 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniForm: A Reuse Attention Mechanism Optimized for Efficient Vision Transformers on Edge Devices
Dec 03, 2024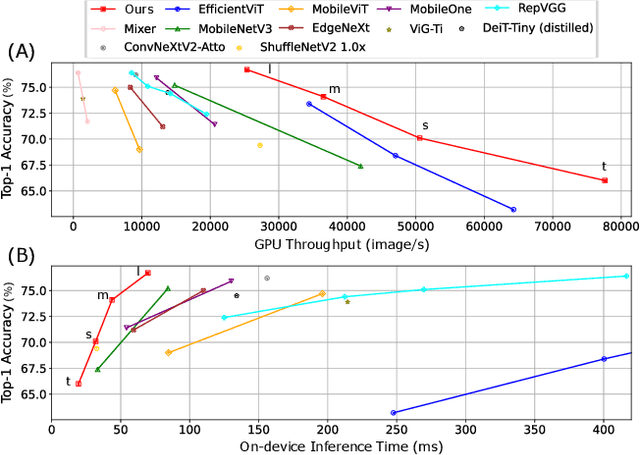

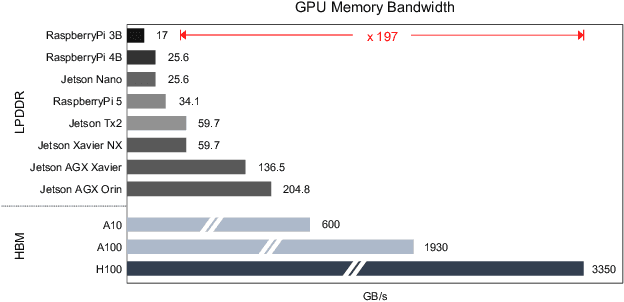
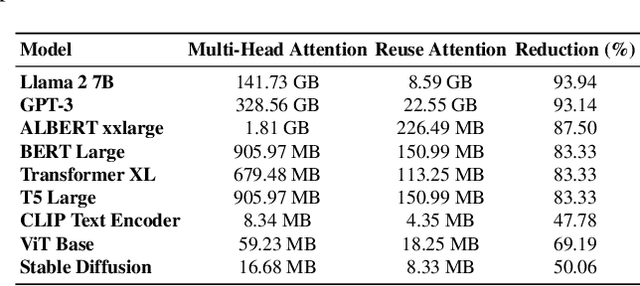
Transformer-based architectures have demonstrated remarkable success across various domains, but their deployment on edge devices remains challenging due to high memory and computational demands. In this paper, we introduce a novel Reuse Attention mechanism, tailored for efficient memory access and computational optimization, enabling seamless operation on resource-constrained platforms without compromising performance. Unlike traditional multi-head attention (MHA), which redundantly computes separate attention matrices for each head, Reuse Attention consolidates these computations into a shared attention matrix, significantly reducing memory overhead and computational complexity. Comprehensive experiments on ImageNet-1K and downstream tasks show that the proposed UniForm models leveraging Reuse Attention achieve state-of-the-art imagenet classification accuracy while outperforming existing attention mechanisms, such as Linear Attention and Flash Attention, in inference speed and memory scalability. Notably, UniForm-l achieves a 76.7% Top-1 accuracy on ImageNet-1K with 21.8ms inference time on edge devices like the Jetson AGX Orin, representing up to a 5x speedup over competing benchmark methods. These results demonstrate the versatility of Reuse Attention across high-performance GPUs and edge platforms, paving the way for broader real-time applications
U-MixFormer: UNet-like Transformer with Mix-Attention for Efficient Semantic Segmentation
Dec 11, 2023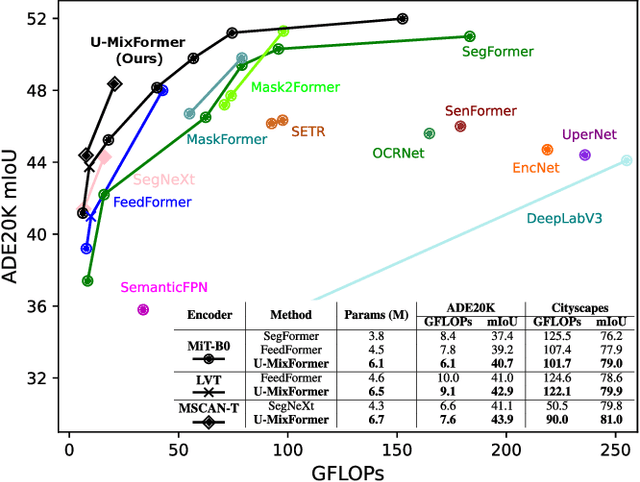
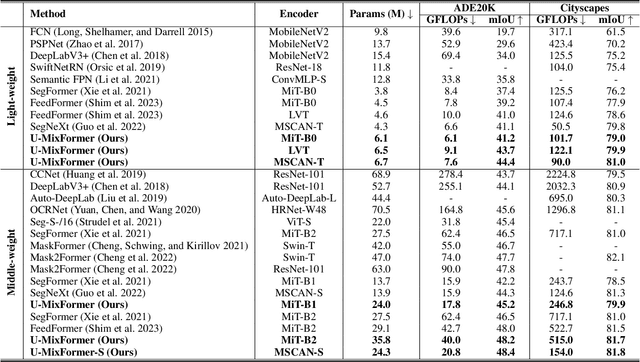
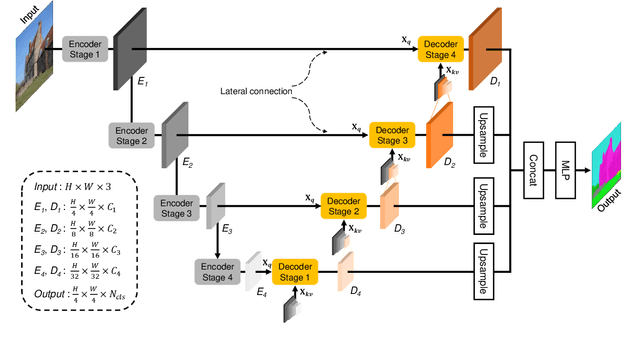

Semantic segmentation has witnessed remarkable advancements with the adaptation of the Transformer architecture. Parallel to the strides made by the Transformer, CNN-based U-Net has seen significant progress, especially in high-resolution medical imaging and remote sensing. This dual success inspired us to merge the strengths of both, leading to the inception of a U-Net-based vision transformer decoder tailored for efficient contextual encoding. Here, we propose a novel transformer decoder, U-MixFormer, built upon the U-Net structure, designed for efficient semantic segmentation. Our approach distinguishes itself from the previous transformer methods by leveraging lateral connections between the encoder and decoder stages as feature queries for the attention modules, apart from the traditional reliance on skip connections. Moreover, we innovatively mix hierarchical feature maps from various encoder and decoder stages to form a unified representation for keys and values, giving rise to our unique mix-attention module. Our approach demonstrates state-of-the-art performance across various configurations. Extensive experiments show that U-MixFormer outperforms SegFormer, FeedFormer, and SegNeXt by a large margin. For example, U-MixFormer-B0 surpasses SegFormer-B0 and FeedFormer-B0 with 3.8% and 2.0% higher mIoU and 27.3% and 21.8% less computation and outperforms SegNext with 3.3% higher mIoU with MSCAN-T encoder on ADE20K. Code available at https://github.com/julian-klitzing/u-mixformer.
Automatic Neural Network Pruning that Efficiently Preserves the Model Accuracy
Nov 18, 2021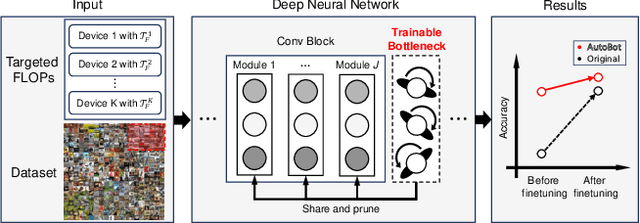
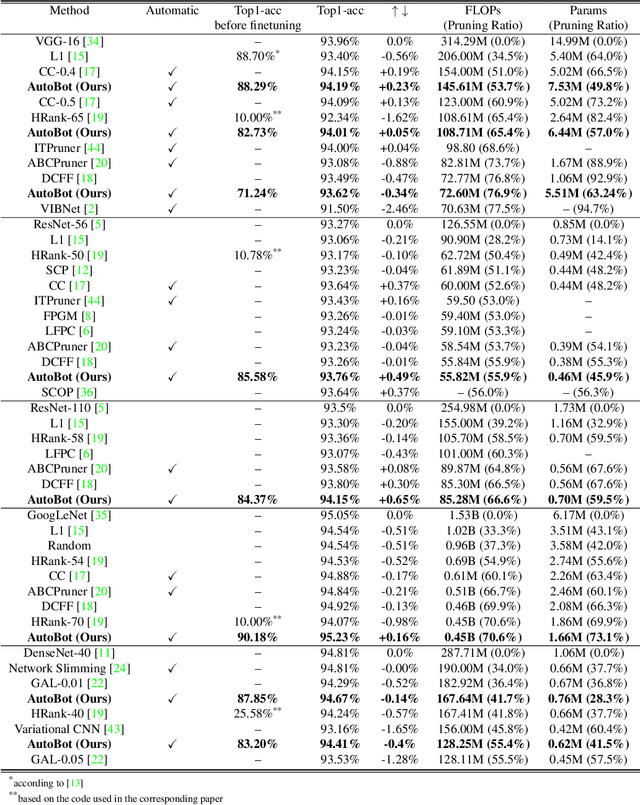

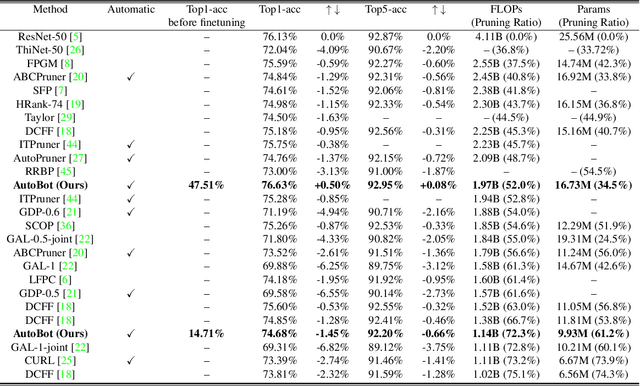
Neural networks performance has been significantly improved in the last few years, at the cost of an increasing number of floating point operations per second (FLOPs). However, more FLOPs can be an issue when computational resources are limited. As an attempt to solve this problem, pruning filters is a common solution, but most existing pruning methods do not preserve the model accuracy efficiently and therefore require a large number of finetuning epochs. In this paper, we propose an automatic pruning method that learns which neurons to preserve in order to maintain the model accuracy while reducing the FLOPs to a predefined target. To accomplish this task, we introduce a trainable bottleneck that only requires one single epoch with 25.6% (CIFAR-10) or 7.49% (ILSVRC2012) of the dataset to learn which filters to prune. Experiments on various architectures and datasets show that the proposed method can not only preserve the accuracy after pruning but also outperform existing methods after finetuning. We achieve a 52.00% FLOPs reduction on ResNet-50, with a Top-1 accuracy of 47.51% after pruning and a state-of-the-art (SOTA) accuracy of 76.63% after finetuning on ILSVRC2012. Code is available at (link anonymized for review).
Toward Compact Deep Neural Networks via Energy-Aware Pruning
Mar 19, 2021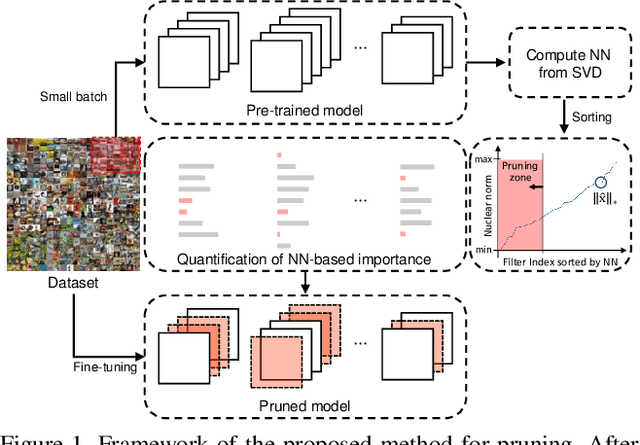
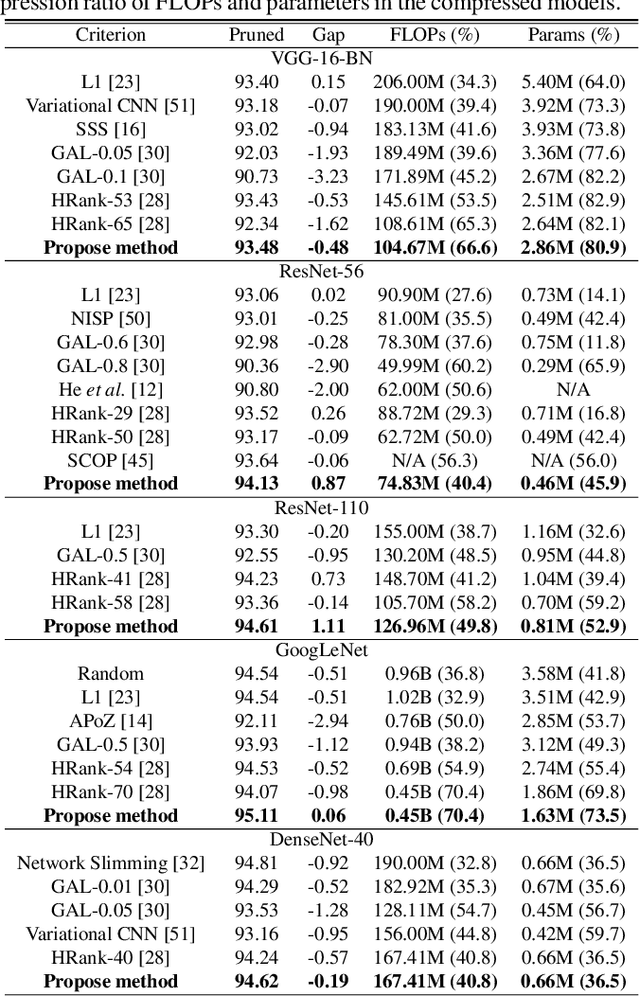
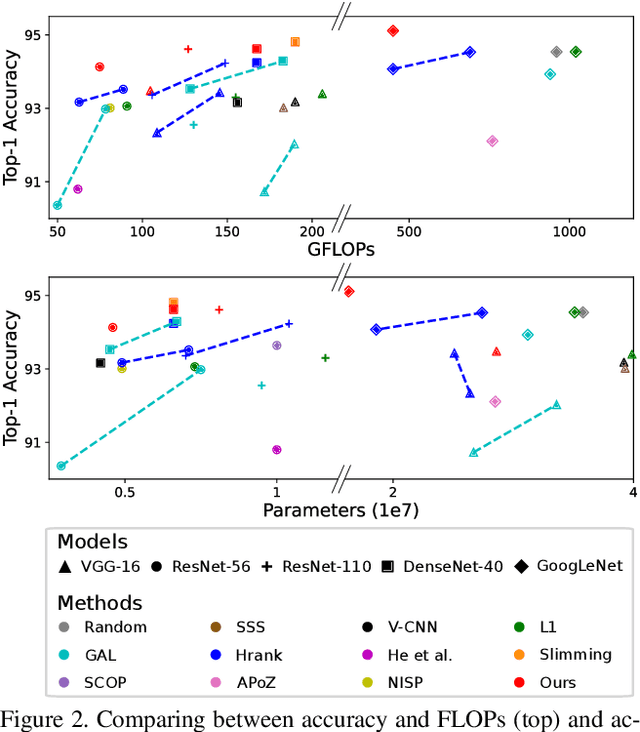
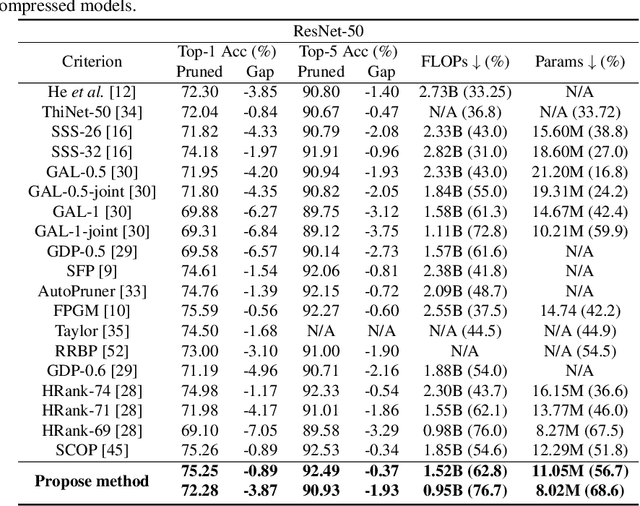
Despite of the remarkable performance, modern deep neural networks are inevitably accompanied with a significant amount of computational cost for learning and deployment, which may be incompatible with their usage on edge devices. Recent efforts to reduce these overheads involves pruning and decomposing the parameters of various layers without performance deterioration. Inspired by several decomposition studies, in this paper, we propose a novel energy-aware pruning method that quantifies the importance of each filter in the network using nuclear-norm (NN). Proposed energy-aware pruning leads to state-of-the art performance for Top-1 accuracy, FLOPs, and parameter reduction across a wide range of scenarios with multiple network architectures on CIFAR-10 and ImageNet after fine-grained classification tasks. On toy experiment, despite of no fine-tuning, we can visually observe that NN not only has little change in decision boundaries across classes, but also clearly outperforms previous popular criteria. We achieve competitive results with 40.4/49.8% of FLOPs and 45.9/52.9% of parameter reduction with 94.13/94.61% in the Top-1 accuracy with ResNet-56/110 on CIFAR-10, respectively. In addition, our observations are consistent for a variety of different pruning setting in terms of data size as well as data quality which can be emphasized in the stability of the acceleration and compression with negligible accuracy loss. Our code is available at https://github.com/nota-github/nota-pruning_rank.
Pruning by Explaining: A Novel Criterion for Deep Neural Network Pruning
Dec 18, 2019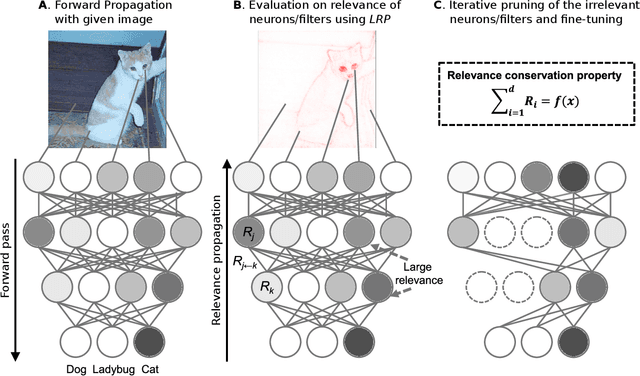
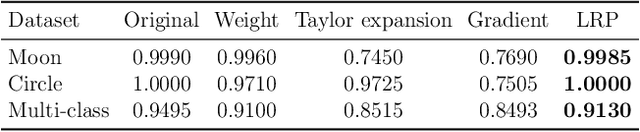
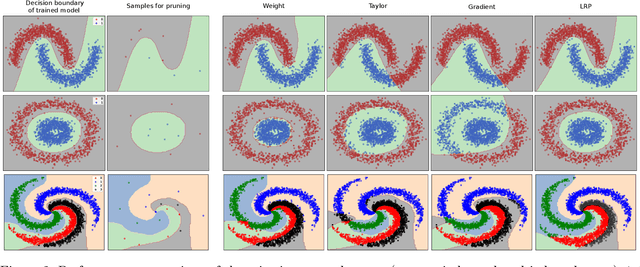
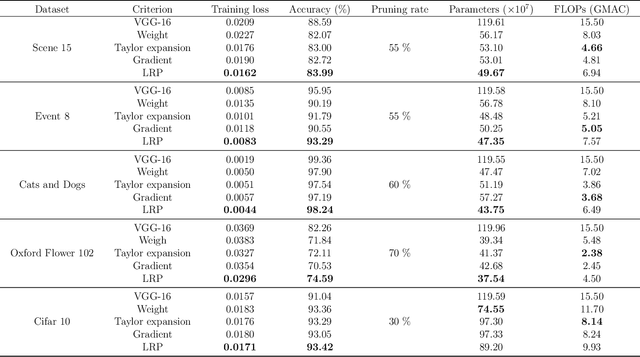
The success of convolutional neural networks (CNNs) in various applications is accompanied by a significant increase in computation and parameter storage costs. Recent efforts to reduce these overheads involve pruning and compressing the weights of various layers while at the same time aiming to not sacrifice performance. In this paper, we propose a novel criterion for CNN pruning inspired by neural network interpretability: The most relevant elements, i.e. weights or filters, are automatically found using their relevance score in the sense of explainable AI (XAI). By that we for the first time link the two disconnected lines of interpretability and model compression research. We show in particular that our proposed method can efficiently prune transfer-learned CNN models where networks pre-trained on large corpora are adapted to specialized tasks. To this end, the method is evaluated on a broad range of computer vision datasets. Notably, our novel criterion is not only competitive or better compared to state-of-the-art pruning criteria when successive retraining is performed, but clearly outperforms these previous criteria in the common application setting where the data of the task to be transferred to are very scarce and no retraining is possible. Our method can iteratively compress the model while maintaining or even improving accuracy. At the same time, it has a computational cost in the order of gradient computation and is comparatively simple to apply without the need for tuning hyperparameters for pruning.