 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Generative Adversarial Networks for Optical Property Mapping using Synthetic Image Data
Mar 15, 2022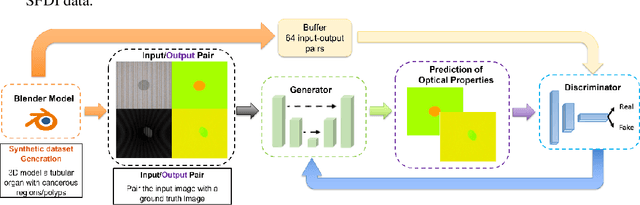

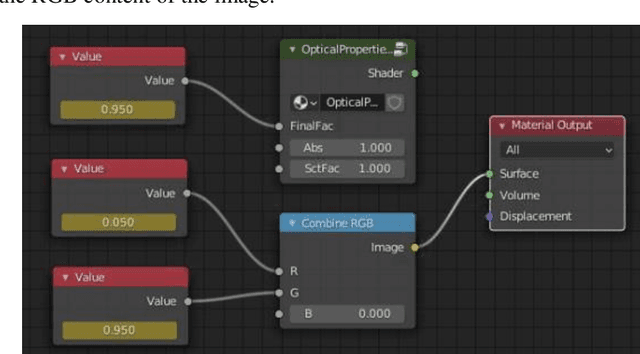
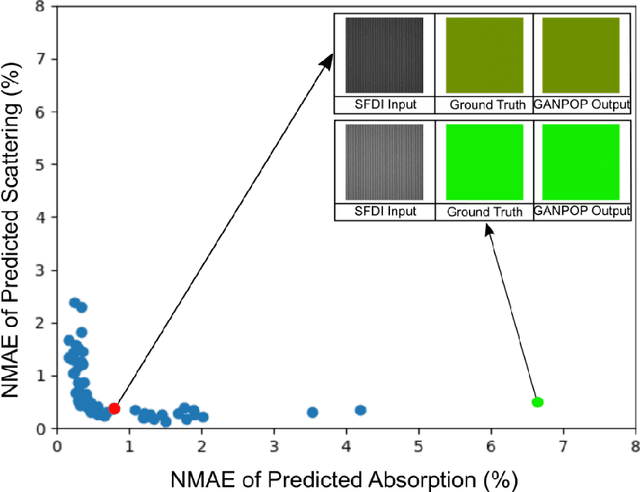
We demonstrate training of a Generative Adversarial Network (GAN) for prediction of optical property maps (scattering and absorption) using spatial frequency domain imaging (SFDI) image data sets generated synthetically with free open-source 3D modelling and rendering software, Blender. The flexibility of Blender is exploited to simulate 3 models with real-life relevance to clinical SFDI of diseased tissue: flat samples, flat samples with spheroidal tumours and cylindrical samples with spheroidal tumours representing imaging inside a tubular organ e.g. the gastro-intestinal tract. In all 3 scenarios we show the GAN provides accurate reconstruction of optical properties from single SFDI images with mean normalised error ranging from 1-1.2% for absorption and 0.7-1.2% for scattering, resulting in visually improved contrast for tumour spheroid structures. This compares favourably with 25% absorption error and 10% scattering error achieved using GANs on experimental SFDI data. However, some of this improvement is due to lower noise and availability of perfect ground truths so we therefore cross-validate our synthetically-trained GAN with a GAN trained on experimental data and observe visually accurate results with error of <40% for absorption and <25% for scattering, due largely to the presence of spatial frequency mismatch artefacts. Our synthetically trained GAN is therefore highly relevant to real experimental samples, but provides significant added benefits of large training datasets, perfect ground-truths and the ability to test realistic imaging geometries, e.g. inside cylinders, for which no conventional single-shot demodulation algorithms exist. In future we expect that application of techniques such as domain adaptation or training on hybrid real-synthetic datasets will create a powerful tool for fast, accurate production of optical property maps from real clinical imaging systems.
Towards Ground Truth Evaluation of Visual Explanations
Mar 16, 2020
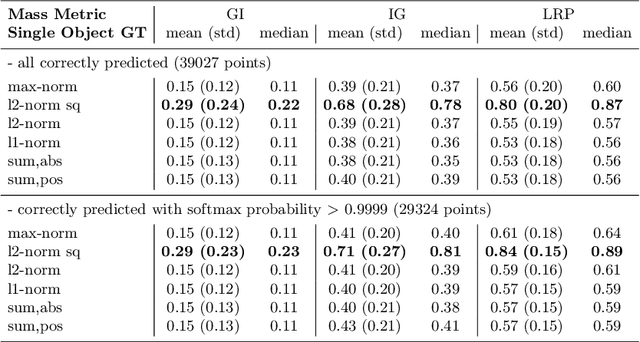
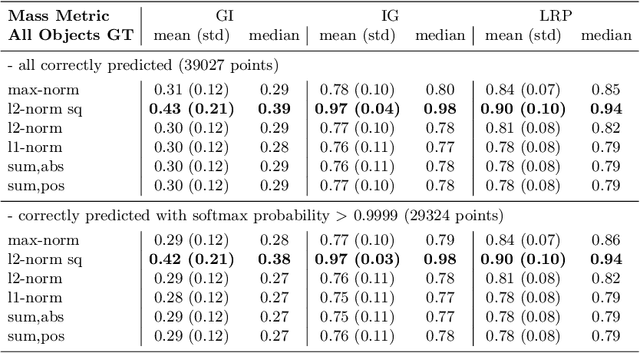
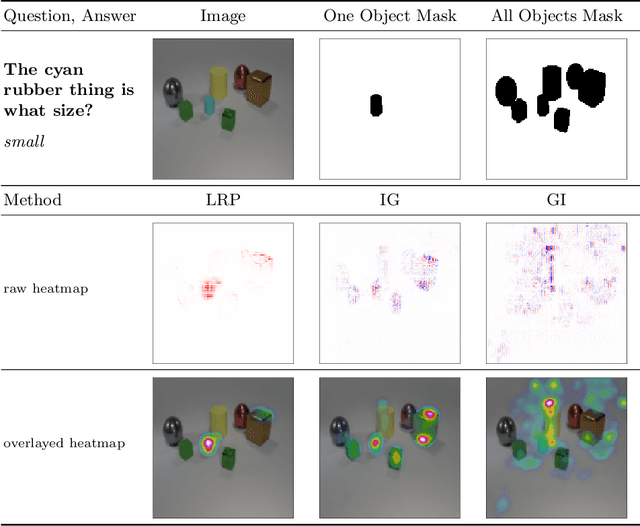
Several methods have been proposed to explain the decisions of neural networks in the visual domain via saliency heatmaps (aka relevances/feature importance scores). Thus far, these methods were mainly validated on real-world images, using either pixel perturbation experiments or bounding box localization accuracies. In the present work, we propose instead to evaluate explanations in a restricted and controlled setup using a synthetic dataset of rendered 3D shapes. To this end, we generate a CLEVR-alike visual question answering benchmark with around 40,000 questions, where the ground truth pixel coordinates of relevant objects are known, which allows us to validate explanations in a fair and transparent way. We further introduce two straightforward metrics to evaluate explanations in this setup, and compare their outcomes to standard pixel perturbation using a Relation Network model and three decomposition-based explanation methods: Gradient x Input, Integrated Gradients and Layer-wise Relevance Propagation. Among the tested methods, Layer-wise Relevance Propagation was shown to perform best, followed by Integrated Gradients. More generally, we expect the release of our dataset and code to support the development and comparison of methods on a well-defined common ground.
DeepCABAC: A Universal Compression Algorithm for Deep Neural Networks
Jul 27, 2019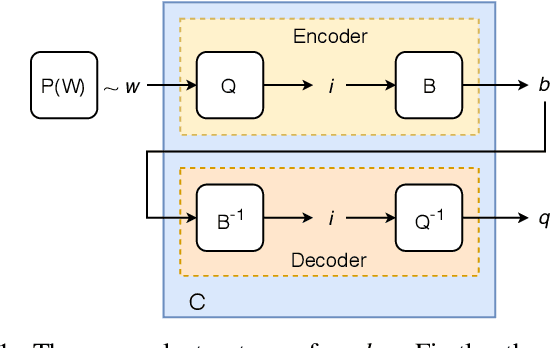
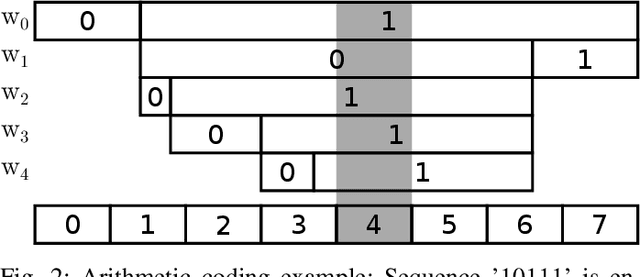
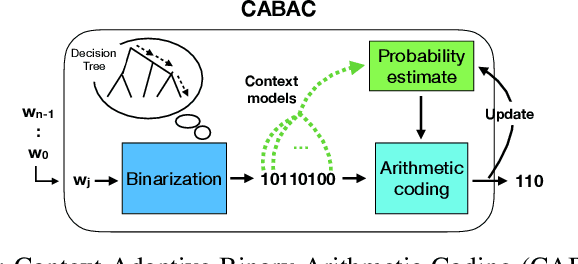
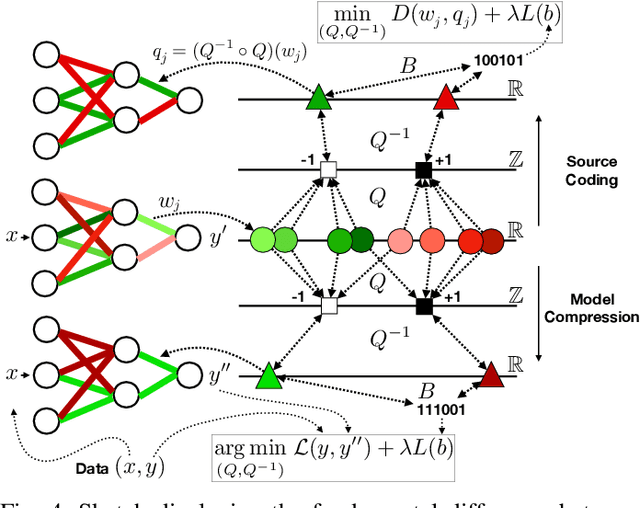
The field of video compression has developed some of the most sophisticated and efficient compression algorithms known in the literature, enabling very high compressibility for little loss of information. Whilst some of these techniques are domain specific, many of their underlying principles are universal in that they can be adapted and applied for compressing different types of data. In this work we present DeepCABAC, a compression algorithm for deep neural networks that is based on one of the state-of-the-art video coding techniques. Concretely, it applies a Context-based Adaptive Binary Arithmetic Coder (CABAC) to the network's parameters, which was originally designed for the H.264/AVC video coding standard and became the state-of-the-art for lossless compression. Moreover, DeepCABAC employs a novel quantization scheme that minimizes the rate-distortion function while simultaneously taking the impact of quantization onto the accuracy of the network into account. Experimental results show that DeepCABAC consistently attains higher compression rates than previously proposed coding techniques for neural network compression. For instance, it is able to compress the VGG16 ImageNet model by x63.6 with no loss of accuracy, thus being able to represent the entire network with merely 8.7MB. The source code for encoding and decoding can be found at https://github.com/fraunhoferhhi/DeepCABAC.
Evaluating Recurrent Neural Network Explanations
Jun 04, 2019
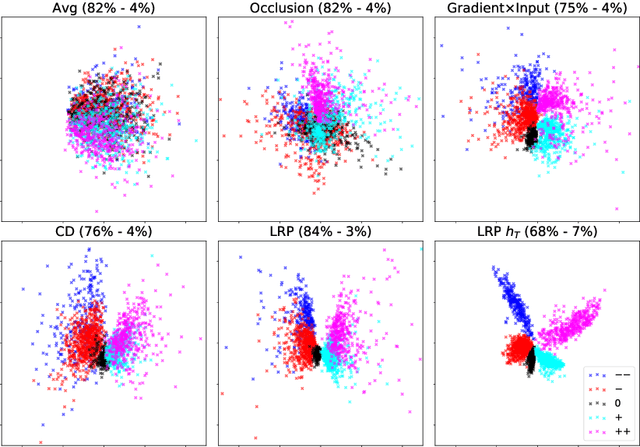
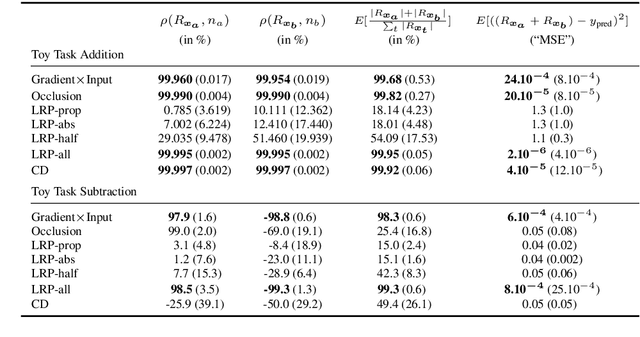

Recently, several methods have been proposed to explain the predictions of recurrent neural networks (RNNs), in particular of LSTMs. The goal of these methods is to understand the network's decisions by assigning to each input variable, e.g., a word, a relevance indicating to which extent it contributed to a particular prediction. In previous works, some of these methods were not yet compared to one another, or were evaluated only qualitatively. We close this gap by systematically and quantitatively comparing these methods in different settings, namely (1) a toy arithmetic task which we use as a sanity check, (2) a five-class sentiment prediction of movie reviews, and besides (3) we explore the usefulness of word relevances to build sentence-level representations. Lastly, using the method that performed best in our experiments, we show how specific linguistic phenomena such as the negation in sentiment analysis reflect in terms of relevance patterns, and how the relevance visualization can help to understand the misclassification of individual samples.
DeepCABAC: Context-adaptive binary arithmetic coding for deep neural network compression
May 15, 2019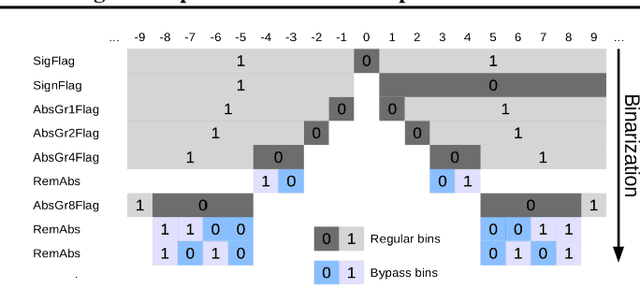
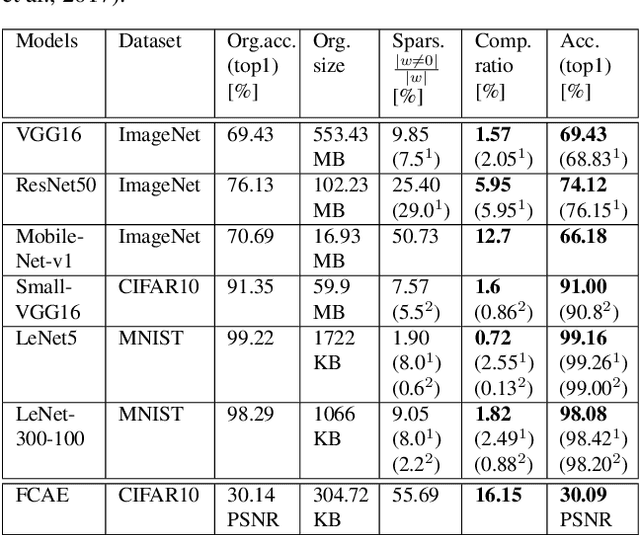
We present DeepCABAC, a novel context-adaptive binary arithmetic coder for compressing deep neural networks. It quantizes each weight parameter by minimizing a weighted rate-distortion function, which implicitly takes the impact of quantization on to the accuracy of the network into account. Subsequently, it compresses the quantized values into a bitstream representation with minimal redundancies. We show that DeepCABAC is able to reach very high compression ratios across a wide set of different network architectures and datasets. For instance, we are able to compress by x63.6 the VGG16 ImageNet model with no loss of accuracy, thus being able to represent the entire network with merely 8.7MB.
Dual Recurrent Attention Units for Visual Question Answering
Feb 01, 2018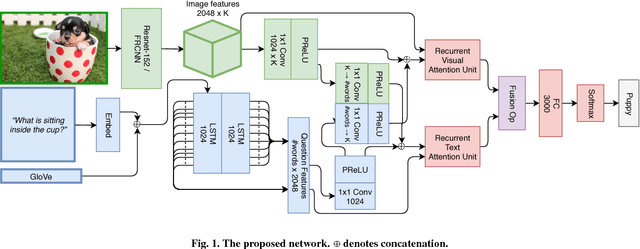
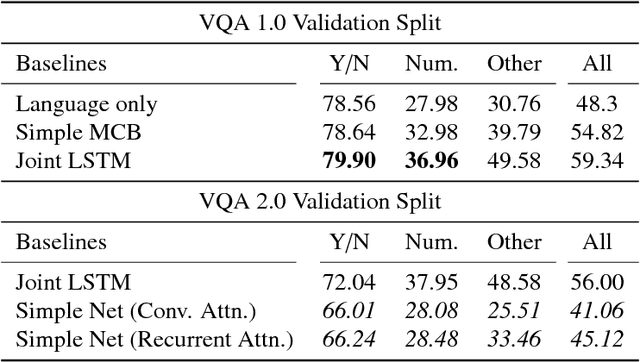
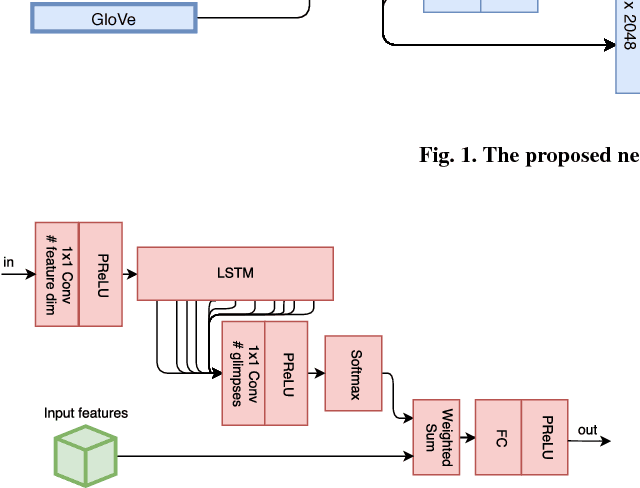
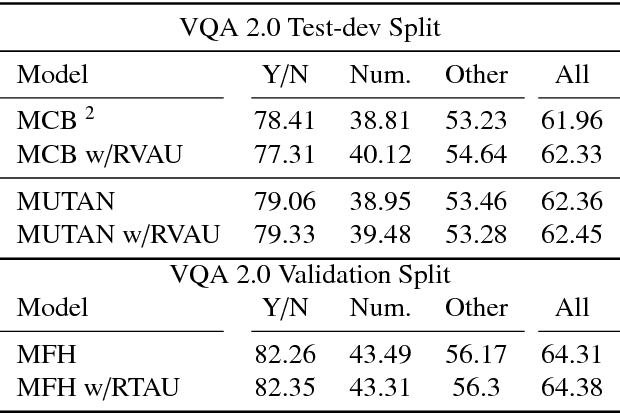
We propose an architecture for VQA which utilizes recurrent layers to generate visual and textual attention. The memory characteristic of the proposed recurrent attention units offers a rich joint embedding of visual and textual features and enables the model to reason relations between several parts of the image and question. Our single model outperforms the first place winner on the VQA 1.0 dataset, performs within margin to the current state-of-the-art ensemble model. We also experiment with replacing attention mechanisms in other state-of-the-art models with our implementation and show increased accuracy. In both cases, our recurrent attention mechanism improves performance in tasks requiring sequential or relational reasoning on the VQA dataset.
CloudCV: Large Scale Distributed Computer Vision as a Cloud Service
Feb 13, 2017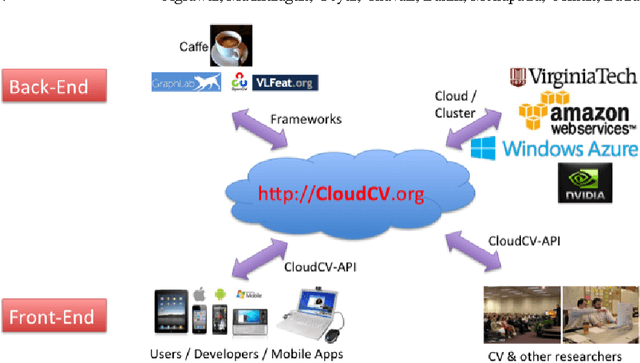
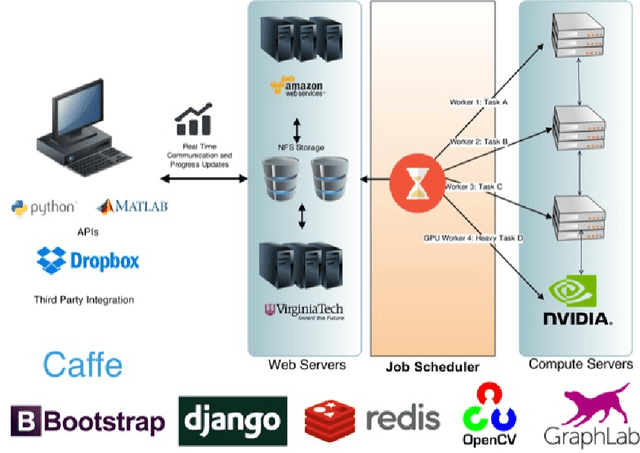
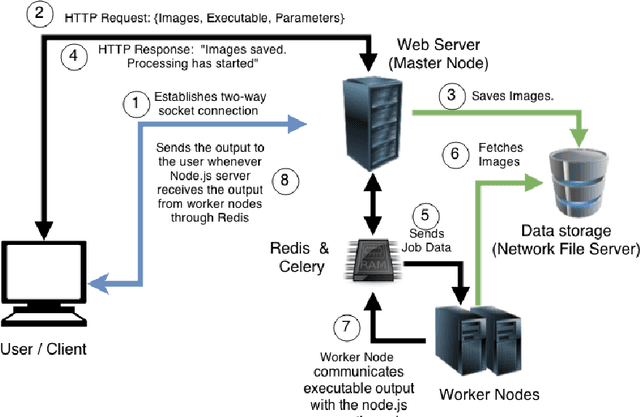
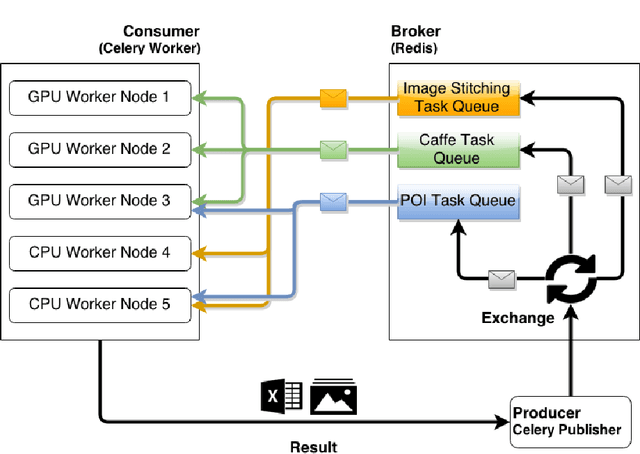
We are witnessing a proliferation of massive visual data. Unfortunately scaling existing computer vision algorithms to large datasets leaves researchers repeatedly solving the same algorithmic, logistical, and infrastructural problems. Our goal is to democratize computer vision; one should not have to be a computer vision, big data and distributed computing expert to have access to state-of-the-art distributed computer vision algorithms. We present CloudCV, a comprehensive system to provide access to state-of-the-art distributed computer vision algorithms as a cloud service through a Web Interface and APIs.