 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Show Pixels, Show Cues: Unlocking Visual Tool Reasoning in Language Models via Perception Programs
Apr 14, 2026Multimodal language models (MLLMs) are increasingly paired with vision tools (e.g., depth, flow, correspondence) to enhance visual reasoning. However, despite access to these tool-generated visual cues, MLLMs often fail to benefit from them. Existing approaches typically feed raw tool outputs into the model, but these dense, pixel-level representations are misaligned with the language-native reasoning strengths of LLMs, leading to weak perception and reliance on language priors. We argue that, in problems where vision tools can provide the necessary visual cues, the bottleneck is not more tool calls or larger MLLMs, it is how tool outputs are represented. We introduce Perception Programs (P$^2$), a training-free, model-agnostic method that rewrites tool outputs into compact, structured, language-native summaries that MLLMs can directly parse and reason over. Across six perception-centric tasks in BLINK, P$^2$ consistently yields large improvements over base models and raw tool-augmented baselines. With GPT-5 Mini as the base model, P$^2$ raises its accuracy from 41.35\% to 86.47\% on multi-view reasoning, from 52.42\% to 81.45\% on relative depth, and achieves a 22\% average gain across tasks, setting new state-of-the-art results. Even on smaller MLLMs, e.g., InternVL3.5-4B and Qwen3VL-4B, we observe 15-40\% absolute gains from P$^2$, surpassing prior agentic, supervised, and RL-based tool-use methods-without any training or model modifications.
Mobile Exergames: Activity Recognition Based on Smartphone Sensors
Jan 31, 2026Smartphone sensors can be extremely useful in providing information on the activities and behaviors of persons. Human activity recognition is increasingly used for games, medical, or surveillance. In this paper, we propose a proof-of-concept 2D endless game called Duck Catch & Fit, which implements a detailed activity recognition system that uses a smartphone accelerometer, gyroscope, and magnetometer sensors. The system applies feature extraction and learning mechanism to detect human activities like staying, side movements, and fake side movements. In addition, a voice recognition system is combined to recognize the word "fire" and raise the game's complexity. The results show that it is possible to use machine learning techniques to recognize human activity with high recognition levels. Also, the combination of movement-based and voice-based integrations contributes to a more immersive gameplay.
Meta-Judging with Large Language Models: Concepts, Methods, and Challenges
Jan 24, 2026Large language models (LLMs) are evolving fast and are now frequently used as evaluators, in a process typically referred to as LLM-as-a-Judge, which provides quality assessments of model outputs. However, recent research points out significant vulnerabilities in such evaluation, including sensitivity to prompts, systematic biases, verbosity effects, and unreliable or hallucinated rationales. These limitations motivated the development of a more robust paradigm, dubbed LLM-as-a-Meta-Judge. This survey reviews recent advances in meta-judging and organizes the literature, by introducing a framework along six key perspectives: (i) Conceptual Foundations, (ii) Mechanisms of Meta-Judging, (iii) Alignment Training Methods, (iv) Evaluation, (v) Limitations and Failure Modes, and (vi) Future Directions. By analyzing the limitations of LLM-as-a-Judge and summarizing recent advances in meta-judging by LLMs, we argue that LLM-as-a-Meta-Judge offers a promising direction for more stable and trustworthy automated evaluation, while highlighting remaining challenges related to cost, prompt sensitivity, and shared model biases, which must be addressed to advance the next generation of LLM evaluation methodologies.
What to Do When Your Discrete Optimization Is the Size of a Neural Network?
Feb 15, 2024



Oftentimes, machine learning applications using neural networks involve solving discrete optimization problems, such as in pruning, parameter-isolation-based continual learning and training of binary networks. Still, these discrete problems are combinatorial in nature and are also not amenable to gradient-based optimization. Additionally, classical approaches used in discrete settings do not scale well to large neural networks, forcing scientists and empiricists to rely on alternative methods. Among these, two main distinct sources of top-down information can be used to lead the model to good solutions: (1) extrapolating gradient information from points outside of the solution set (2) comparing evaluations between members of a subset of the valid solutions. We take continuation path (CP) methods to represent using purely the former and Monte Carlo (MC) methods to represent the latter, while also noting that some hybrid methods combine the two. The main goal of this work is to compare both approaches. For that purpose, we first overview the two classes while also discussing some of their drawbacks analytically. Then, on the experimental section, we compare their performance, starting with smaller microworld experiments, which allow more fine-grained control of problem variables, and gradually moving towards larger problems, including neural network regression and neural network pruning for image classification, where we additionally compare against magnitude-based pruning.
The MONET dataset: Multimodal drone thermal dataset recorded in rural scenarios
Apr 11, 2023
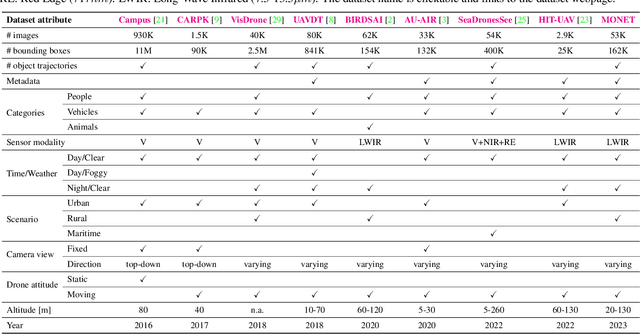
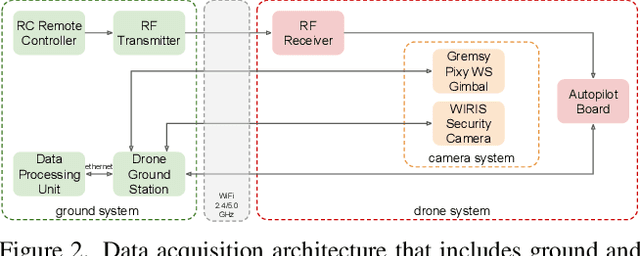
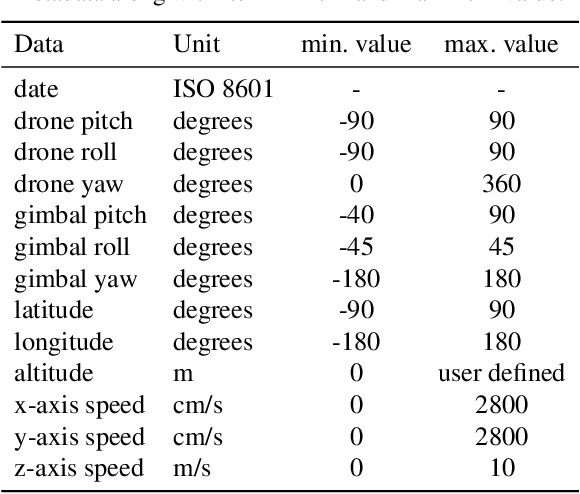
We present MONET, a new multimodal dataset captured using a thermal camera mounted on a drone that flew over rural areas, and recorded human and vehicle activities. We captured MONET to study the problem of object localisation and behaviour understanding of targets undergoing large-scale variations and being recorded from different and moving viewpoints. Target activities occur in two different land sites, each with unique scene structures and cluttered backgrounds. MONET consists of approximately 53K images featuring 162K manually annotated bounding boxes. Each image is timestamp-aligned with drone metadata that includes information about attitudes, speed, altitude, and GPS coordinates. MONET is different from previous thermal drone datasets because it features multimodal data, including rural scenes captured with thermal cameras containing both person and vehicle targets, along with trajectory information and metadata. We assessed the difficulty of the dataset in terms of transfer learning between the two sites and evaluated nine object detection algorithms to identify the open challenges associated with this type of data. Project page: https://github.com/fabiopoiesi/monet_dataset.
Greedification Operators for Policy Optimization: Investigating Forward and Reverse KL Divergences
Jul 17, 2021

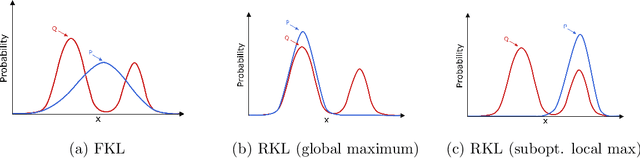

Approximate Policy Iteration (API) algorithms alternate between (approximate) policy evaluation and (approximate) greedification. Many different approaches have been explored for approximate policy evaluation, but less is understood about approximate greedification and what choices guarantee policy improvement. In this work, we investigate approximate greedification when reducing the KL divergence between the parameterized policy and the Boltzmann distribution over action values. In particular, we investigate the difference between the forward and reverse KL divergences, with varying degrees of entropy regularization. We show that the reverse KL has stronger policy improvement guarantees, but that reducing the forward KL can result in a worse policy. We also demonstrate, however, that a large enough reduction of the forward KL can induce improvement under additional assumptions. Empirically, we show on simple continuous-action environments that the forward KL can induce more exploration, but at the cost of a more suboptimal policy. No significant differences were observed in the discrete-action setting or on a suite of benchmark problems. Throughout, we highlight that many policy gradient methods can be seen as an instance of API, with either the forward or reverse KL for the policy update, and discuss next steps for understanding and improving our policy optimization algorithms.
Winning the Lottery with Continuous Sparsification
Dec 10, 2019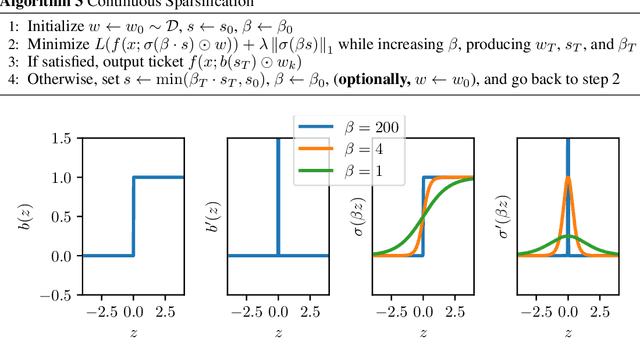
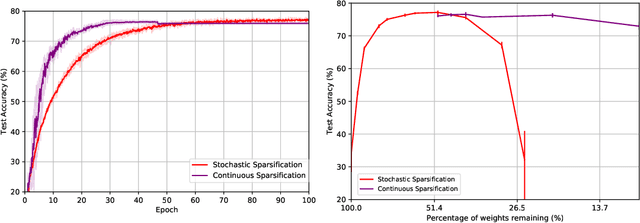
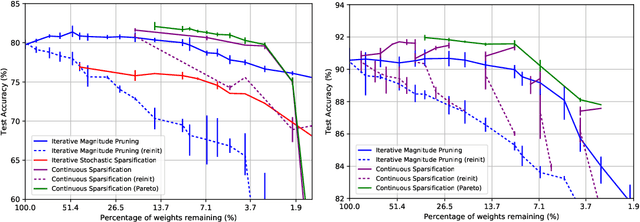
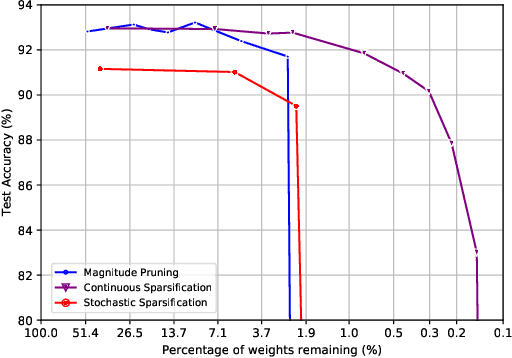
The Lottery Ticket Hypothesis from Frankle & Carbin (2019) conjectures that, for typically-sized neural networks, it is possible to find small sub-networks which train faster and yield superior performance than their original counterparts. The proposed algorithm to search for "winning tickets", Iterative Magnitude Pruning, consistently finds sub-networks with $90-95\%$ less parameters which train faster and better than the overparameterized models they were extracted from, creating potential applications to problems such as transfer learning. In this paper, we propose Continuous Sparsification, a new algorithm to search for winning tickets which continuously removes parameters from a network during training, and learns the sub-network's structure with gradient-based methods instead of relying on pruning strategies. We show empirically that our method is capable of finding tickets that outperforms the ones learned by Iterative Magnitude Pruning, and at the same time providing faster search, when measured in number of training epochs or wall-clock time.