 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFree-form language-based robotic reasoning and grasping
Mar 17, 2025
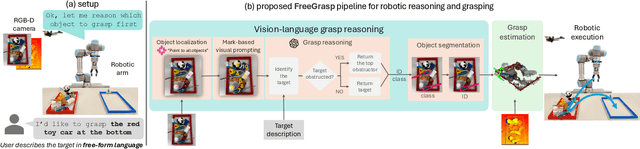


Performing robotic grasping from a cluttered bin based on human instructions is a challenging task, as it requires understanding both the nuances of free-form language and the spatial relationships between objects. Vision-Language Models (VLMs) trained on web-scale data, such as GPT-4o, have demonstrated remarkable reasoning capabilities across both text and images. But can they truly be used for this task in a zero-shot setting? And what are their limitations? In this paper, we explore these research questions via the free-form language-based robotic grasping task, and propose a novel method, FreeGrasp, leveraging the pre-trained VLMs' world knowledge to reason about human instructions and object spatial arrangements. Our method detects all objects as keypoints and uses these keypoints to annotate marks on images, aiming to facilitate GPT-4o's zero-shot spatial reasoning. This allows our method to determine whether a requested object is directly graspable or if other objects must be grasped and removed first. Since no existing dataset is specifically designed for this task, we introduce a synthetic dataset FreeGraspData by extending the MetaGraspNetV2 dataset with human-annotated instructions and ground-truth grasping sequences. We conduct extensive analyses with both FreeGraspData and real-world validation with a gripper-equipped robotic arm, demonstrating state-of-the-art performance in grasp reasoning and execution. Project website: https://tev-fbk.github.io/FreeGrasp/.
Functionality understanding and segmentation in 3D scenes
Nov 26, 2024Understanding functionalities in 3D scenes involves interpreting natural language descriptions to locate functional interactive objects, such as handles and buttons, in a 3D environment. Functionality understanding is highly challenging, as it requires both world knowledge to interpret language and spatial perception to identify fine-grained objects. For example, given a task like 'turn on the ceiling light', an embodied AI agent must infer that it needs to locate the light switch, even though the switch is not explicitly mentioned in the task description. To date, no dedicated methods have been developed for this problem. In this paper, we introduce Fun3DU, the first approach designed for functionality understanding in 3D scenes. Fun3DU uses a language model to parse the task description through Chain-of-Thought reasoning in order to identify the object of interest. The identified object is segmented across multiple views of the captured scene by using a vision and language model. The segmentation results from each view are lifted in 3D and aggregated into the point cloud using geometric information. Fun3DU is training-free, relying entirely on pre-trained models. We evaluate Fun3DU on SceneFun3D, the most recent and only dataset to benchmark this task, which comprises over 3000 task descriptions on 230 scenes. Our method significantly outperforms state-of-the-art open-vocabulary 3D segmentation approaches. Project page: https://jcorsetti.github.io/fun3du