automatically scored. In this paper, we take one of the proposed frameworks for setting up such game-play environments, and further test its usefulness as an evaluation instrument, along a number of dimensions: We show that it can easily keep up with new developments while avoiding data contamination, we show that the tests implemented within it are not yet saturated (human performance is substantially higher than that of even the best models), and we show that it lends itself to investigating additional questions, such as the impact of the prompting language on performance. We believe that the approach forms a good basis for making decisions on model choice for building applied interactive systems, and perhaps ultimately setting up a closed-loop development environment of system and simulated evaluator.
It Couldn't Help But Overhear: On the Limits of Modelling Meta-Communicative Grounding Acts with Supervised Learning
May 02, 2024

Active participation in a conversation is key to building common ground, since understanding is jointly tailored by producers and recipients. Overhearers are deprived of the privilege of performing grounding acts and can only conjecture about intended meanings. Still, data generation and annotation, modelling, training and evaluation of NLP dialogue models place reliance on the overhearing paradigm. How much of the underlying grounding processes are thereby forfeited? As we show, there is evidence pointing to the impossibility of properly modelling human meta-communicative acts with data-driven learning models. In this paper, we discuss this issue and provide a preliminary analysis on the variability of human decisions for requesting clarification. Most importantly, we wish to bring this topic back to the community's table, encouraging discussion on the consequences of having models designed to only "listen in".
When Only Time Will Tell: Interpreting How Transformers Process Local Ambiguities Through the Lens of Restart-Incrementality
Feb 20, 2024



Incremental models that process sentences one token at a time will sometimes encounter points where more than one interpretation is possible. Causal models are forced to output one interpretation and continue, whereas models that can revise may edit their previous output as the ambiguity is resolved. In this work, we look at how restart-incremental Transformers build and update internal states, in an effort to shed light on what processes cause revisions not viable in autoregressive models. We propose an interpretable way to analyse the incremental states, showing that their sequential structure encodes information on the garden path effect and its resolution. Our method brings insights on various bidirectional encoders for contextualised meaning representation and dependency parsing, contributing to show their advantage over causal models when it comes to revisions.
Taking Action Towards Graceful Interaction: The Effects of Performing Actions on Modelling Policies for Instruction Clarification Requests
Jan 30, 2024
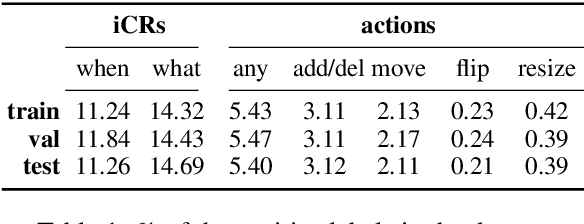
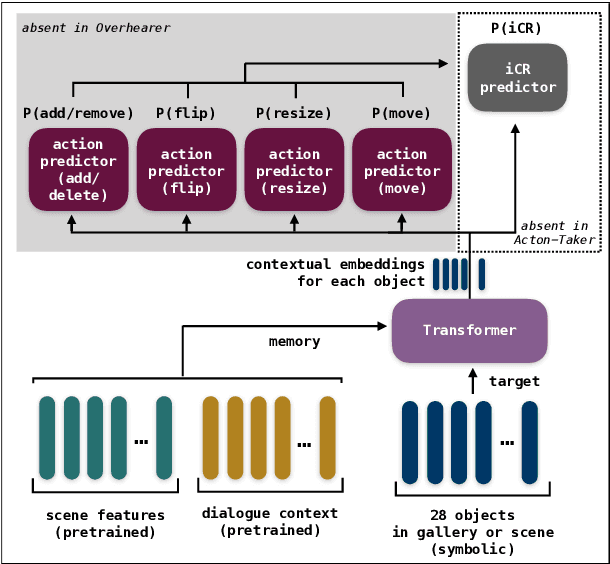
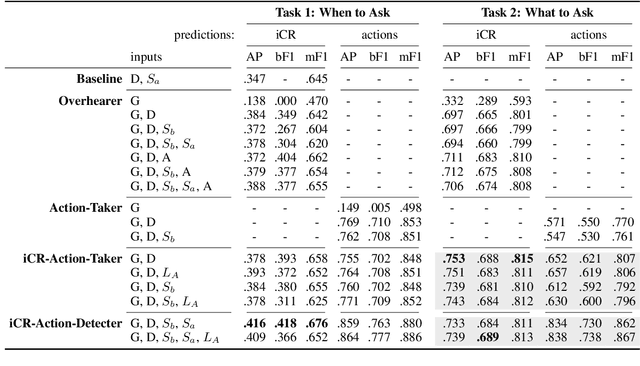
Clarification requests are a mechanism to help solve communication problems, e.g. due to ambiguity or underspecification, in instruction-following interactions. Despite their importance, even skilful models struggle with producing or interpreting such repair acts. In this work, we test three hypotheses concerning the effects of action taking as an auxiliary task in modelling iCR policies. Contrary to initial expectations, we conclude that its contribution to learning an iCR policy is limited, but some information can still be extracted from prediction uncertainty. We present further evidence that even well-motivated, Transformer-based models fail to learn good policies for when to ask Instruction CRs (iCRs), while the task of determining what to ask about can be more successfully modelled. Considering the implications of these findings, we further discuss the shortcomings of the data-driven paradigm for learning meta-communication acts.
Revising with a Backward Glance: Regressions and Skips during Reading as Cognitive Signals for Revision Policies in Incremental Processing
Oct 27, 2023



In NLP, incremental processors produce output in instalments, based on incoming prefixes of the linguistic input. Some tokens trigger revisions, causing edits to the output hypothesis, but little is known about why models revise when they revise. A policy that detects the time steps where revisions should happen can improve efficiency. Still, retrieving a suitable signal to train a revision policy is an open problem, since it is not naturally available in datasets. In this work, we investigate the appropriateness of regressions and skips in human reading eye-tracking data as signals to inform revision policies in incremental sequence labelling. Using generalised mixed-effects models, we find that the probability of regressions and skips by humans can potentially serve as useful predictors for revisions in BiLSTMs and Transformer models, with consistent results for various languages.
The Road to Quality is Paved with Good Revisions: A Detailed Evaluation Methodology for Revision Policies in Incremental Sequence Labelling
Jul 28, 2023Incremental dialogue model components produce a sequence of output prefixes based on incoming input. Mistakes can occur due to local ambiguities or to wrong hypotheses, making the ability to revise past outputs a desirable property that can be governed by a policy. In this work, we formalise and characterise edits and revisions in incremental sequence labelling and propose metrics to evaluate revision policies. We then apply our methodology to profile the incremental behaviour of three Transformer-based encoders in various tasks, paving the road for better revision policies.
"Are you telling me to put glasses on the dog?'' Content-Grounded Annotation of Instruction Clarification Requests in the CoDraw Dataset
Jun 04, 2023



Instruction Clarification Requests are a mechanism to solve communication problems, which is very functional in instruction-following interactions. Recent work has argued that the CoDraw dataset is a valuable source of naturally occurring iCRs. Beyond identifying when iCRs should be made, dialogue models should also be able to generate them with suitable form and content. In this work, we introduce CoDraw-iCR (v2), which extends the existing iCR identifiers fine-grained information grounded in the underlying dialogue game items and possible actions. Our annotation can serve to model and evaluate repair capabilities of dialogue agents.
clembench: Using Game Play to Evaluate Chat-Optimized Language Models as Conversational Agents
May 22, 2023
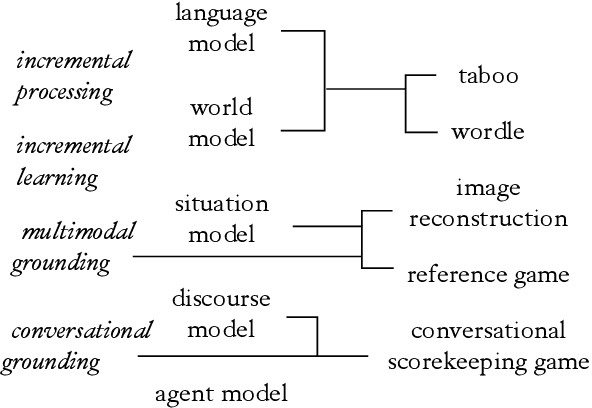
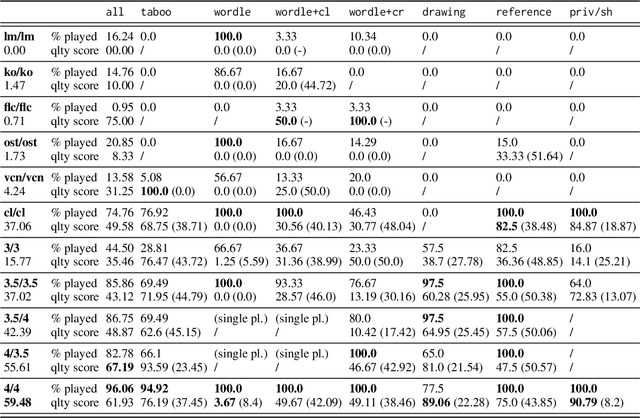
Recent work has proposed a methodology for the systematic evaluation of "Situated Language Understanding Agents"-agents that operate in rich linguistic and non-linguistic contexts-through testing them in carefully constructed interactive settings. Other recent work has argued that Large Language Models (LLMs), if suitably set up, can be understood as (simulators of) such agents. A connection suggests itself, which this paper explores: Can LLMs be evaluated meaningfully by exposing them to constrained game-like settings that are built to challenge specific capabilities? As a proof of concept, this paper investigates five interaction settings, showing that current chat-optimised LLMs are, to an extent, capable to follow game-play instructions. Both this capability and the quality of the game play, measured by how well the objectives of the different games are met, follows the development cycle, with newer models performing better. The metrics even for the comparatively simple example games are far from being saturated, suggesting that the proposed instrument will remain to have diagnostic value. Our general framework for implementing and evaluating games with LLMs is available at https://github.com/clp-research/clembench.
TAPIR: Learning Adaptive Revision for Incremental Natural Language Understanding with a Two-Pass Model
May 18, 2023



Language is by its very nature incremental in how it is produced and processed. This property can be exploited by NLP systems to produce fast responses, which has been shown to be beneficial for real-time interactive applications. Recent neural network-based approaches for incremental processing mainly use RNNs or Transformers. RNNs are fast but monotonic (cannot correct earlier output, which can be necessary in incremental processing). Transformers, on the other hand, consume whole sequences, and hence are by nature non-incremental. A restart-incremental interface that repeatedly passes longer input prefixes can be used to obtain partial outputs, while providing the ability to revise. However, this method becomes costly as the sentence grows longer. In this work, we propose the Two-pass model for AdaPtIve Revision (TAPIR) and introduce a method to obtain an incremental supervision signal for learning an adaptive revision policy. Experimental results on sequence labelling show that our model has better incremental performance and faster inference speed compared to restart-incremental Transformers, while showing little degradation on full sequences.
Instruction Clarification Requests in Multimodal Collaborative Dialogue Games: Tasks, and an Analysis of the CoDraw Dataset
Feb 28, 2023



In visual instruction-following dialogue games, players can engage in repair mechanisms in face of an ambiguous or underspecified instruction that cannot be fully mapped to actions in the world. In this work, we annotate Instruction Clarification Requests (iCRs) in CoDraw, an existing dataset of interactions in a multimodal collaborative dialogue game. We show that it contains lexically and semantically diverse iCRs being produced self-motivatedly by players deciding to clarify in order to solve the task successfully. With 8.8k iCRs found in 9.9k dialogues, CoDraw-iCR (v1) is a large spontaneous iCR corpus, making it a valuable resource for data-driven research on clarification in dialogue. We then formalise and provide baseline models for two tasks: Determining when to make an iCR and how to recognise them, in order to investigate to what extent these tasks are learnable from data.