 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERGO: Efficient High-Resolution Visual Understanding for Vision-Language Models
Sep 26, 2025Efficient processing of high-resolution images is crucial for real-world vision-language applications. However, existing Large Vision-Language Models (LVLMs) incur substantial computational overhead due to the large number of vision tokens. With the advent of "thinking with images" models, reasoning now extends beyond text to the visual domain. This capability motivates our two-stage "coarse-to-fine" reasoning pipeline: first, a downsampled image is analyzed to identify task-relevant regions; then, only these regions are cropped at full resolution and processed in a subsequent reasoning stage. This approach reduces computational cost while preserving fine-grained visual details where necessary. A major challenge lies in inferring which regions are truly relevant to a given query. Recent related methods often fail in the first stage after input-image downsampling, due to perception-driven reasoning, where clear visual information is required for effective reasoning. To address this issue, we propose ERGO (Efficient Reasoning & Guided Observation) that performs reasoning-driven perception-leveraging multimodal context to determine where to focus. Our model can account for perceptual uncertainty, expanding the cropped region to cover visually ambiguous areas for answering questions. To this end, we develop simple yet effective reward components in a reinforcement learning framework for coarse-to-fine perception. Across multiple datasets, our approach delivers higher accuracy than the original model and competitive methods, with greater efficiency. For instance, ERGO surpasses Qwen2.5-VL-7B on the V* benchmark by 4.7 points while using only 23% of the vision tokens, achieving a 3x inference speedup. The code and models can be found at: https://github.com/nota-github/ERGO.
Zero-Shot Industrial Anomaly Segmentation with Image-Aware Prompt Generation
Apr 18, 2025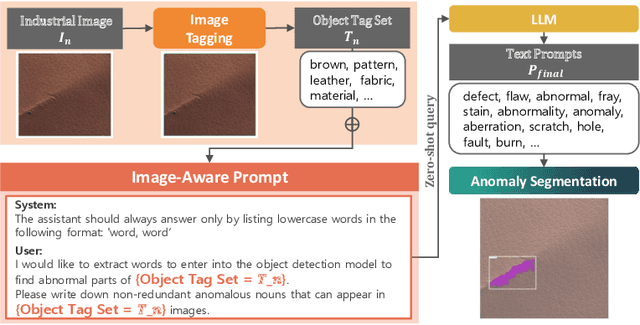
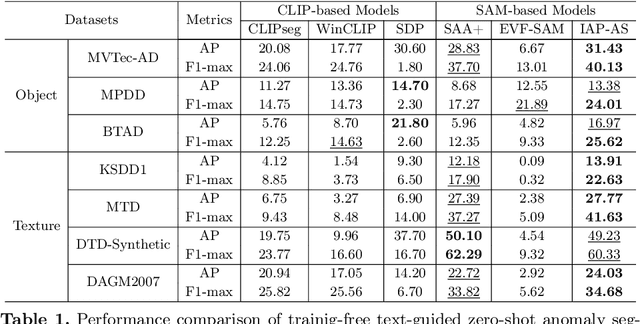
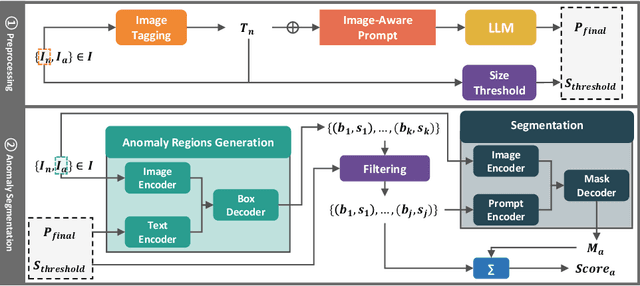

Anomaly segmentation is essential for industrial quality, maintenance, and stability. Existing text-guided zero-shot anomaly segmentation models are effective but rely on fixed prompts, limiting adaptability in diverse industrial scenarios. This highlights the need for flexible, context-aware prompting strategies. We propose Image-Aware Prompt Anomaly Segmentation (IAP-AS), which enhances anomaly segmentation by generating dynamic, context-aware prompts using an image tagging model and a large language model (LLM). IAP-AS extracts object attributes from images to generate context-aware prompts, improving adaptability and generalization in dynamic and unstructured industrial environments. In our experiments, IAP-AS improves the F1-max metric by up to 10%, demonstrating superior adaptability and generalization. It provides a scalable solution for anomaly segmentation across industries
Efficient LLaMA-3.2-Vision by Trimming Cross-attended Visual Features
Apr 01, 2025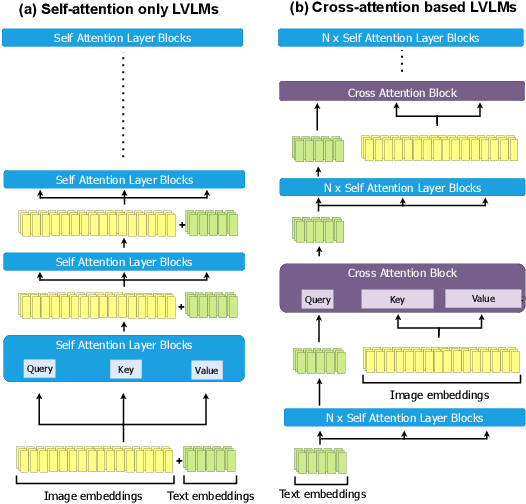
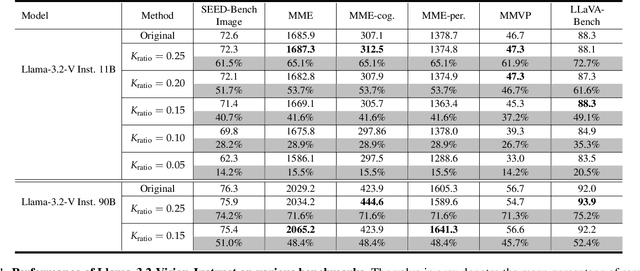
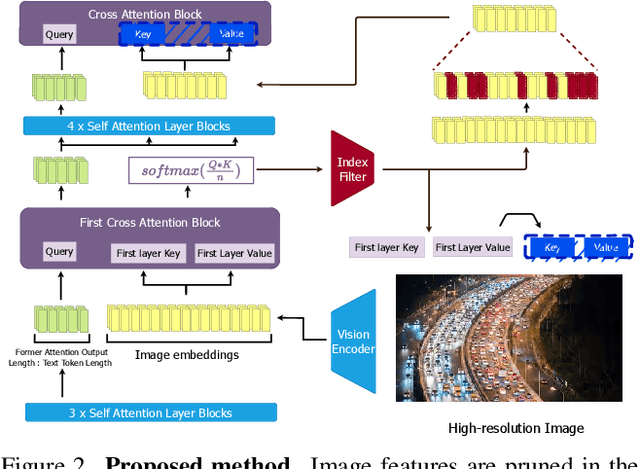
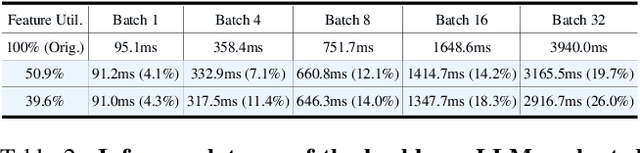
Visual token reduction lowers inference costs caused by extensive image features in large vision-language models (LVLMs). Unlike relevant studies that prune tokens in self-attention-only LVLMs, our work uniquely addresses cross-attention-based models, which achieve superior performance. We identify that the key-value (KV) cache size for image tokens in cross-attention layers significantly exceeds that of text tokens in self-attention layers, posing a major compute bottleneck. To mitigate this issue, we exploit the sparse nature in cross-attention maps to selectively prune redundant visual features. Our Trimmed Llama effectively reduces KV cache demands without requiring additional training. By benefiting from 50%-reduced visual features, our model can reduce inference latency and memory usage while achieving benchmark parity.
UniForm: A Reuse Attention Mechanism Optimized for Efficient Vision Transformers on Edge Devices
Dec 03, 2024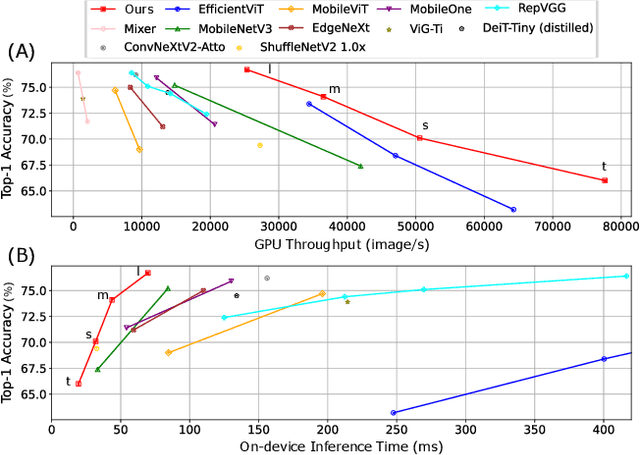

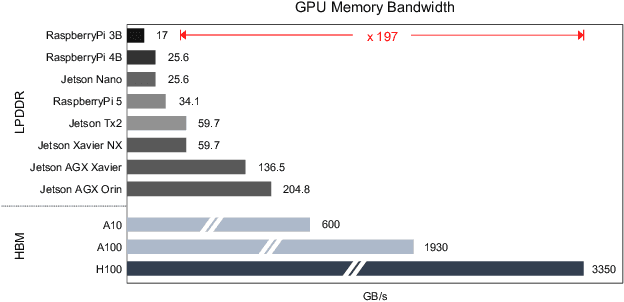
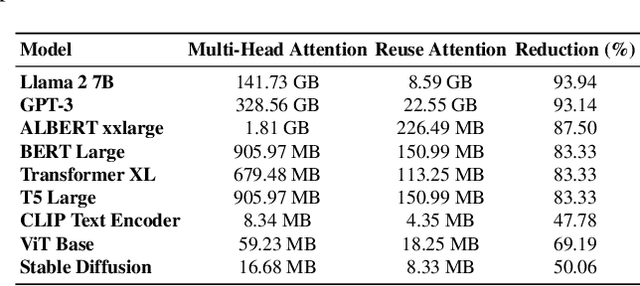
Transformer-based architectures have demonstrated remarkable success across various domains, but their deployment on edge devices remains challenging due to high memory and computational demands. In this paper, we introduce a novel Reuse Attention mechanism, tailored for efficient memory access and computational optimization, enabling seamless operation on resource-constrained platforms without compromising performance. Unlike traditional multi-head attention (MHA), which redundantly computes separate attention matrices for each head, Reuse Attention consolidates these computations into a shared attention matrix, significantly reducing memory overhead and computational complexity. Comprehensive experiments on ImageNet-1K and downstream tasks show that the proposed UniForm models leveraging Reuse Attention achieve state-of-the-art imagenet classification accuracy while outperforming existing attention mechanisms, such as Linear Attention and Flash Attention, in inference speed and memory scalability. Notably, UniForm-l achieves a 76.7% Top-1 accuracy on ImageNet-1K with 21.8ms inference time on edge devices like the Jetson AGX Orin, representing up to a 5x speedup over competing benchmark methods. These results demonstrate the versatility of Reuse Attention across high-performance GPUs and edge platforms, paving the way for broader real-time applications
Assessing the Answerability of Queries in Retrieval-Augmented Code Generation
Nov 08, 2024


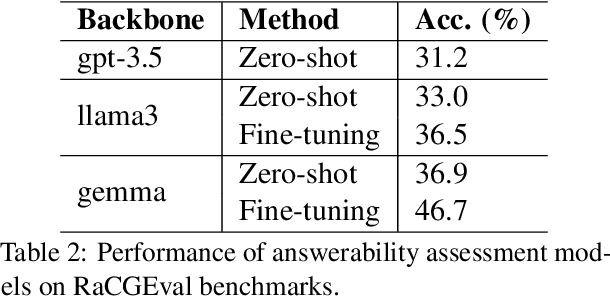
Thanks to unprecedented language understanding and generation capabilities of large language model (LLM), Retrieval-augmented Code Generation (RaCG) has recently been widely utilized among software developers. While this has increased productivity, there are still frequent instances of incorrect codes being provided. In particular, there are cases where plausible yet incorrect codes are generated for queries from users that cannot be answered with the given queries and API descriptions. This study proposes a task for evaluating answerability, which assesses whether valid answers can be generated based on users' queries and retrieved APIs in RaCG. Additionally, we build a benchmark dataset called Retrieval-augmented Code Generability Evaluation (RaCGEval) to evaluate the performance of models performing this task. Experimental results show that this task remains at a very challenging level, with baseline models exhibiting a low performance of 46.7%. Furthermore, this study discusses methods that could significantly improve performance.
EdgeFusion: On-Device Text-to-Image Generation
Apr 18, 2024The intensive computational burden of Stable Diffusion (SD) for text-to-image generation poses a significant hurdle for its practical application. To tackle this challenge, recent research focuses on methods to reduce sampling steps, such as Latent Consistency Model (LCM), and on employing architectural optimizations, including pruning and knowledge distillation. Diverging from existing approaches, we uniquely start with a compact SD variant, BK-SDM. We observe that directly applying LCM to BK-SDM with commonly used crawled datasets yields unsatisfactory results. It leads us to develop two strategies: (1) leveraging high-quality image-text pairs from leading generative models and (2) designing an advanced distillation process tailored for LCM. Through our thorough exploration of quantization, profiling, and on-device deployment, we achieve rapid generation of photo-realistic, text-aligned images in just two steps, with latency under one second on resource-limited edge devices.
Sora as an AGI World Model? A Complete Survey on Text-to-Video Generation
Mar 08, 2024


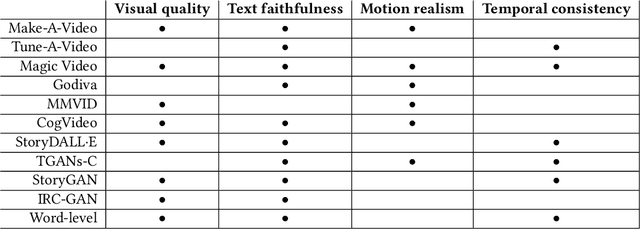
Text-to-video generation marks a significant frontier in the rapidly evolving domain of generative AI, integrating advancements in text-to-image synthesis, video captioning, and text-guided editing. This survey critically examines the progression of text-to-video technologies, focusing on the shift from traditional generative models to the cutting-edge Sora model, highlighting developments in scalability and generalizability. Distinguishing our analysis from prior works, we offer an in-depth exploration of the technological frameworks and evolutionary pathways of these models. Additionally, we delve into practical applications and address ethical and technological challenges such as the inability to perform multiple entity handling, comprehend causal-effect learning, understand physical interaction, perceive object scaling and proportioning, and combat object hallucination which is also a long-standing problem in generative models. Our comprehensive discussion covers the topic of enablement of text-to-video generation models as human-assistive tools and world models, as well as eliciting model's shortcomings and summarizing future improvement direction that mainly centers around training datasets and evaluation metrics (both automatic and human-centered). Aimed at both newcomers and seasoned researchers, this survey seeks to catalyze further innovation and discussion in the growing field of text-to-video generation, paving the way for more reliable and practical generative artificial intelligence technologies.
Shortened LLaMA: A Simple Depth Pruning for Large Language Models
Feb 05, 2024Structured pruning of modern large language models (LLMs) has emerged as a way of decreasing their high computational needs. Width pruning reduces the size of projection weight matrices (e.g., by removing attention heads) while maintaining the number of layers. Depth pruning, in contrast, removes entire layers or blocks, while keeping the size of the remaining weights unchanged. Most current research focuses on either width-only or a blend of width and depth pruning, with little comparative analysis between the two units (width vs. depth) concerning their impact on LLM inference efficiency. In this work, we show that a simple depth pruning approach can compete with recent width pruning methods in terms of zero-shot task performance. Our pruning method boosts inference speeds, especially under memory-constrained conditions that require limited batch sizes for running LLMs, where width pruning is ineffective. We hope this work can help deploy LLMs on local and edge devices.
MobileSAMv2: Faster Segment Anything to Everything
Dec 15, 2023Segment anything model (SAM) addresses two practical yet challenging segmentation tasks: \textbf{segment anything (SegAny)}, which utilizes a certain point to predict the mask for a single object of interest, and \textbf{segment everything (SegEvery)}, which predicts the masks for all objects on the image. What makes SegAny slow for SAM is its heavyweight image encoder, which has been addressed by MobileSAM via decoupled knowledge distillation. The efficiency bottleneck of SegEvery with SAM, however, lies in its mask decoder because it needs to first generate numerous masks with redundant grid-search prompts and then perform filtering to obtain the final valid masks. We propose to improve its efficiency by directly generating the final masks with only valid prompts, which can be obtained through object discovery. Our proposed approach not only helps reduce the total time on the mask decoder by at least 16 times but also achieves superior performance. Specifically, our approach yields an average performance boost of 3.6\% (42.5\% \textit{v.s.} 38.9\%) for zero-shot object proposal on the LVIS dataset with the mask AR@$K$ metric. Qualitative results show that our approach generates fine-grained masks while avoiding over-segmenting things. This project targeting faster SegEvery than the original SAM is termed MobileSAMv2 to differentiate from MobileSAM which targets faster SegAny. Moreover, we demonstrate that our new prompt sampling is also compatible with the distilled image encoders in MobileSAM, contributing to a unified framework for efficient SegAny and SegEvery. The code is available at the same link as MobileSAM Project \href{https://github.com/ChaoningZhang/MobileSAM}{\textcolor{red}{https://github.com/ChaoningZhang/MobileSAM}}. \end{abstract}
Automatic Network Adaptation for Ultra-Low Uniform-Precision Quantization
Jan 04, 2023Uniform-precision neural network quantization has gained popularity since it simplifies densely packed arithmetic unit for high computing capability. However, it ignores heterogeneous sensitivity to the impact of quantization errors across the layers, resulting in sub-optimal inference accuracy. This work proposes a novel neural architecture search called neural channel expansion that adjusts the network structure to alleviate accuracy degradation from ultra-low uniform-precision quantization. The proposed method selectively expands channels for the quantization sensitive layers while satisfying hardware constraints (e.g., FLOPs, PARAMs). Based on in-depth analysis and experiments, we demonstrate that the proposed method can adapt several popular networks channels to achieve superior 2-bit quantization accuracy on CIFAR10 and ImageNet. In particular, we achieve the best-to-date Top-1/Top-5 accuracy for 2-bit ResNet50 with smaller FLOPs and the parameter size.