 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttribution-guided Pruning for Compression, Circuit Discovery, and Targeted Correction in LLMs
Jun 16, 2025Large Language Models (LLMs) are central to many contemporary AI applications, yet their extensive parameter counts pose significant challenges for deployment in memory- and compute-constrained environments. Recent works in eXplainable AI (XAI), particularly on attribution methods, suggest that interpretability can also enable model compression by identifying and removing components irrelevant to inference. In this paper, we leverage Layer-wise Relevance Propagation (LRP) to perform attribution-guided pruning of LLMs. While LRP has shown promise in structured pruning for vision models, we extend it to unstructured pruning in LLMs and demonstrate that it can substantially reduce model size with minimal performance loss. Our method is especially effective in extracting task-relevant subgraphs -- so-called ``circuits'' -- which can represent core functions (e.g., indirect object identification). Building on this, we introduce a technique for model correction, by selectively removing circuits responsible for spurious behaviors (e.g., toxic outputs). All in all, we gather these techniques as a uniform holistic framework and showcase its effectiveness and limitations through extensive experiments for compression, circuit discovery and model correction on Llama and OPT models, highlighting its potential for improving both model efficiency and safety. Our code is publicly available at https://github.com/erfanhatefi/SparC3.
The Atlas of In-Context Learning: How Attention Heads Shape In-Context Retrieval Augmentation
May 21, 2025Large language models are able to exploit in-context learning to access external knowledge beyond their training data through retrieval-augmentation. While promising, its inner workings remain unclear. In this work, we shed light on the mechanism of in-context retrieval augmentation for question answering by viewing a prompt as a composition of informational components. We propose an attribution-based method to identify specialized attention heads, revealing in-context heads that comprehend instructions and retrieve relevant contextual information, and parametric heads that store entities' relational knowledge. To better understand their roles, we extract function vectors and modify their attention weights to show how they can influence the answer generation process. Finally, we leverage the gained insights to trace the sources of knowledge used during inference, paving the way towards more safe and transparent language models.
FADE: Why Bad Descriptions Happen to Good Features
Feb 24, 2025Recent advances in mechanistic interpretability have highlighted the potential of automating interpretability pipelines in analyzing the latent representations within LLMs. While they may enhance our understanding of internal mechanisms, the field lacks standardized evaluation methods for assessing the validity of discovered features. We attempt to bridge this gap by introducing FADE: Feature Alignment to Description Evaluation, a scalable model-agnostic framework for evaluating feature-description alignment. FADE evaluates alignment across four key metrics - Clarity, Responsiveness, Purity, and Faithfulness - and systematically quantifies the causes for the misalignment of feature and their description. We apply FADE to analyze existing open-source feature descriptions, and assess key components of automated interpretability pipelines, aiming to enhance the quality of descriptions. Our findings highlight fundamental challenges in generating feature descriptions, particularly for SAEs as compared to MLP neurons, providing insights into the limitations and future directions of automated interpretability. We release FADE as an open-source package at: https://github.com/brunibrun/FADE.
A Close Look at Decomposition-based XAI-Methods for Transformer Language Models
Feb 21, 2025Various XAI attribution methods have been recently proposed for the transformer architecture, allowing for insights into the decision-making process of large language models by assigning importance scores to input tokens and intermediate representations. One class of methods that seems very promising in this direction includes decomposition-based approaches, i.e., XAI-methods that redistribute the model's prediction logit through the network, as this value is directly related to the prediction. In the previous literature we note though that two prominent methods of this category, namely ALTI-Logit and LRP, have not yet been analyzed in juxtaposition and hence we propose to close this gap by conducting a careful quantitative evaluation w.r.t. ground truth annotations on a subject-verb agreement task, as well as various qualitative inspections, using BERT, GPT-2 and LLaMA-3 as a testbed. Along the way we compare and extend the ALTI-Logit and LRP methods, including the recently proposed AttnLRP variant, from an algorithmic and implementation perspective. We further incorporate in our benchmark two widely-used gradient-based attribution techniques. Finally, we make our carefullly constructed benchmark dataset for evaluating attributions on language models, as well as our code, publicly available in order to foster evaluation of XAI-methods on a well-defined common ground.
When Only Time Will Tell: Interpreting How Transformers Process Local Ambiguities Through the Lens of Restart-Incrementality
Feb 20, 2024



Incremental models that process sentences one token at a time will sometimes encounter points where more than one interpretation is possible. Causal models are forced to output one interpretation and continue, whereas models that can revise may edit their previous output as the ambiguity is resolved. In this work, we look at how restart-incremental Transformers build and update internal states, in an effort to shed light on what processes cause revisions not viable in autoregressive models. We propose an interpretable way to analyse the incremental states, showing that their sequential structure encodes information on the garden path effect and its resolution. Our method brings insights on various bidirectional encoders for contextualised meaning representation and dependency parsing, contributing to show their advantage over causal models when it comes to revisions.
The Road to Quality is Paved with Good Revisions: A Detailed Evaluation Methodology for Revision Policies in Incremental Sequence Labelling
Jul 28, 2023Incremental dialogue model components produce a sequence of output prefixes based on incoming input. Mistakes can occur due to local ambiguities or to wrong hypotheses, making the ability to revise past outputs a desirable property that can be governed by a policy. In this work, we formalise and characterise edits and revisions in incremental sequence labelling and propose metrics to evaluate revision policies. We then apply our methodology to profile the incremental behaviour of three Transformer-based encoders in various tasks, paving the road for better revision policies.
TAPIR: Learning Adaptive Revision for Incremental Natural Language Understanding with a Two-Pass Model
May 18, 2023



Language is by its very nature incremental in how it is produced and processed. This property can be exploited by NLP systems to produce fast responses, which has been shown to be beneficial for real-time interactive applications. Recent neural network-based approaches for incremental processing mainly use RNNs or Transformers. RNNs are fast but monotonic (cannot correct earlier output, which can be necessary in incremental processing). Transformers, on the other hand, consume whole sequences, and hence are by nature non-incremental. A restart-incremental interface that repeatedly passes longer input prefixes can be used to obtain partial outputs, while providing the ability to revise. However, this method becomes costly as the sentence grows longer. In this work, we propose the Two-pass model for AdaPtIve Revision (TAPIR) and introduce a method to obtain an incremental supervision signal for learning an adaptive revision policy. Experimental results on sequence labelling show that our model has better incremental performance and faster inference speed compared to restart-incremental Transformers, while showing little degradation on full sequences.
Towards Incremental Transformers: An Empirical Analysis of Transformer Models for Incremental NLU
Sep 15, 2021


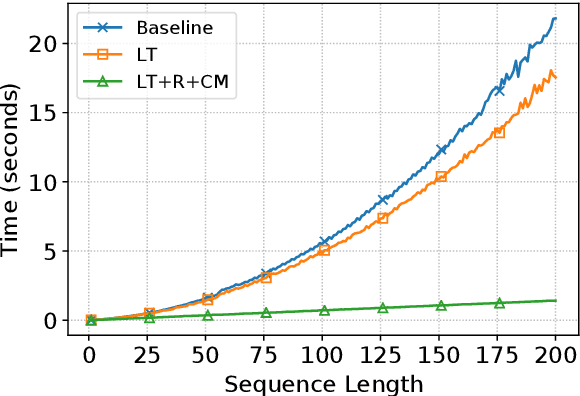
Incremental processing allows interactive systems to respond based on partial inputs, which is a desirable property e.g. in dialogue agents. The currently popular Transformer architecture inherently processes sequences as a whole, abstracting away the notion of time. Recent work attempts to apply Transformers incrementally via restart-incrementality by repeatedly feeding, to an unchanged model, increasingly longer input prefixes to produce partial outputs. However, this approach is computationally costly and does not scale efficiently for long sequences. In parallel, we witness efforts to make Transformers more efficient, e.g. the Linear Transformer (LT) with a recurrence mechanism. In this work, we examine the feasibility of LT for incremental NLU in English. Our results show that the recurrent LT model has better incremental performance and faster inference speed compared to the standard Transformer and LT with restart-incrementality, at the cost of part of the non-incremental (full sequence) quality. We show that the performance drop can be mitigated by training the model to wait for right context before committing to an output and that training with input prefixes is beneficial for delivering correct partial outputs.