 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantile-Free Uncertainty Quantification in Graph Neural Networks
May 06, 2026Uncertainty quantification (UQ) in graph neural networks (GNNs) is crucial in high-stakes domains but remains a significant challenge. In graph settings, message passing often relies on strong assumptions such as exchangeability, which are rarely satisfied in practice. Moreover, achieving reliable UQ typically requires costly resampling or post-hoc calibration. To address these issues, we introduce Quantile-free Prediction Interval GNN (QpiGNN), a framework that builds on quantile regression (QR) to enable GNN-based UQ by directly optimizing coverage and interval width without requiring quantile inputs or post-processing. QpiGNN employs a dual-head architecture that decouples prediction and uncertainty, and is trained with label-only supervision through a quantile-free joint loss. This design allows efficient training and yields robust prediction intervals, with theoretical guarantees of asymptotic coverage and near-optimal width under mild assumptions. Experiments on 19 synthetic and real-world benchmarks show QpiGNN achieves average 22\% higher coverage and 50\% narrower intervals than baselines, while ensuring efficiency and robustness to noise and structural shifts.
Hyperbolic Heterogeneous Graph Transformer
Jan 13, 2026In heterogeneous graphs, we can observe complex structures such as tree-like or hierarchical structures. Recently, the hyperbolic space has been widely adopted in many studies to effectively learn these complex structures. Although these methods have demonstrated the advantages of the hyperbolic space in learning heterogeneous graphs, most existing methods still have several challenges. They rely heavily on tangent-space operations, which often lead to mapping distortions during frequent transitions. Moreover, their message-passing architectures mainly focus on local neighborhood information, making it difficult to capture global hierarchical structures and long-range dependencies between different types of nodes. To address these limitations, we propose Hyperbolic Heterogeneous Graph Transformer (HypHGT), which effectively and efficiently learns heterogeneous graph representations entirely within the hyperbolic space. Unlike previous message-passing based hyperbolic heterogeneous GNNs, HypHGT naturally captures both local and global dependencies through transformer-based architecture. Furthermore, the proposed relation-specific hyperbolic attention mechanism in HypHGT, which operates with linear time complexity, enables efficient computation while preserving the heterogeneous information across different relation types. This design allows HypHGT to effectively capture the complex structural properties and semantic information inherent in heterogeneous graphs. We conduct comprehensive experiments to evaluate the effectiveness and efficiency of HypHGT, and the results demonstrate that it consistently outperforms state-of-the-art methods in node classification task, with significantly reduced training time and memory usage.
FnRGNN: Distribution-aware Fairness in Graph Neural Network
Oct 22, 2025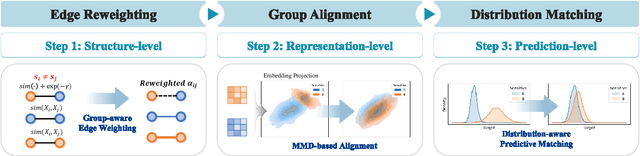
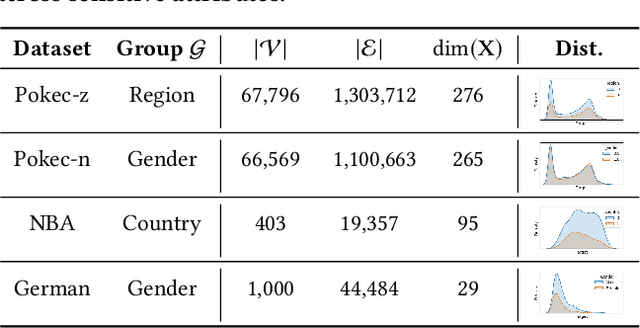
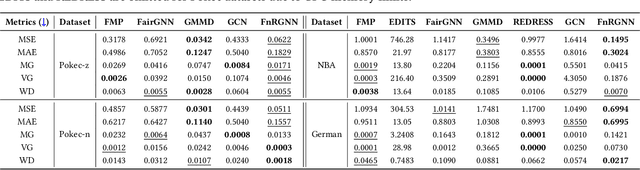
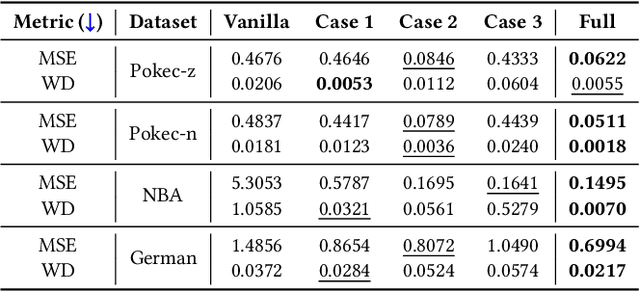
Graph Neural Networks (GNNs) excel at learning from structured data, yet fairness in regression tasks remains underexplored. Existing approaches mainly target classification and representation-level debiasing, which cannot fully address the continuous nature of node-level regression. We propose FnRGNN, a fairness-aware in-processing framework for GNN-based node regression that applies interventions at three levels: (i) structure-level edge reweighting, (ii) representation-level alignment via MMD, and (iii) prediction-level normalization through Sinkhorn-based distribution matching. This multi-level strategy ensures robust fairness under complex graph topologies. Experiments on four real-world datasets demonstrate that FnRGNN reduces group disparities without sacrificing performance. Code is available at https://github.com/sybeam27/FnRGNN.
Zero-Shot Industrial Anomaly Segmentation with Image-Aware Prompt Generation
Apr 18, 2025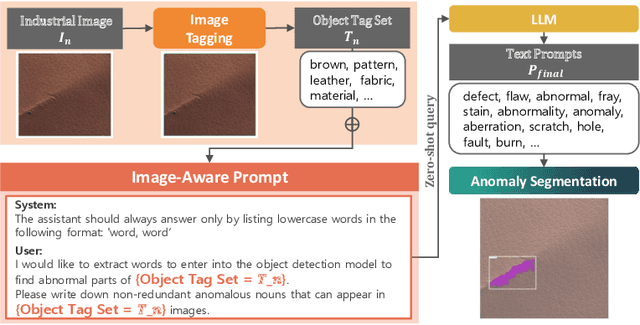
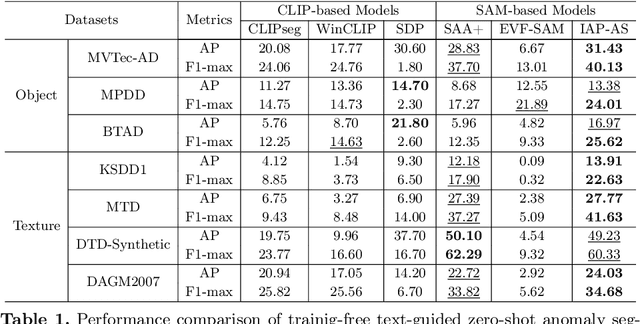
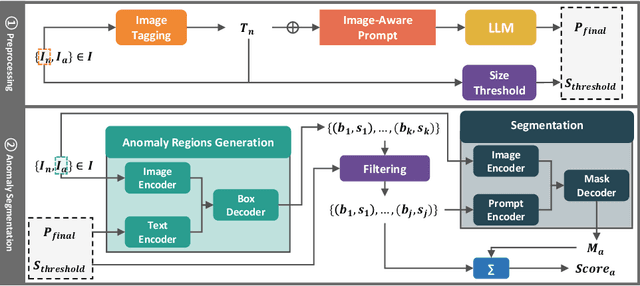

Anomaly segmentation is essential for industrial quality, maintenance, and stability. Existing text-guided zero-shot anomaly segmentation models are effective but rely on fixed prompts, limiting adaptability in diverse industrial scenarios. This highlights the need for flexible, context-aware prompting strategies. We propose Image-Aware Prompt Anomaly Segmentation (IAP-AS), which enhances anomaly segmentation by generating dynamic, context-aware prompts using an image tagging model and a large language model (LLM). IAP-AS extracts object attributes from images to generate context-aware prompts, improving adaptability and generalization in dynamic and unstructured industrial environments. In our experiments, IAP-AS improves the F1-max metric by up to 10%, demonstrating superior adaptability and generalization. It provides a scalable solution for anomaly segmentation across industries
Multi-Hyperbolic Space-based Heterogeneous Graph Attention Network
Nov 18, 2024


To leverage the complex structures within heterogeneous graphs, recent studies on heterogeneous graph embedding use a hyperbolic space, characterized by a constant negative curvature and exponentially increasing space, which aligns with the structural properties of heterogeneous graphs. However, despite heterogeneous graphs inherently possessing diverse power-law structures, most hyperbolic heterogeneous graph embedding models use a single hyperbolic space for the entire heterogeneous graph, which may not effectively capture the diverse power-law structures within the heterogeneous graph. To address this limitation, we propose Multi-hyperbolic Space-based heterogeneous Graph Attention Network (MSGAT), which uses multiple hyperbolic spaces to effectively capture diverse power-law structures within heterogeneous graphs. We conduct comprehensive experiments to evaluate the effectiveness of MSGAT. The experimental results demonstrate that MSGAT outperforms state-of-the-art baselines in various graph machine learning tasks, effectively capturing the complex structures of heterogeneous graphs.
ANOMIX: A Simple yet Effective Hard Negative Generation via Mixing for Graph Anomaly Detection
Oct 27, 2024



Graph contrastive learning (GCL) generally requires a large number of samples. The one of the effective ways to reduce the number of samples is using hard negatives (e.g., Mixup). Designing mixing-based approach for GAD can be difficult due to imbalanced data or limited number of anomalies. We propose ANOMIX, a framework that consists of a novel graph mixing approach, ANOMIX-M, and multi-level contrasts for GAD. ANOMIX-M can effectively mix abnormality and normality from input graph to generate hard negatives, which are important for efficient GCL. ANOMIX is (a) A first mixing approach: firstly attempting graph mixing to generate hard negatives for GAD task and node- and subgraph-level contrasts to distinguish underlying anomalies. (b) Accurate: winning the highest AUC, up to 5.49% higher and 1.76% faster. (c) Effective: reducing the number of samples nearly 80% in GCL. Code is available at https://github.com/missinghwan/ANOMIX.
Hyperbolic Heterogeneous Graph Attention Networks
Apr 15, 2024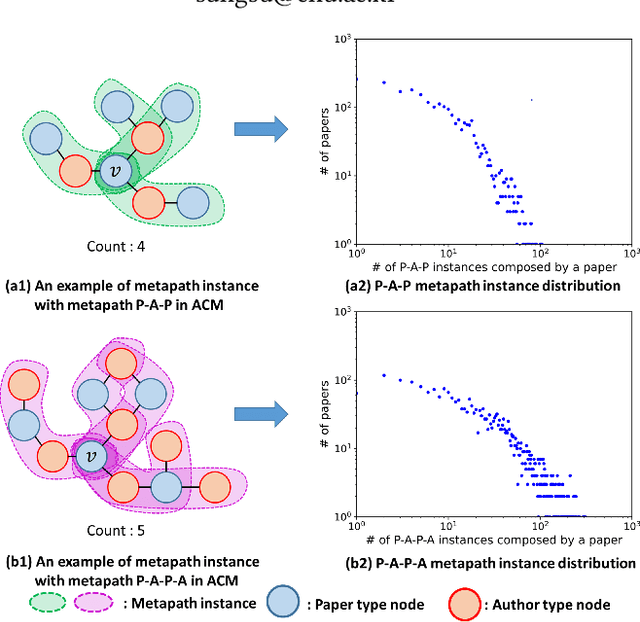
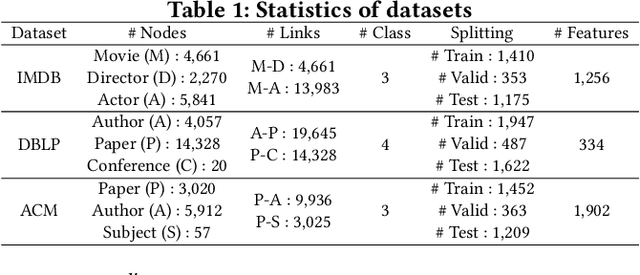
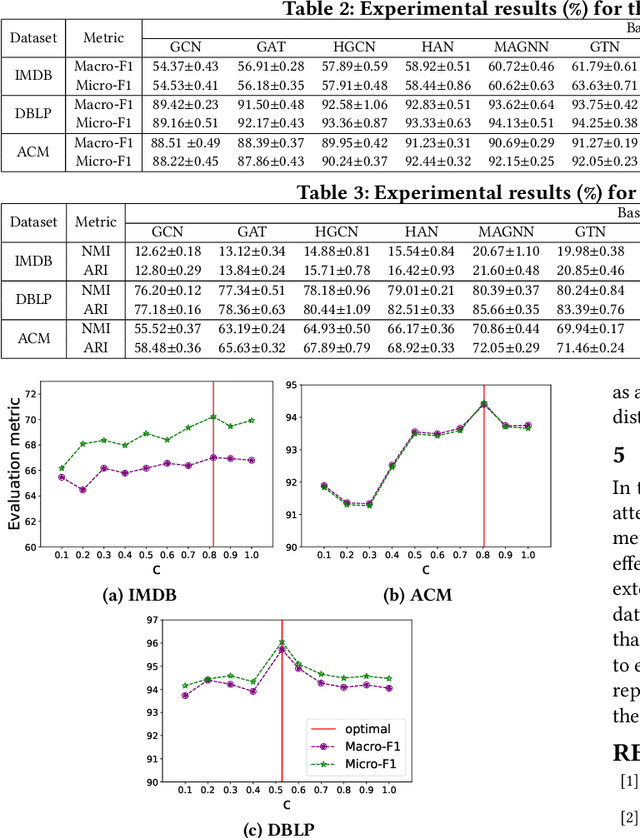
Most previous heterogeneous graph embedding models represent elements in a heterogeneous graph as vector representations in a low-dimensional Euclidean space. However, because heterogeneous graphs inherently possess complex structures, such as hierarchical or power-law structures, distortions can occur when representing them in Euclidean space. To overcome this limitation, we propose Hyperbolic Heterogeneous Graph Attention Networks (HHGAT) that learn vector representations in hyperbolic spaces with meta-path instances. We conducted experiments on three real-world heterogeneous graph datasets, demonstrating that HHGAT outperforms state-of-the-art heterogeneous graph embedding models in node classification and clustering tasks.
Deep Semi-supervised Anomaly Detection with Metapath-based Context Knowledge
Aug 21, 2023



Graph anomaly detection has attracted considerable attention in recent years. This paper introduces a novel approach that leverages metapath-based semi-supervised learning, addressing the limitations of previous methods. We present a new framework, Metapath-based Semi-supervised Anomaly Detection (MSAD), incorporating GCN layers in both the encoder and decoder to efficiently propagate context information between abnormal and normal nodes. The design of metapath-based context information and a specifically crafted anomaly community enhance the process of learning differences in structures and attributes, both globally and locally. Through a comprehensive set of experiments conducted on seven real-world networks, this paper demonstrates the superiority of the MSAD method compared to state-of-the-art techniques. The promising results of this study pave the way for future investigations, focusing on the optimization and analysis of metapath patterns to further enhance the effectiveness of anomaly detection on attributed networks.
A Unified Compression Framework for Efficient Speech-Driven Talking-Face Generation
Apr 02, 2023Virtual humans have gained considerable attention in numerous industries, e.g., entertainment and e-commerce. As a core technology, synthesizing photorealistic face frames from target speech and facial identity has been actively studied with generative adversarial networks. Despite remarkable results of modern talking-face generation models, they often entail high computational burdens, which limit their efficient deployment. This study aims to develop a lightweight model for speech-driven talking-face synthesis. We build a compact generator by removing the residual blocks and reducing the channel width from Wav2Lip, a popular talking-face generator. We also present a knowledge distillation scheme to stably yet effectively train the small-capacity generator without adversarial learning. We reduce the number of parameters and MACs by 28$\times$ while retaining the performance of the original model. Moreover, to alleviate a severe performance drop when converting the whole generator to INT8 precision, we adopt a selective quantization method that uses FP16 for the quantization-sensitive layers and INT8 for the other layers. Using this mixed precision, we achieve up to a 19$\times$ speedup on edge GPUs without noticeably compromising the generation quality.
Graph Anomaly Detection with Graph Neural Networks: Current Status and Challenges
Oct 04, 2022
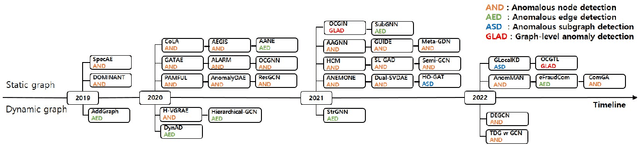
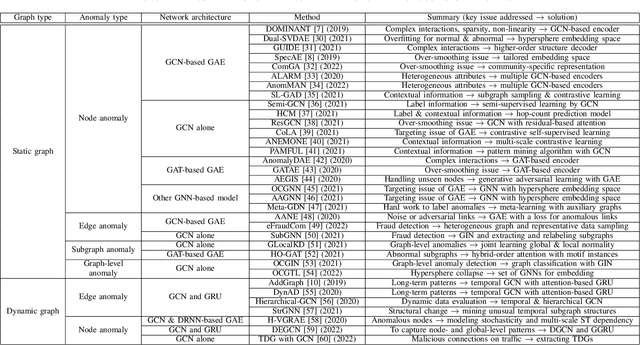
Graphs are used widely to model complex systems, and detecting anomalies in a graph is an important task in the analysis of complex systems. Graph anomalies are patterns in a graph that do not conform to normal patterns expected of the attributes and/or structures of the graph. In recent years, graph neural networks (GNNs) have been studied extensively and have successfully performed difficult machine learning tasks in node classification, link prediction, and graph classification thanks to the highly expressive capability via message passing in effectively learning graph representations. To solve the graph anomaly detection problem, GNN-based methods leverage information about the graph attributes (or features) and/or structures to learn to score anomalies appropriately. In this survey, we review the recent advances made in detecting graph anomalies using GNN models. Specifically, we summarize GNN-based methods according to the graph type (i.e., static and dynamic), the anomaly type (i.e., node, edge, subgraph, and whole graph), and the network architecture (e.g., graph autoencoder, graph convolutional network). To the best of our knowledge, this survey is the first comprehensive review of graph anomaly detection methods based on GNNs.