 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRASPLAT: Enabling dexterous grasping through novel view synthesis
Oct 22, 2025Achieving dexterous robotic grasping with multi-fingered hands remains a significant challenge. While existing methods rely on complete 3D scans to predict grasp poses, these approaches face limitations due to the difficulty of acquiring high-quality 3D data in real-world scenarios. In this paper, we introduce GRASPLAT, a novel grasping framework that leverages consistent 3D information while being trained solely on RGB images. Our key insight is that by synthesizing physically plausible images of a hand grasping an object, we can regress the corresponding hand joints for a successful grasp. To achieve this, we utilize 3D Gaussian Splatting to generate high-fidelity novel views of real hand-object interactions, enabling end-to-end training with RGB data. Unlike prior methods, our approach incorporates a photometric loss that refines grasp predictions by minimizing discrepancies between rendered and real images. We conduct extensive experiments on both synthetic and real-world grasping datasets, demonstrating that GRASPLAT improves grasp success rates up to 36.9% over existing image-based methods. Project page: https://mbortolon97.github.io/grasplat/
Free-form language-based robotic reasoning and grasping
Mar 17, 2025
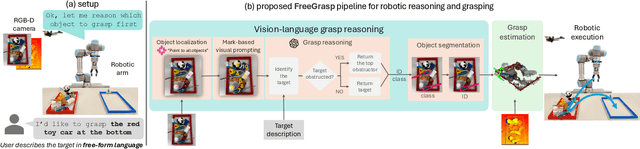


Performing robotic grasping from a cluttered bin based on human instructions is a challenging task, as it requires understanding both the nuances of free-form language and the spatial relationships between objects. Vision-Language Models (VLMs) trained on web-scale data, such as GPT-4o, have demonstrated remarkable reasoning capabilities across both text and images. But can they truly be used for this task in a zero-shot setting? And what are their limitations? In this paper, we explore these research questions via the free-form language-based robotic grasping task, and propose a novel method, FreeGrasp, leveraging the pre-trained VLMs' world knowledge to reason about human instructions and object spatial arrangements. Our method detects all objects as keypoints and uses these keypoints to annotate marks on images, aiming to facilitate GPT-4o's zero-shot spatial reasoning. This allows our method to determine whether a requested object is directly graspable or if other objects must be grasped and removed first. Since no existing dataset is specifically designed for this task, we introduce a synthetic dataset FreeGraspData by extending the MetaGraspNetV2 dataset with human-annotated instructions and ground-truth grasping sequences. We conduct extensive analyses with both FreeGraspData and real-world validation with a gripper-equipped robotic arm, demonstrating state-of-the-art performance in grasp reasoning and execution. Project website: https://tev-fbk.github.io/FreeGrasp/.
6DGS: 6D Pose Estimation from a Single Image and a 3D Gaussian Splatting Model
Jul 22, 2024



We propose 6DGS to estimate the camera pose of a target RGB image given a 3D Gaussian Splatting (3DGS) model representing the scene. 6DGS avoids the iterative process typical of analysis-by-synthesis methods (e.g. iNeRF) that also require an initialization of the camera pose in order to converge. Instead, our method estimates a 6DoF pose by inverting the 3DGS rendering process. Starting from the object surface, we define a radiant Ellicell that uniformly generates rays departing from each ellipsoid that parameterize the 3DGS model. Each Ellicell ray is associated with the rendering parameters of each ellipsoid, which in turn is used to obtain the best bindings between the target image pixels and the cast rays. These pixel-ray bindings are then ranked to select the best scoring bundle of rays, which their intersection provides the camera center and, in turn, the camera rotation. The proposed solution obviates the necessity of an "a priori" pose for initialization, and it solves 6DoF pose estimation in closed form, without the need for iterations. Moreover, compared to the existing Novel View Synthesis (NVS) baselines for pose estimation, 6DGS can improve the overall average rotational accuracy by 12% and translation accuracy by 22% on real scenes, despite not requiring any initialization pose. At the same time, our method operates near real-time, reaching 15fps on consumer hardware.
IFFNeRF: Initialisation Free and Fast 6DoF pose estimation from a single image and a NeRF model
Mar 19, 2024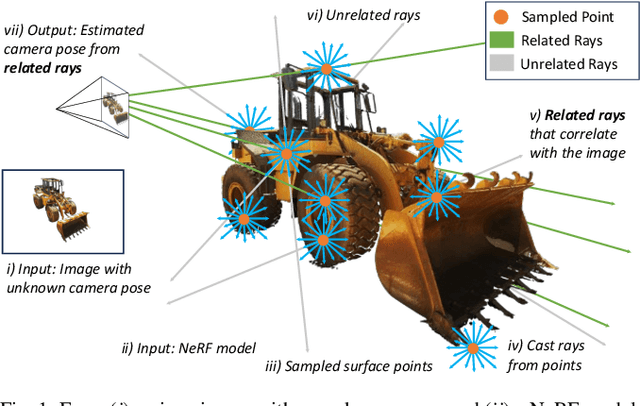
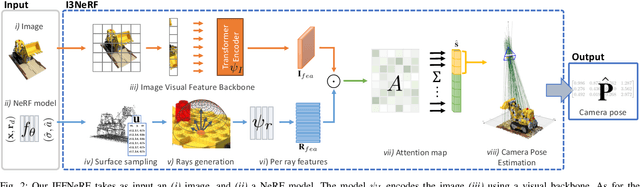
We introduce IFFNeRF to estimate the six degrees-of-freedom (6DoF) camera pose of a given image, building on the Neural Radiance Fields (NeRF) formulation. IFFNeRF is specifically designed to operate in real-time and eliminates the need for an initial pose guess that is proximate to the sought solution. IFFNeRF utilizes the Metropolis-Hasting algorithm to sample surface points from within the NeRF model. From these sampled points, we cast rays and deduce the color for each ray through pixel-level view synthesis. The camera pose can then be estimated as the solution to a Least Squares problem by selecting correspondences between the query image and the resulting bundle. We facilitate this process through a learned attention mechanism, bridging the query image embedding with the embedding of parameterized rays, thereby matching rays pertinent to the image. Through synthetic and real evaluation settings, we show that our method can improve the angular and translation error accuracy by 80.1% and 67.3%, respectively, compared to iNeRF while performing at 34fps on consumer hardware and not requiring the initial pose guess.
The MONET dataset: Multimodal drone thermal dataset recorded in rural scenarios
Apr 11, 2023
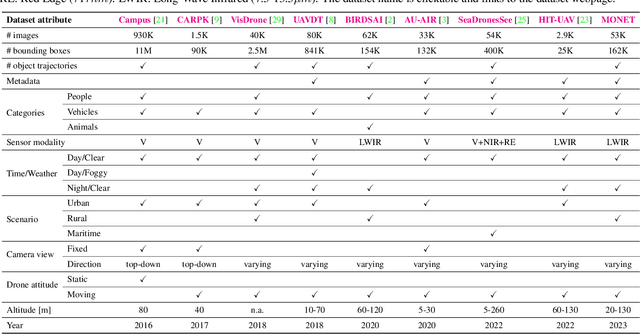
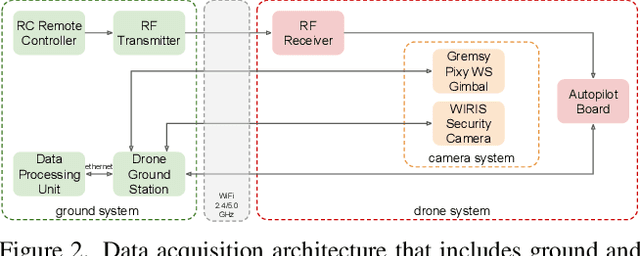
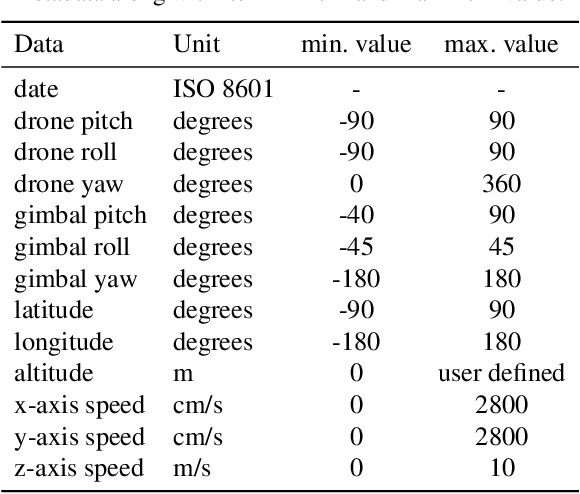
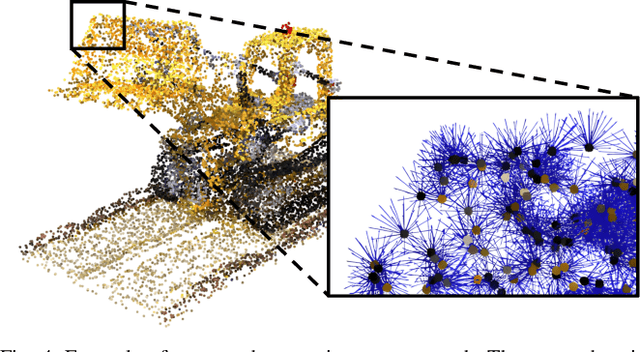
We present MONET, a new multimodal dataset captured using a thermal camera mounted on a drone that flew over rural areas, and recorded human and vehicle activities. We captured MONET to study the problem of object localisation and behaviour understanding of targets undergoing large-scale variations and being recorded from different and moving viewpoints. Target activities occur in two different land sites, each with unique scene structures and cluttered backgrounds. MONET consists of approximately 53K images featuring 162K manually annotated bounding boxes. Each image is timestamp-aligned with drone metadata that includes information about attitudes, speed, altitude, and GPS coordinates. MONET is different from previous thermal drone datasets because it features multimodal data, including rural scenes captured with thermal cameras containing both person and vehicle targets, along with trajectory information and metadata. We assessed the difficulty of the dataset in terms of transfer learning between the two sites and evaluated nine object detection algorithms to identify the open challenges associated with this type of data. Project page: https://github.com/fabiopoiesi/monet_dataset.
Data augmentation for NeRF: a geometric consistent solution based on view morphing
Oct 09, 2022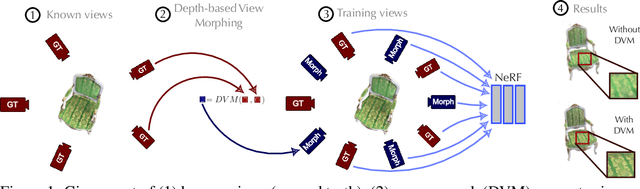

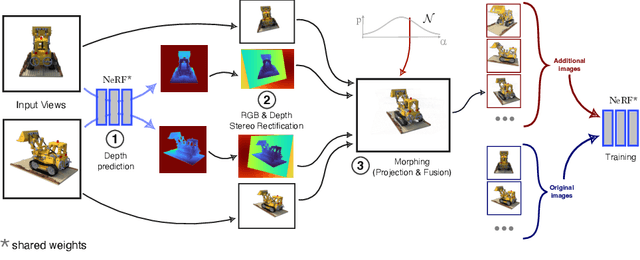

NeRF aims to learn a continuous neural scene representation by using a finite set of input images taken from different viewpoints. The fewer the number of viewpoints, the higher the likelihood of overfitting on them. This paper mitigates such limitation by presenting a novel data augmentation approach to generate geometrically consistent image transitions between viewpoints using view morphing. View morphing is a highly versatile technique that does not requires any prior knowledge about the 3D scene because it is based on general principles of projective geometry. A key novelty of our method is to use the very same depths predicted by NeRF to generate the image transitions that are then added to NeRF training. We experimentally show that this procedure enables NeRF to improve the quality of its synthesised novel views in the case of datasets with few training viewpoints. We improve PSNR up to 1.8dB and 10.5dB when eight and four views are used for training, respectively. To the best of our knowledge, this is the first data augmentation strategy for NeRF that explicitly synthesises additional new input images to improve the model generalisation.
Multi-view data capture using edge-synchronised mobiles
May 07, 2020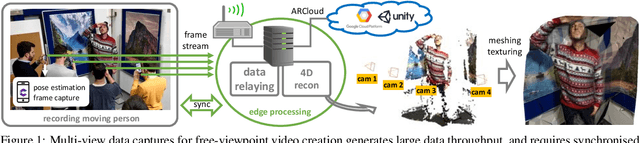
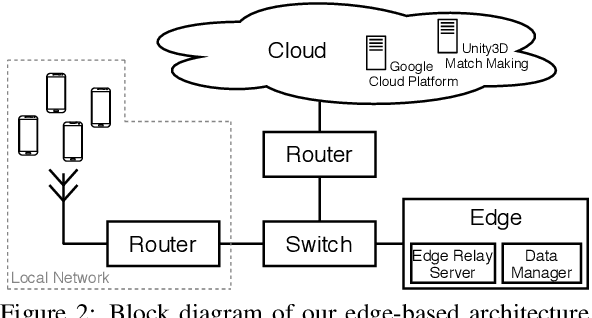

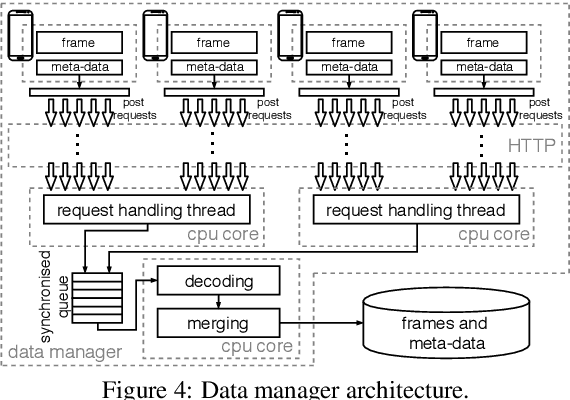
Multi-view data capture permits free-viewpoint video (FVV) content creation. To this end, several users must capture video streams, calibrated in both time and pose, framing the same object/scene, from different viewpoints. New-generation network architectures (e.g. 5G) promise lower latency and larger bandwidth connections supported by powerful edge computing, properties that seem ideal for reliable FVV capture. We have explored this possibility, aiming to remove the need for bespoke synchronisation hardware when capturing a scene from multiple viewpoints, making it possible through off-the-shelf mobiles. We propose a novel and scalable data capture architecture that exploits edge resources to synchronise and harvest frame captures. We have designed an edge computing unit that supervises the relaying of timing triggers to and from multiple mobiles, in addition to synchronising frame harvesting. We empirically show the benefits of our edge computing unit by analysing latencies and show the quality of 3D reconstruction outputs against an alternative and popular centralised solution based on Unity3D.