 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Classical Data to Quantum Advantage -- Quantum Policy Evaluation on Quantum Hardware
Sep 09, 2025Quantum policy evaluation (QPE) is a reinforcement learning (RL) algorithm which is quadratically more efficient than an analogous classical Monte Carlo estimation. It makes use of a direct quantum mechanical realization of a finite Markov decision process, in which the agent and the environment are modeled by unitary operators and exchange states, actions, and rewards in superposition. Previously, the quantum environment has been implemented and parametrized manually for an illustrative benchmark using a quantum simulator. In this paper, we demonstrate how these environment parameters can be learned from a batch of classical observational data through quantum machine learning (QML) on quantum hardware. The learned quantum environment is then applied in QPE to also compute policy evaluations on quantum hardware. Our experiments reveal that, despite challenges such as noise and short coherence times, the integration of QML and QPE shows promising potential for achieving quantum advantage in RL.
A Deep Learning Method for Simultaneous Denoising and Missing Wedge Reconstruction in Cryogenic Electron Tomography
Nov 09, 2023Cryogenic electron tomography (cryo-ET) is a technique for imaging biological samples such as viruses, cells, and proteins in 3D. A microscope collects a series of 2D projections of the sample, and the goal is to reconstruct the 3D density of the sample called the tomogram. This is difficult as the 2D projections have a missing wedge of information and are noisy. Tomograms reconstructed with conventional methods, such as filtered back-projection, suffer from the noise, and from artifacts and anisotropic resolution due to the missing wedge of information. To improve the visual quality and resolution of such tomograms, we propose a deep-learning approach for simultaneous denoising and missing wedge reconstruction called DeepDeWedge. DeepDeWedge is based on fitting a neural network to the 2D projections with a self-supervised loss inspired by noise2noise-like methods. The algorithm requires no training or ground truth data. Experiments on synthetic and real cryo-ET data show that DeepDeWedge achieves competitive performance for deep learning-based denoising and missing wedge reconstruction of cryo-ET tomograms.
Quantum Policy Iteration via Amplitude Estimation and Grover Search -- Towards Quantum Advantage for Reinforcement Learning
Jun 09, 2022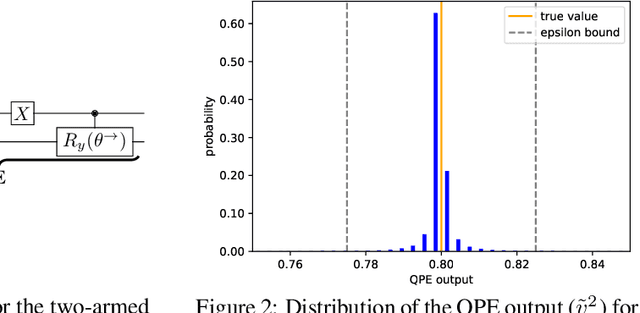
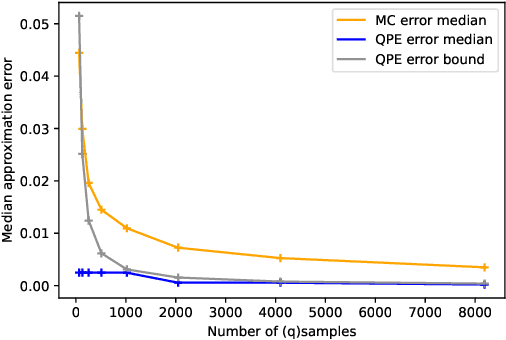
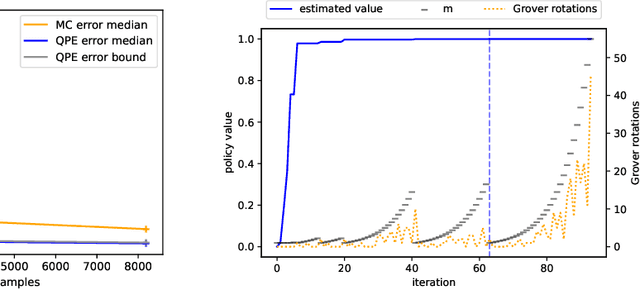
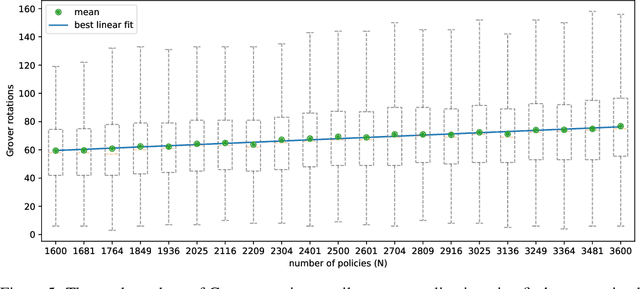
We present a full implementation and simulation of a novel quantum reinforcement learning (RL) method and mathematically prove a quantum advantage. Our approach shows in detail how to combine amplitude estimation and Grover search into a policy evaluation and improvement scheme. We first develop quantum policy evaluation (QPE) which is quadratically more efficient compared to an analogous classical Monte Carlo estimation and is based on a quantum mechanical realization of a finite Markov decision process (MDP). Building on QPE, we derive a quantum policy iteration that repeatedly improves an initial policy using Grover search until the optimum is reached. Finally, we present an implementation of our algorithm for a two-armed bandit MDP which we then simulate. The results confirm that QPE provides a quantum advantage in RL problems.
FantastIC4: A Hardware-Software Co-Design Approach for Efficiently Running 4bit-Compact Multilayer Perceptrons
Dec 17, 2020


With the growing demand for deploying deep learning models to the "edge", it is paramount to develop techniques that allow to execute state-of-the-art models within very tight and limited resource constraints. In this work we propose a software-hardware optimization paradigm for obtaining a highly efficient execution engine of deep neural networks (DNNs) that are based on fully-connected layers. Our approach is centred around compression as a means for reducing the area as well as power requirements of, concretely, multilayer perceptrons (MLPs) with high predictive performances. Firstly, we design a novel hardware architecture named FantastIC4, which (1) supports the efficient on-chip execution of multiple compact representations of fully-connected layers and (2) minimizes the required number of multipliers for inference down to only 4 (thus the name). Moreover, in order to make the models amenable for efficient execution on FantastIC4, we introduce a novel entropy-constrained training method that renders them to be robust to 4bit quantization and highly compressible in size simultaneously. The experimental results show that we can achieve throughputs of 2.45 TOPS with a total power consumption of 3.6W on a Virtual Ultrascale FPGA XCVU440 device implementation, and achieve a total power efficiency of 20.17 TOPS/W on a 22nm process ASIC version. When compared to the other state-of-the-art accelerators designed for the Google Speech Command (GSC) dataset, FantastIC4 is better by 51$\times$ in terms of throughput and 145$\times$ in terms of area efficiency (GOPS/W).
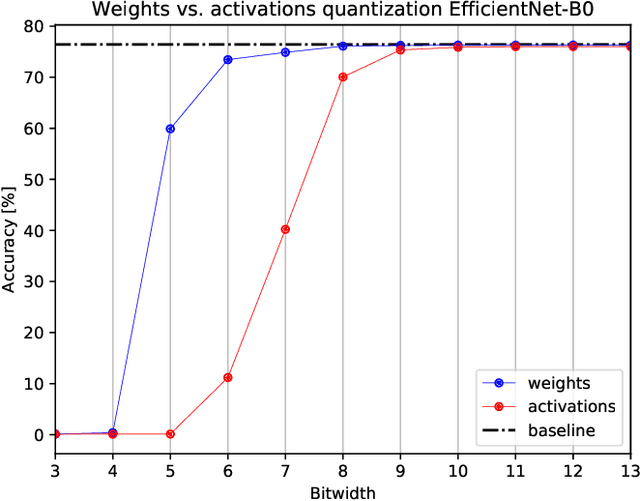
Dithered backprop: A sparse and quantized backpropagation algorithm for more efficient deep neural network training
Apr 16, 2020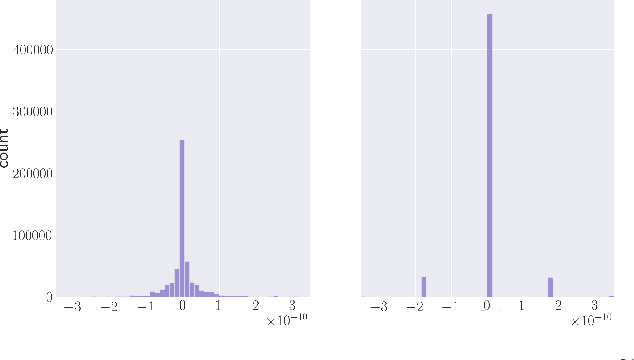
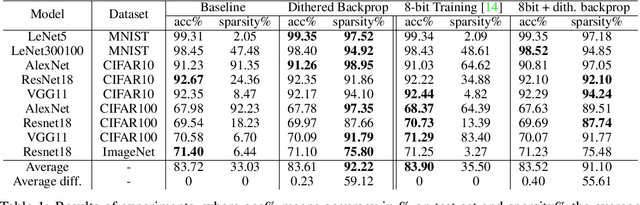
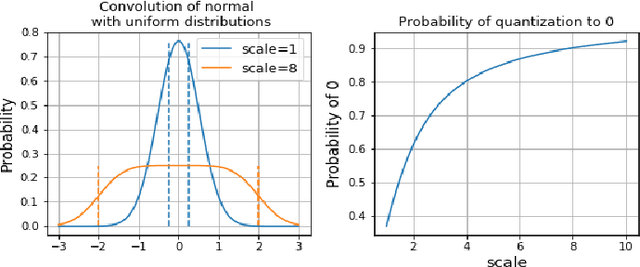
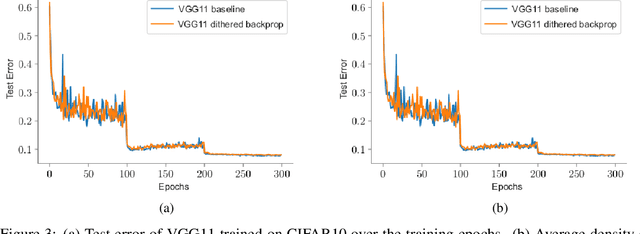
Deep Neural Networks are successful but highly computationally expensive learning systems. One of the main sources of time and energy drains is the well known backpropagation (backprop) algorithm, which roughly accounts for 2/3 of the computational complexity of training. In this work we propose a method for reducing the computational cost of backprop, which we named dithered backprop. It consists in applying a stochastic quantization scheme to intermediate results of the method. The particular quantisation scheme, called non-subtractive dither (NSD), induces sparsity which can be exploited by computing efficient sparse matrix multiplications. Experiments on popular image classification tasks show that it induces 92% sparsity on average across a wide set of models at no or negligible accuracy drop in comparison to state-of-the-art approaches, thus significantly reducing the computational complexity of the backward pass. Moreover, we show that our method is fully compatible to state-of-the-art training methods that reduce the bit-precision of training down to 8-bits, as such being able to further reduce the computational requirements. Finally we discuss and show potential benefits of applying dithered backprop in a distributed training setting, where both communication as well as compute efficiency may increase simultaneously with the number of participant nodes.
Learning Sparse & Ternary Neural Networks with Entropy-Constrained Trained Ternarization (EC2T)
Apr 02, 2020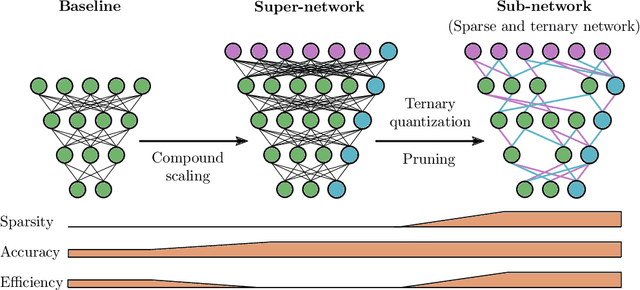
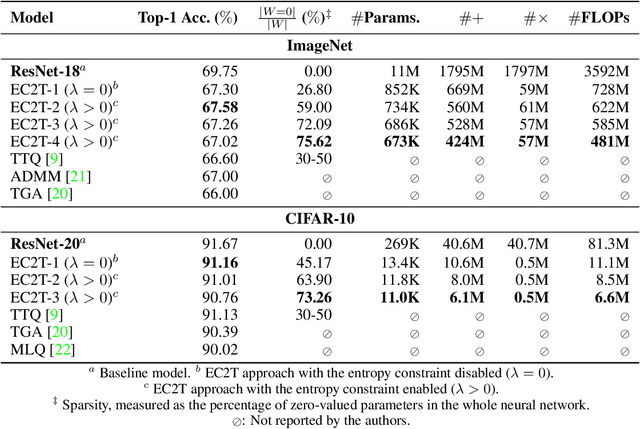
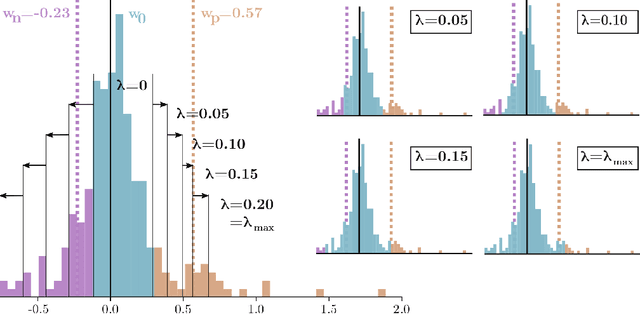
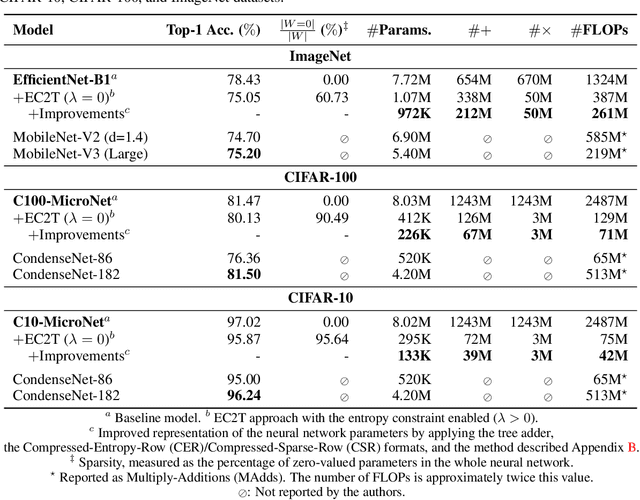
Deep neural networks (DNN) have shown remarkable success in a variety of machine learning applications. The capacity of these models (i.e., number of parameters), endows them with expressive power and allows them to reach the desired performance. In recent years, there is an increasing interest in deploying DNNs to resource-constrained devices (i.e., mobile devices) with limited energy, memory, and computational budget. To address this problem, we propose Entropy-Constrained Trained Ternarization (EC2T), a general framework to create sparse and ternary neural networks which are efficient in terms of storage (e.g., at most two binary-masks and two full-precision values are required to save a weight matrix) and computation (e.g., MAC operations are reduced to a few accumulations plus two multiplications). This approach consists of two steps. First, a super-network is created by scaling the dimensions of a pre-trained model (i.e., its width and depth). Subsequently, this super-network is simultaneously pruned (using an entropy constraint) and quantized (that is, ternary values are assigned layer-wise) in a training process, resulting in a sparse and ternary network representation. We validate the proposed approach in CIFAR-10, CIFAR-100, and ImageNet datasets, showing its effectiveness in image classification tasks.
Pruning by Explaining: A Novel Criterion for Deep Neural Network Pruning
Dec 18, 2019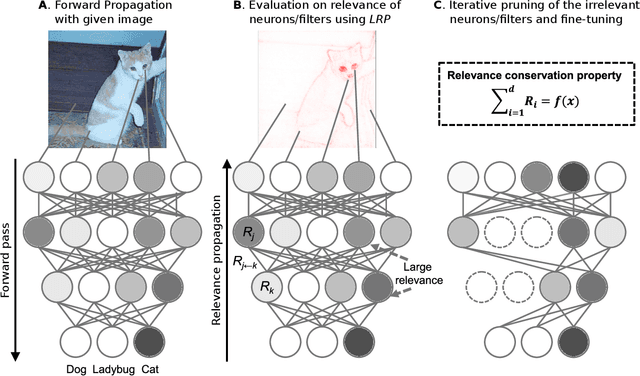
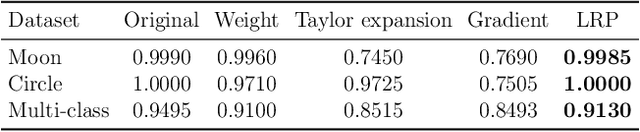
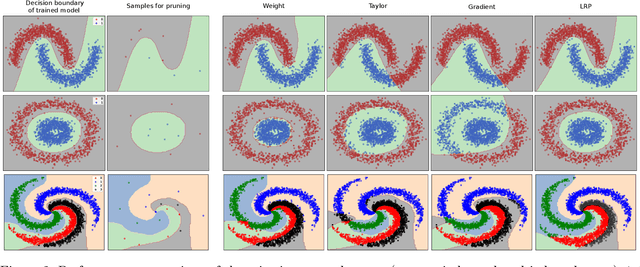
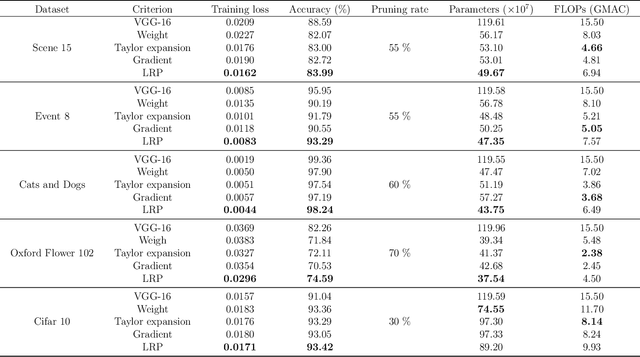
The success of convolutional neural networks (CNNs) in various applications is accompanied by a significant increase in computation and parameter storage costs. Recent efforts to reduce these overheads involve pruning and compressing the weights of various layers while at the same time aiming to not sacrifice performance. In this paper, we propose a novel criterion for CNN pruning inspired by neural network interpretability: The most relevant elements, i.e. weights or filters, are automatically found using their relevance score in the sense of explainable AI (XAI). By that we for the first time link the two disconnected lines of interpretability and model compression research. We show in particular that our proposed method can efficiently prune transfer-learned CNN models where networks pre-trained on large corpora are adapted to specialized tasks. To this end, the method is evaluated on a broad range of computer vision datasets. Notably, our novel criterion is not only competitive or better compared to state-of-the-art pruning criteria when successive retraining is performed, but clearly outperforms these previous criteria in the common application setting where the data of the task to be transferred to are very scarce and no retraining is possible. Our method can iteratively compress the model while maintaining or even improving accuracy. At the same time, it has a computational cost in the order of gradient computation and is comparatively simple to apply without the need for tuning hyperparameters for pruning.
DeepCABAC: A Universal Compression Algorithm for Deep Neural Networks
Jul 27, 2019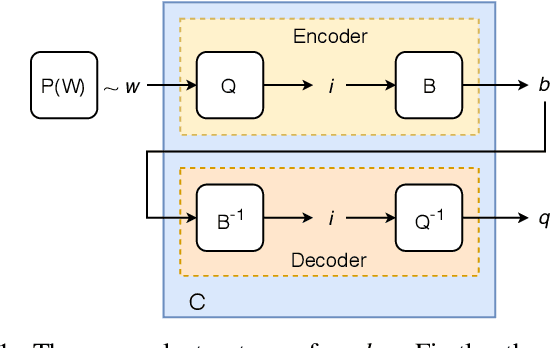
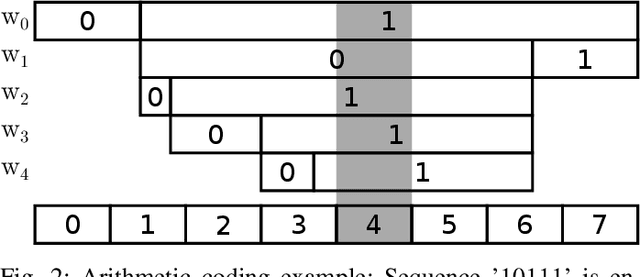
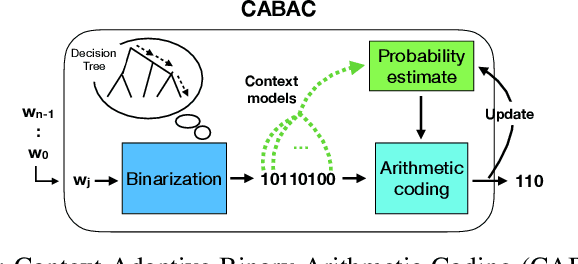
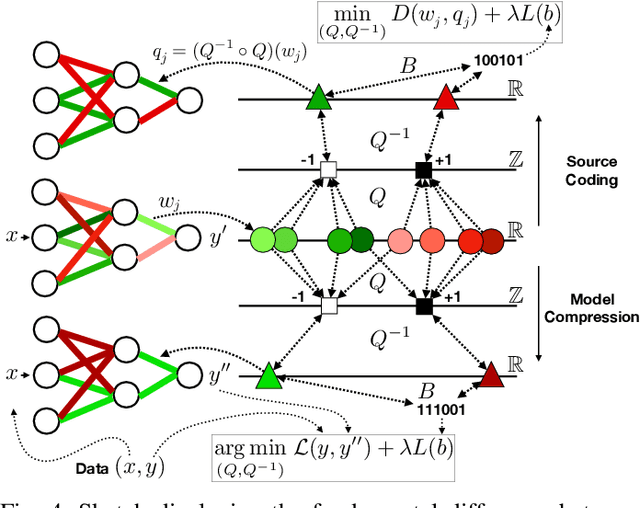
The field of video compression has developed some of the most sophisticated and efficient compression algorithms known in the literature, enabling very high compressibility for little loss of information. Whilst some of these techniques are domain specific, many of their underlying principles are universal in that they can be adapted and applied for compressing different types of data. In this work we present DeepCABAC, a compression algorithm for deep neural networks that is based on one of the state-of-the-art video coding techniques. Concretely, it applies a Context-based Adaptive Binary Arithmetic Coder (CABAC) to the network's parameters, which was originally designed for the H.264/AVC video coding standard and became the state-of-the-art for lossless compression. Moreover, DeepCABAC employs a novel quantization scheme that minimizes the rate-distortion function while simultaneously taking the impact of quantization onto the accuracy of the network into account. Experimental results show that DeepCABAC consistently attains higher compression rates than previously proposed coding techniques for neural network compression. For instance, it is able to compress the VGG16 ImageNet model by x63.6 with no loss of accuracy, thus being able to represent the entire network with merely 8.7MB. The source code for encoding and decoding can be found at https://github.com/fraunhoferhhi/DeepCABAC.
DeepCABAC: Context-adaptive binary arithmetic coding for deep neural network compression
May 15, 2019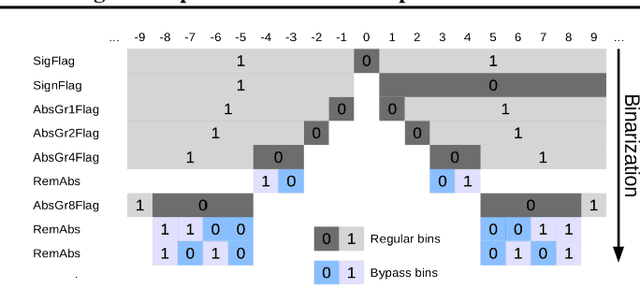
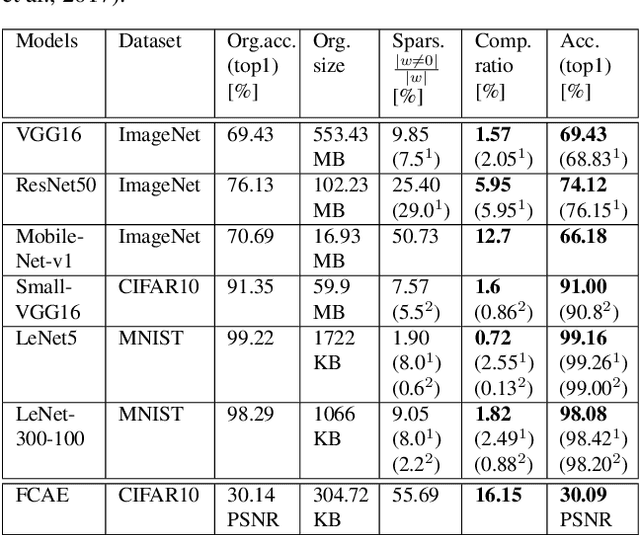
We present DeepCABAC, a novel context-adaptive binary arithmetic coder for compressing deep neural networks. It quantizes each weight parameter by minimizing a weighted rate-distortion function, which implicitly takes the impact of quantization on to the accuracy of the network into account. Subsequently, it compresses the quantized values into a bitstream representation with minimal redundancies. We show that DeepCABAC is able to reach very high compression ratios across a wide set of different network architectures and datasets. For instance, we are able to compress by x63.6 the VGG16 ImageNet model with no loss of accuracy, thus being able to represent the entire network with merely 8.7MB.
Robust and Communication-Efficient Federated Learning from Non-IID Data
Mar 07, 2019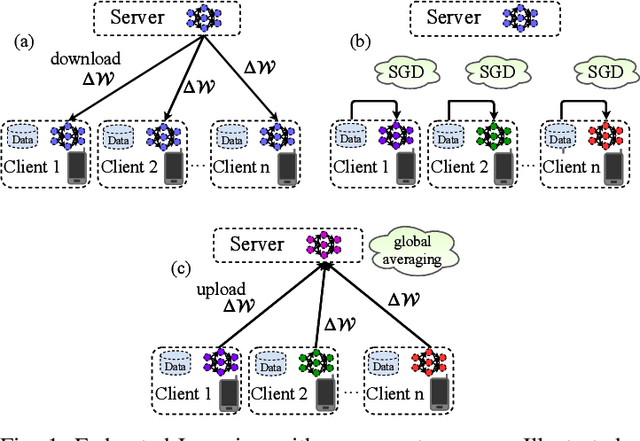
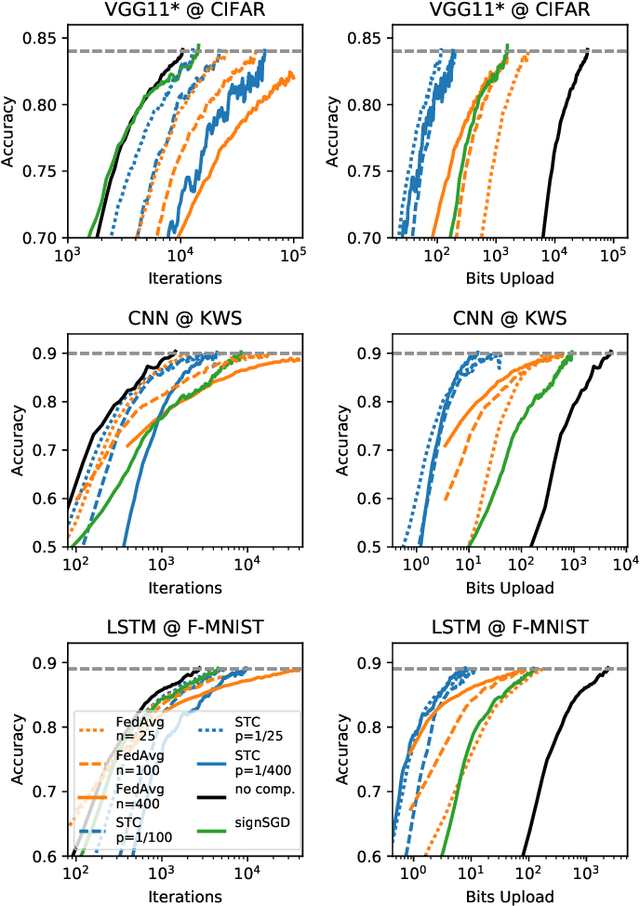
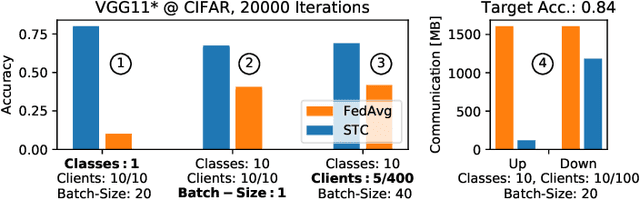
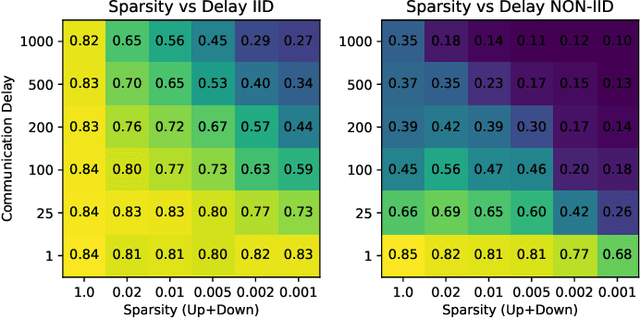
Federated Learning allows multiple parties to jointly train a deep learning model on their combined data, without any of the participants having to reveal their local data to a centralized server. This form of privacy-preserving collaborative learning however comes at the cost of a significant communication overhead during training. To address this problem, several compression methods have been proposed in the distributed training literature that can reduce the amount of required communication by up to three orders of magnitude. These existing methods however are only of limited utility in the Federated Learning setting, as they either only compress the upstream communication from the clients to the server (leaving the downstream communication uncompressed) or only perform well under idealized conditions such as iid distribution of the client data, which typically can not be found in Federated Learning. In this work, we propose Sparse Ternary Compression (STC), a new compression framework that is specifically designed to meet the requirements of the Federated Learning environment. Our experiments on four different learning tasks demonstrate that STC distinctively outperforms Federated Averaging in common Federated Learning scenarios where clients either a) hold non-iid data, b) use small batch sizes during training, or where c) the number of clients is large and the participation rate in every communication round is low. We furthermore show that even if the clients hold iid data and use medium sized batches for training, STC still behaves pareto-superior to Federated Averaging in the sense that it achieves fixed target accuracies on our benchmarks within both fewer training iterations and a smaller communication budget.