 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFree-form language-based robotic reasoning and grasping
Mar 17, 2025
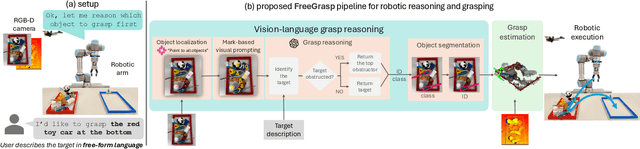


Performing robotic grasping from a cluttered bin based on human instructions is a challenging task, as it requires understanding both the nuances of free-form language and the spatial relationships between objects. Vision-Language Models (VLMs) trained on web-scale data, such as GPT-4o, have demonstrated remarkable reasoning capabilities across both text and images. But can they truly be used for this task in a zero-shot setting? And what are their limitations? In this paper, we explore these research questions via the free-form language-based robotic grasping task, and propose a novel method, FreeGrasp, leveraging the pre-trained VLMs' world knowledge to reason about human instructions and object spatial arrangements. Our method detects all objects as keypoints and uses these keypoints to annotate marks on images, aiming to facilitate GPT-4o's zero-shot spatial reasoning. This allows our method to determine whether a requested object is directly graspable or if other objects must be grasped and removed first. Since no existing dataset is specifically designed for this task, we introduce a synthetic dataset FreeGraspData by extending the MetaGraspNetV2 dataset with human-annotated instructions and ground-truth grasping sequences. We conduct extensive analyses with both FreeGraspData and real-world validation with a gripper-equipped robotic arm, demonstrating state-of-the-art performance in grasp reasoning and execution. Project website: https://tev-fbk.github.io/FreeGrasp/.
Survey on video anomaly detection in dynamic scenes with moving cameras
Aug 14, 2023The increasing popularity of compact and inexpensive cameras, e.g.~dash cameras, body cameras, and cameras equipped on robots, has sparked a growing interest in detecting anomalies within dynamic scenes recorded by moving cameras. However, existing reviews primarily concentrate on Video Anomaly Detection (VAD) methods assuming static cameras. The VAD literature with moving cameras remains fragmented, lacking comprehensive reviews to date. To address this gap, we endeavor to present the first comprehensive survey on Moving Camera Video Anomaly Detection (MC-VAD). We delve into the research papers related to MC-VAD, critically assessing their limitations and highlighting associated challenges. Our exploration encompasses three application domains: security, urban transportation, and marine environments, which in turn cover six specific tasks. We compile an extensive list of 25 publicly-available datasets spanning four distinct environments: underwater, water surface, ground, and aerial. We summarize the types of anomalies these datasets correspond to or contain, and present five main categories of approaches for detecting such anomalies. Lastly, we identify future research directions and discuss novel contributions that could advance the field of MC-VAD. With this survey, we aim to offer a valuable reference for researchers and practitioners striving to develop and advance state-of-the-art MC-VAD methods.