 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised and Generalizable Tokenization for CLIP-Based 3D Understanding
May 24, 2025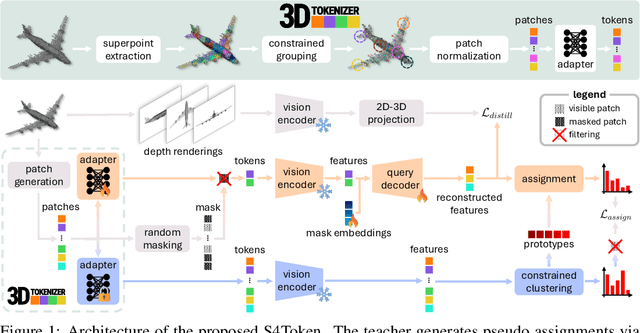


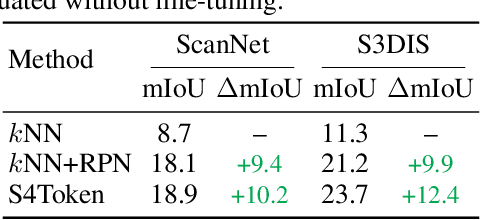
Vision-language models like CLIP can offer a promising foundation for 3D scene understanding when extended with 3D tokenizers. However, standard approaches, such as k-nearest neighbor or radius-based tokenization, struggle with cross-domain generalization due to sensitivity to dataset-specific spatial scales. We present a universal 3D tokenizer designed for scale-invariant representation learning with a frozen CLIP backbone. We show that combining superpoint-based grouping with coordinate scale normalization consistently outperforms conventional methods through extensive experimental analysis. Specifically, we introduce S4Token, a tokenization pipeline that produces semantically-informed tokens regardless of scene scale. Our tokenizer is trained without annotations using masked point modeling and clustering-based objectives, along with cross-modal distillation to align 3D tokens with 2D multi-view image features. For dense prediction tasks, we propose a superpoint-level feature propagation module to recover point-level detail from sparse tokens.
PerLA: Perceptive 3D Language Assistant
Nov 29, 2024
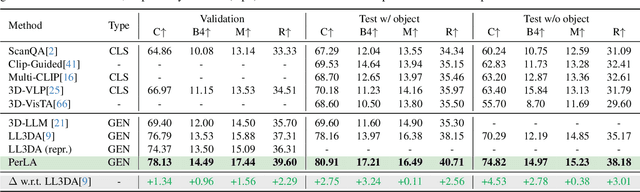
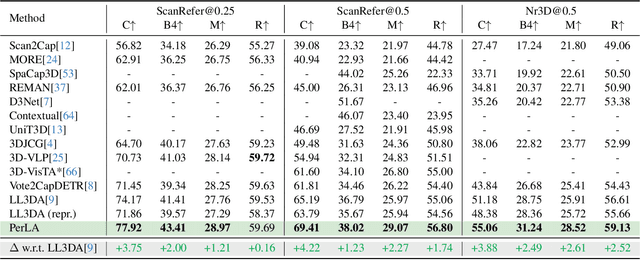

Enabling Large Language Models (LLMs) to understand the 3D physical world is an emerging yet challenging research direction. Current strategies for processing point clouds typically downsample the scene or divide it into smaller parts for separate analysis. However, both approaches risk losing key local details or global contextual information. In this paper, we introduce PerLA, a 3D language assistant designed to be more perceptive to both details and context, making visual representations more informative for the LLM. PerLA captures high-resolution (local) details in parallel from different point cloud areas and integrates them with (global) context obtained from a lower-resolution whole point cloud. We present a novel algorithm that preserves point cloud locality through the Hilbert curve and effectively aggregates local-to-global information via cross-attention and a graph neural network. Lastly, we introduce a novel loss for local representation consensus to promote training stability. PerLA outperforms state-of-the-art 3D language assistants, with gains of up to +1.34 CiDEr on ScanQA for question answering, and +4.22 on ScanRefer and +3.88 on Nr3D for dense captioning.\url{https://gfmei.github.io/PerLA/}
Vocabulary-Free 3D Instance Segmentation with Vision and Language Assistant
Aug 20, 2024



Most recent 3D instance segmentation methods are open vocabulary, offering a greater flexibility than closed-vocabulary methods. Yet, they are limited to reasoning within a specific set of concepts, \ie the vocabulary, prompted by the user at test time. In essence, these models cannot reason in an open-ended fashion, i.e., answering ``List the objects in the scene.''. We introduce the first method to address 3D instance segmentation in a setting that is void of any vocabulary prior, namely a vocabulary-free setting. We leverage a large vision-language assistant and an open-vocabulary 2D instance segmenter to discover and ground semantic categories on the posed images. To form 3D instance mask, we first partition the input point cloud into dense superpoints, which are then merged into 3D instance masks. We propose a novel superpoint merging strategy via spectral clustering, accounting for both mask coherence and semantic coherence that are estimated from the 2D object instance masks. We evaluate our method using ScanNet200 and Replica, outperforming existing methods in both vocabulary-free and open-vocabulary settings. Code will be made available.
Wild Berry image dataset collected in Finnish forests and peatlands using drones
May 15, 2024Berry picking has long-standing traditions in Finland, yet it is challenging and can potentially be dangerous. The integration of drones equipped with advanced imaging techniques represents a transformative leap forward, optimising harvests and promising sustainable practices. We propose WildBe, the first image dataset of wild berries captured in peatlands and under the canopy of Finnish forests using drones. Unlike previous and related datasets, WildBe includes new varieties of berries, such as bilberries, cloudberries, lingonberries, and crowberries, captured under severe light variations and in cluttered environments. WildBe features 3,516 images, including a total of 18,468 annotated bounding boxes. We carry out a comprehensive analysis of WildBe using six popular object detectors, assessing their effectiveness in berry detection across different forest regions and camera types. We will release WildBe publicly.
Novel class discovery meets foundation models for 3D semantic segmentation
Dec 06, 2023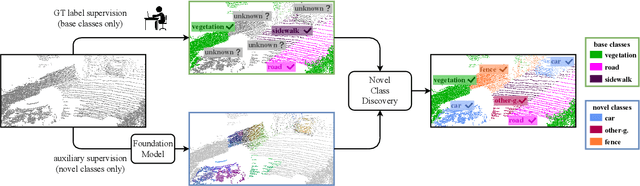

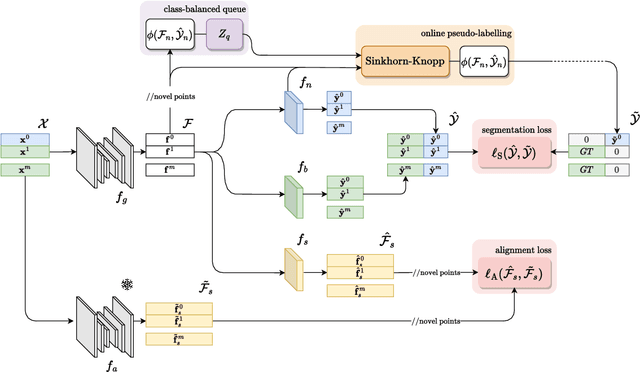

The task of Novel Class Discovery (NCD) in semantic segmentation entails training a model able to accurately segment unlabelled (novel) classes, relying on the available supervision from annotated (base) classes. Although extensively investigated in 2D image data, the extension of the NCD task to the domain of 3D point clouds represents a pioneering effort, characterized by assumptions and challenges that are not present in the 2D case. This paper represents an advancement in the analysis of point cloud data in four directions. Firstly, it introduces the novel task of NCD for point cloud semantic segmentation. Secondly, it demonstrates that directly transposing the only existing NCD method for 2D image semantic segmentation to 3D data yields suboptimal results. Thirdly, a new NCD approach based on online clustering, uncertainty estimation, and semantic distillation is presented. Lastly, a novel evaluation protocol is proposed to rigorously assess the performance of NCD in point cloud semantic segmentation. Through comprehensive evaluations on the SemanticKITTI, SemanticPOSS, and S3DIS datasets, the paper demonstrates substantial superiority of the proposed method over the considered baselines.
Geometrically-driven Aggregation for Zero-shot 3D Point Cloud Understanding
Dec 04, 2023



Zero-shot 3D point cloud understanding can be achieved via 2D Vision-Language Models (VLMs). Existing strategies directly map Vision-Language Models from 2D pixels of rendered or captured views to 3D points, overlooking the inherent and expressible point cloud geometric structure. Geometrically similar or close regions can be exploited for bolstering point cloud understanding as they are likely to share semantic information. To this end, we introduce the first training-free aggregation technique that leverages the point cloud's 3D geometric structure to improve the quality of the transferred Vision-Language Models. Our approach operates iteratively, performing local-to-global aggregation based on geometric and semantic point-level reasoning. We benchmark our approach on three downstream tasks, including classification, part segmentation, and semantic segmentation, with a variety of datasets representing both synthetic/real-world, and indoor/outdoor scenarios. Our approach achieves new state-of-the-art results in all benchmarks. We will release the source code publicly.
The MONET dataset: Multimodal drone thermal dataset recorded in rural scenarios
Apr 11, 2023
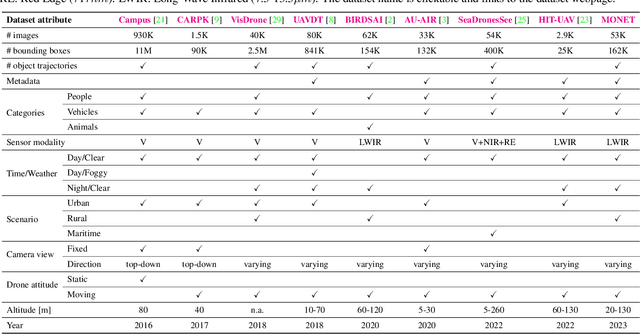
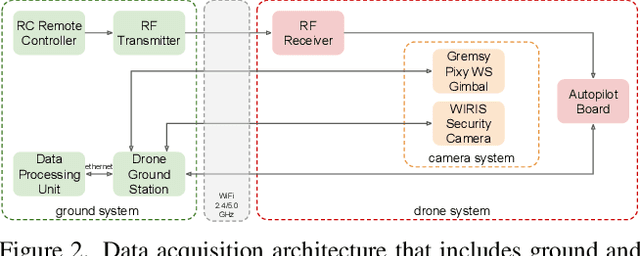
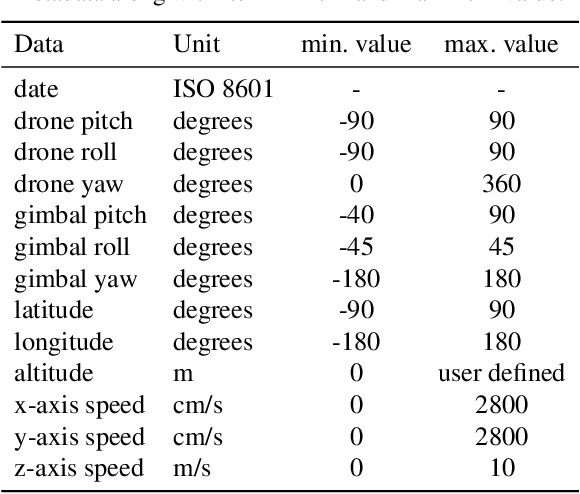
We present MONET, a new multimodal dataset captured using a thermal camera mounted on a drone that flew over rural areas, and recorded human and vehicle activities. We captured MONET to study the problem of object localisation and behaviour understanding of targets undergoing large-scale variations and being recorded from different and moving viewpoints. Target activities occur in two different land sites, each with unique scene structures and cluttered backgrounds. MONET consists of approximately 53K images featuring 162K manually annotated bounding boxes. Each image is timestamp-aligned with drone metadata that includes information about attitudes, speed, altitude, and GPS coordinates. MONET is different from previous thermal drone datasets because it features multimodal data, including rural scenes captured with thermal cameras containing both person and vehicle targets, along with trajectory information and metadata. We assessed the difficulty of the dataset in terms of transfer learning between the two sites and evaluated nine object detection algorithms to identify the open challenges associated with this type of data. Project page: https://github.com/fabiopoiesi/monet_dataset.
Novel Class Discovery for 3D Point Cloud Semantic Segmentation
Mar 21, 2023



Novel class discovery (NCD) for semantic segmentation is the task of learning a model that can segment unlabelled (novel) classes using only the supervision from labelled (base) classes. This problem has recently been pioneered for 2D image data, but no work exists for 3D point cloud data. In fact, the assumptions made for 2D are loosely applicable to 3D in this case. This paper is presented to advance the state of the art on point cloud data analysis in four directions. Firstly, we address the new problem of NCD for point cloud semantic segmentation. Secondly, we show that the transposition of the only existing NCD method for 2D semantic segmentation to 3D data is suboptimal. Thirdly, we present a new method for NCD based on online clustering that exploits uncertainty quantification to produce prototypes for pseudo-labelling the points of the novel classes. Lastly, we introduce a new evaluation protocol to assess the performance of NCD for point cloud semantic segmentation. We thoroughly evaluate our method on SemanticKITTI and SemanticPOSS datasets, showing that it can significantly outperform the baseline. Project page at this link: https://github.com/LuigiRiz/NOPS.