 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Ground Truth Evaluation of Visual Explanations
Paper and Code

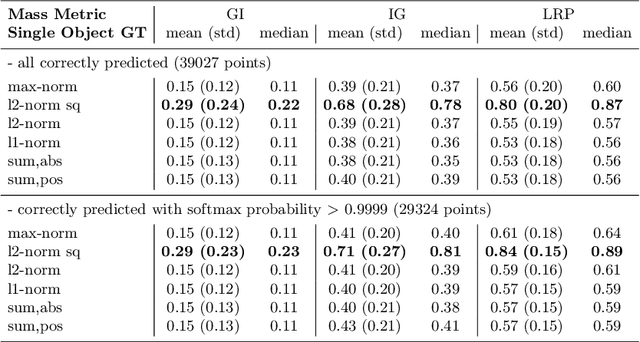
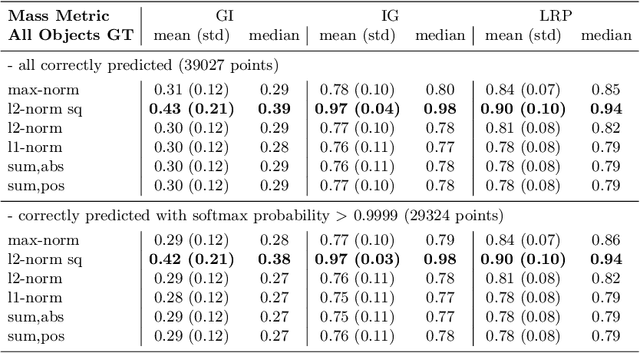
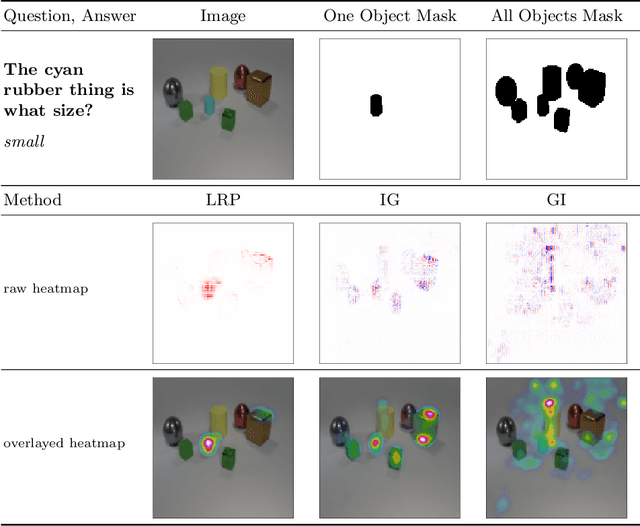
Several methods have been proposed to explain the decisions of neural networks in the visual domain via saliency heatmaps (aka relevances/feature importance scores). Thus far, these methods were mainly validated on real-world images, using either pixel perturbation experiments or bounding box localization accuracies. In the present work, we propose instead to evaluate explanations in a restricted and controlled setup using a synthetic dataset of rendered 3D shapes. To this end, we generate a CLEVR-alike visual question answering benchmark with around 40,000 questions, where the ground truth pixel coordinates of relevant objects are known, which allows us to validate explanations in a fair and transparent way. We further introduce two straightforward metrics to evaluate explanations in this setup, and compare their outcomes to standard pixel perturbation using a Relation Network model and three decomposition-based explanation methods: Gradient x Input, Integrated Gradients and Layer-wise Relevance Propagation. Among the tested methods, Layer-wise Relevance Propagation was shown to perform best, followed by Integrated Gradients. More generally, we expect the release of our dataset and code to support the development and comparison of methods on a well-defined common ground.