 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcept-based explanations of Segmentation and Detection models in Natural Disaster Management
Mar 24, 2026Deep learning models for flood and wildfire segmentation and object detection enable precise, real-time disaster localization when deployed on embedded drone platforms. However, in natural disaster management, the lack of transparency in their decision-making process hinders human trust required for emergency response. To address this, we present an explainability framework for understanding flood segmentation and car detection predictions on the widely used PIDNet and YOLO architectures. More specifically, we introduce a novel redistribution strategy that extends Layer-wise Relevance Propagation (LRP) explanations for sigmoid-gated element-wise fusion layers. This extension allows LRP relevances to flow through the fusion modules of PIDNet, covering the entire computation graph back to the input image. Furthermore, we apply Prototypical Concept-based Explanations (PCX) to provide both local and global explanations at the concept level, revealing which learned features drive the segmentation and detection of specific disaster semantic classes. Experiments on a publicly available flood dataset show that our framework provides reliable and interpretable explanations while maintaining near real-time inference capabilities, rendering it suitable for deployment on resource-constrained platforms, such as Unmanned Aerial Vehicles (UAVs).
A Close Look at Decomposition-based XAI-Methods for Transformer Language Models
Feb 21, 2025Various XAI attribution methods have been recently proposed for the transformer architecture, allowing for insights into the decision-making process of large language models by assigning importance scores to input tokens and intermediate representations. One class of methods that seems very promising in this direction includes decomposition-based approaches, i.e., XAI-methods that redistribute the model's prediction logit through the network, as this value is directly related to the prediction. In the previous literature we note though that two prominent methods of this category, namely ALTI-Logit and LRP, have not yet been analyzed in juxtaposition and hence we propose to close this gap by conducting a careful quantitative evaluation w.r.t. ground truth annotations on a subject-verb agreement task, as well as various qualitative inspections, using BERT, GPT-2 and LLaMA-3 as a testbed. Along the way we compare and extend the ALTI-Logit and LRP methods, including the recently proposed AttnLRP variant, from an algorithmic and implementation perspective. We further incorporate in our benchmark two widely-used gradient-based attribution techniques. Finally, we make our carefullly constructed benchmark dataset for evaluating attributions on language models, as well as our code, publicly available in order to foster evaluation of XAI-methods on a well-defined common ground.
Towards Ground Truth Evaluation of Visual Explanations
Mar 16, 2020
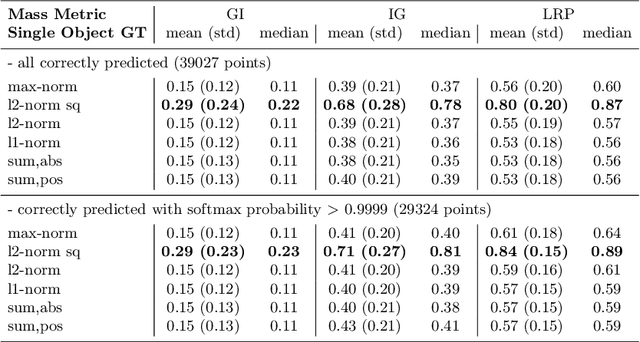
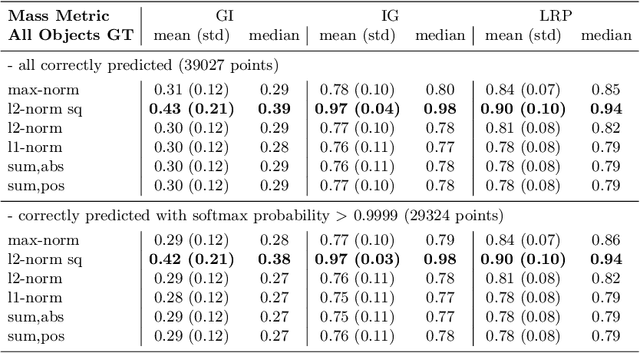
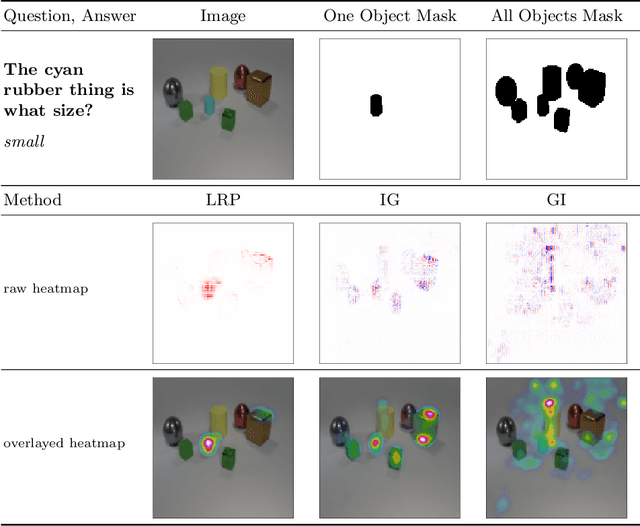
Several methods have been proposed to explain the decisions of neural networks in the visual domain via saliency heatmaps (aka relevances/feature importance scores). Thus far, these methods were mainly validated on real-world images, using either pixel perturbation experiments or bounding box localization accuracies. In the present work, we propose instead to evaluate explanations in a restricted and controlled setup using a synthetic dataset of rendered 3D shapes. To this end, we generate a CLEVR-alike visual question answering benchmark with around 40,000 questions, where the ground truth pixel coordinates of relevant objects are known, which allows us to validate explanations in a fair and transparent way. We further introduce two straightforward metrics to evaluate explanations in this setup, and compare their outcomes to standard pixel perturbation using a Relation Network model and three decomposition-based explanation methods: Gradient x Input, Integrated Gradients and Layer-wise Relevance Propagation. Among the tested methods, Layer-wise Relevance Propagation was shown to perform best, followed by Integrated Gradients. More generally, we expect the release of our dataset and code to support the development and comparison of methods on a well-defined common ground.
Explaining and Interpreting LSTMs
Sep 25, 2019

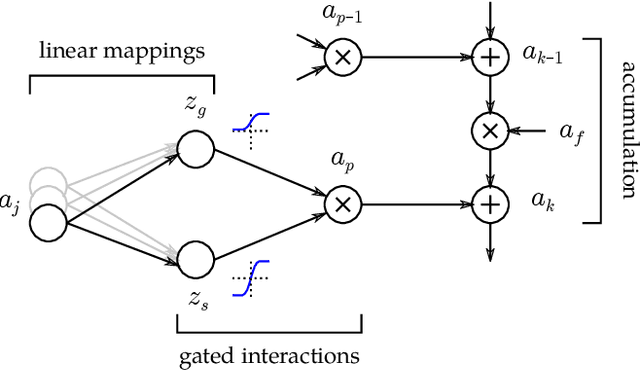
While neural networks have acted as a strong unifying force in the design of modern AI systems, the neural network architectures themselves remain highly heterogeneous due to the variety of tasks to be solved. In this chapter, we explore how to adapt the Layer-wise Relevance Propagation (LRP) technique used for explaining the predictions of feed-forward networks to the LSTM architecture used for sequential data modeling and forecasting. The special accumulators and gated interactions present in the LSTM require both a new propagation scheme and an extension of the underlying theoretical framework to deliver faithful explanations.
Evaluating Recurrent Neural Network Explanations
Jun 04, 2019
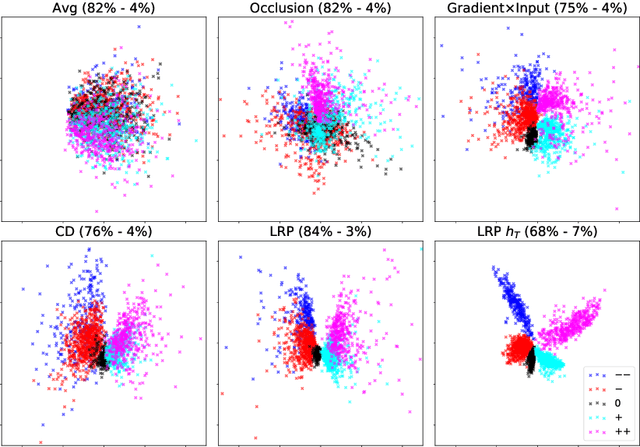
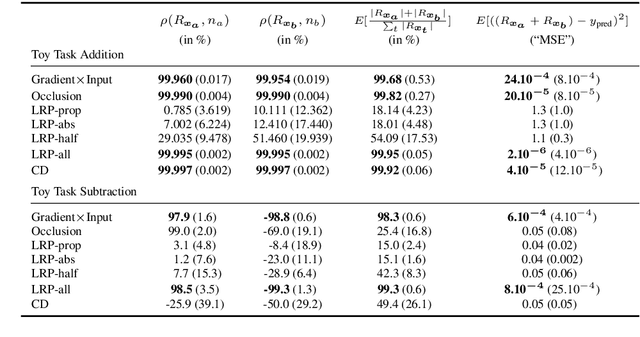

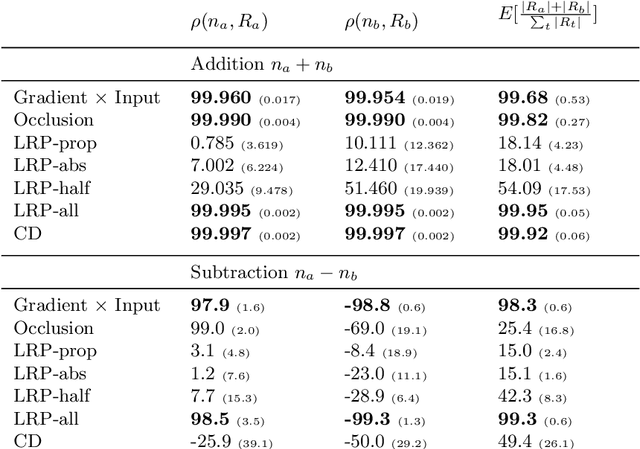
Recently, several methods have been proposed to explain the predictions of recurrent neural networks (RNNs), in particular of LSTMs. The goal of these methods is to understand the network's decisions by assigning to each input variable, e.g., a word, a relevance indicating to which extent it contributed to a particular prediction. In previous works, some of these methods were not yet compared to one another, or were evaluated only qualitatively. We close this gap by systematically and quantitatively comparing these methods in different settings, namely (1) a toy arithmetic task which we use as a sanity check, (2) a five-class sentiment prediction of movie reviews, and besides (3) we explore the usefulness of word relevances to build sentence-level representations. Lastly, using the method that performed best in our experiments, we show how specific linguistic phenomena such as the negation in sentiment analysis reflect in terms of relevance patterns, and how the relevance visualization can help to understand the misclassification of individual samples.
Explaining Recurrent Neural Network Predictions in Sentiment Analysis
Aug 04, 2017
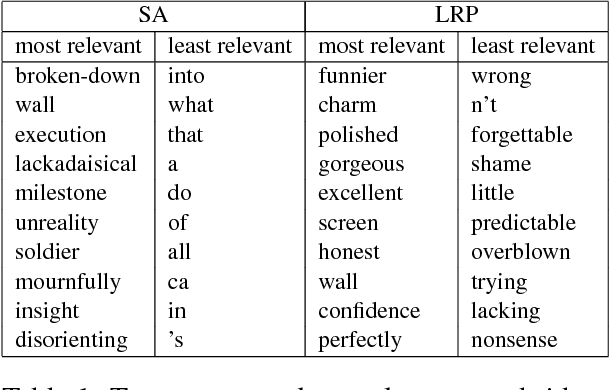

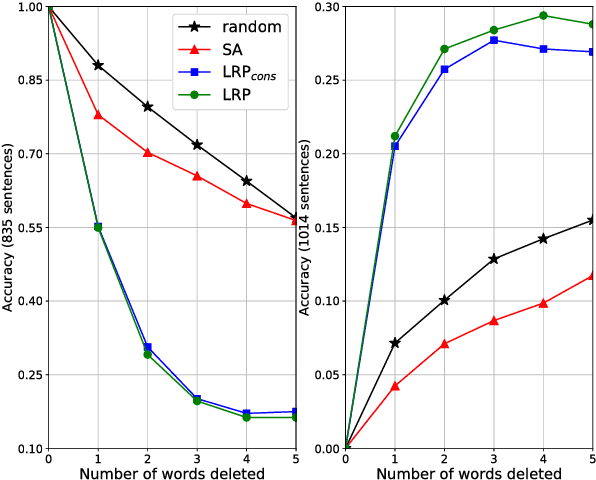
Recently, a technique called Layer-wise Relevance Propagation (LRP) was shown to deliver insightful explanations in the form of input space relevances for understanding feed-forward neural network classification decisions. In the present work, we extend the usage of LRP to recurrent neural networks. We propose a specific propagation rule applicable to multiplicative connections as they arise in recurrent network architectures such as LSTMs and GRUs. We apply our technique to a word-based bi-directional LSTM model on a five-class sentiment prediction task, and evaluate the resulting LRP relevances both qualitatively and quantitatively, obtaining better results than a gradient-based related method which was used in previous work.
Discovering topics in text datasets by visualizing relevant words
Jul 18, 2017

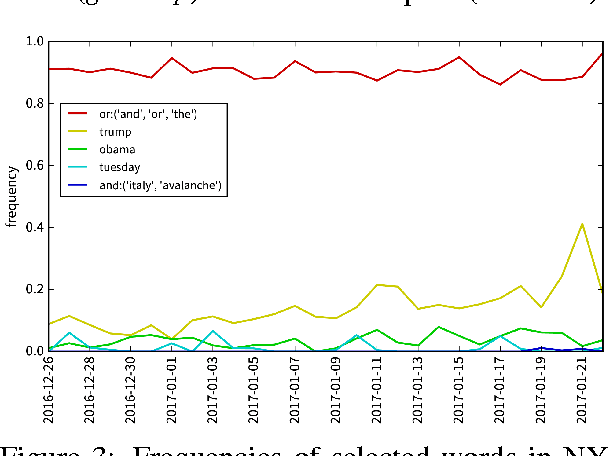

When dealing with large collections of documents, it is imperative to quickly get an overview of the texts' contents. In this paper we show how this can be achieved by using a clustering algorithm to identify topics in the dataset and then selecting and visualizing relevant words, which distinguish a group of documents from the rest of the texts, to summarize the contents of the documents belonging to each topic. We demonstrate our approach by discovering trending topics in a collection of New York Times article snippets.
Exploring text datasets by visualizing relevant words
Jul 17, 2017
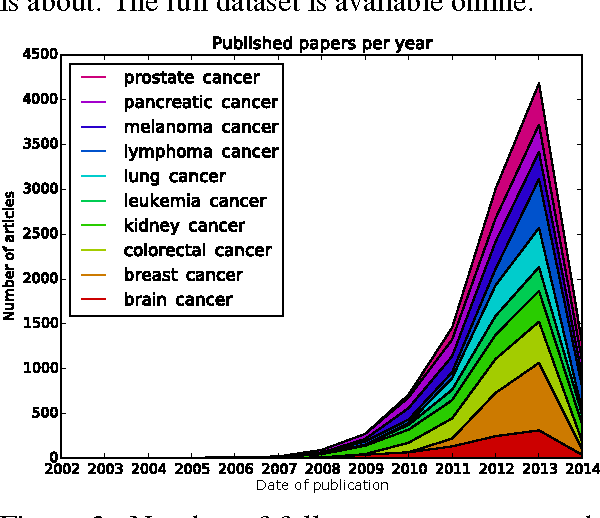
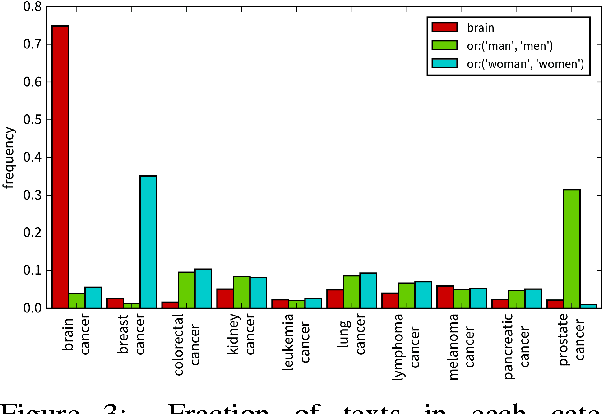
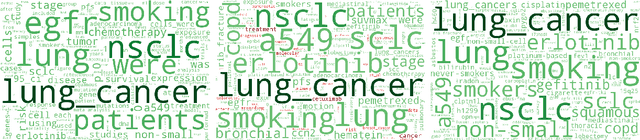
When working with a new dataset, it is important to first explore and familiarize oneself with it, before applying any advanced machine learning algorithms. However, to the best of our knowledge, no tools exist that quickly and reliably give insight into the contents of a selection of documents with respect to what distinguishes them from other documents belonging to different categories. In this paper we propose to extract `relevant words' from a collection of texts, which summarize the contents of documents belonging to a certain class (or discovered cluster in the case of unlabeled datasets), and visualize them in word clouds to allow for a survey of salient features at a glance. We compare three methods for extracting relevant words and demonstrate the usefulness of the resulting word clouds by providing an overview of the classes contained in a dataset of scientific publications as well as by discovering trending topics from recent New York Times article snippets.
"What is Relevant in a Text Document?": An Interpretable Machine Learning Approach
Dec 23, 2016


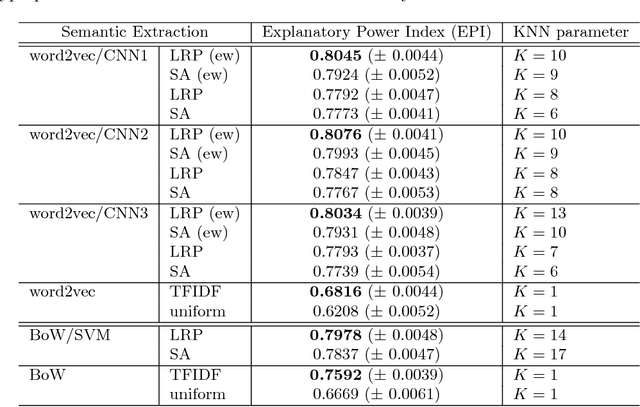
Text documents can be described by a number of abstract concepts such as semantic category, writing style, or sentiment. Machine learning (ML) models have been trained to automatically map documents to these abstract concepts, allowing to annotate very large text collections, more than could be processed by a human in a lifetime. Besides predicting the text's category very accurately, it is also highly desirable to understand how and why the categorization process takes place. In this paper, we demonstrate that such understanding can be achieved by tracing the classification decision back to individual words using layer-wise relevance propagation (LRP), a recently developed technique for explaining predictions of complex non-linear classifiers. We train two word-based ML models, a convolutional neural network (CNN) and a bag-of-words SVM classifier, on a topic categorization task and adapt the LRP method to decompose the predictions of these models onto words. Resulting scores indicate how much individual words contribute to the overall classification decision. This enables one to distill relevant information from text documents without an explicit semantic information extraction step. We further use the word-wise relevance scores for generating novel vector-based document representations which capture semantic information. Based on these document vectors, we introduce a measure of model explanatory power and show that, although the SVM and CNN models perform similarly in terms of classification accuracy, the latter exhibits a higher level of explainability which makes it more comprehensible for humans and potentially more useful for other applications.
Explaining Predictions of Non-Linear Classifiers in NLP
Jun 23, 2016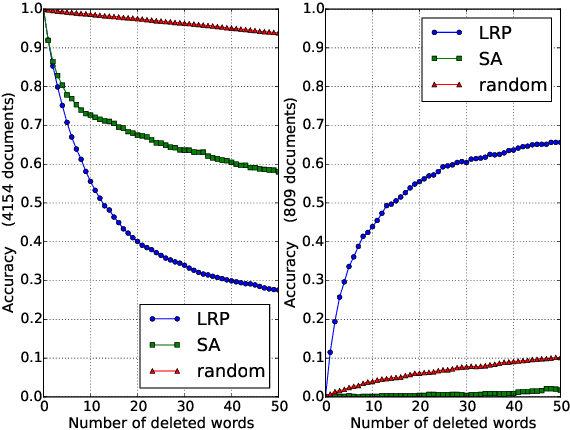

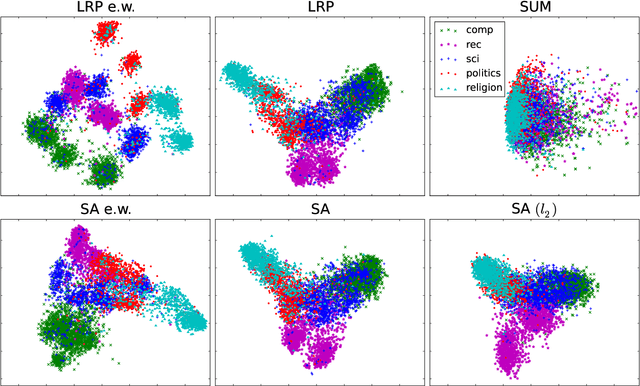
Layer-wise relevance propagation (LRP) is a recently proposed technique for explaining predictions of complex non-linear classifiers in terms of input variables. In this paper, we apply LRP for the first time to natural language processing (NLP). More precisely, we use it to explain the predictions of a convolutional neural network (CNN) trained on a topic categorization task. Our analysis highlights which words are relevant for a specific prediction of the CNN. We compare our technique to standard sensitivity analysis, both qualitatively and quantitatively, using a "word deleting" perturbation experiment, a PCA analysis, and various visualizations. All experiments validate the suitability of LRP for explaining the CNN predictions, which is also in line with results reported in recent image classification studies.