 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal last-iterate convergence in matrix games with bandit feedback using the log-barrier
Apr 16, 2026We study the problem of learning minimax policies in zero-sum matrix games. Fiegel et al. (2025) recently showed that achieving last-iterate convergence in this setting is harder when the players are uncoupled, by proving a lower bound on the exploitability gap of Omega(t^{-1/4}). Some online mirror descent algorithms were proposed in the literature for this problem, but none have truly attained this rate yet. We show that the use of a log-barrier regularization, along with a dual-focused analysis, allows this O-tilde(t^{-1/4}) convergence with high-probability. We additionally extend our idea to the setting of extensive-form games, proving a bound with the same rate.
Where-to-Unmask: Ground-Truth-Guided Unmasking Order Learning for Masked Diffusion Language Models
Feb 10, 2026Masked Diffusion Language Models (MDLMs) generate text by iteratively filling masked tokens, requiring two coupled decisions at each step: which positions to unmask (where-to-unmask) and which tokens to place (what-to-unmask). While standard MDLM training directly optimizes token prediction (what-to-unmask), inference-time unmasking orders (where-to-unmask) are typically determined by heuristic confidence measures or trained through reinforcement learning with costly on-policy rollouts. To address this, we introduce Gt-Margin, a position-wise score derived from ground-truth tokens, defined as the probability margin between the correct token and its strongest alternative. Gt-Margin yields an oracle unmasking order that prioritizes easier positions first under each partially masked state. We demonstrate that leveraging this oracle unmasking order significantly enhances final generation quality, particularly on logical reasoning benchmarks. Building on this insight, we train a supervised unmasking planner via learning-to-rank to imitate the oracle ordering from masked contexts. The resulting planner integrates into standard MDLM sampling to select where-to-unmask, improving reasoning accuracy without modifying the token prediction model.
Am I More Pointwise or Pairwise? Revealing Position Bias in Rubric-Based LLM-as-a-Judge
Feb 02, 2026Large language models (LLMs) are now widely used to evaluate the quality of text, a field commonly referred to as LLM-as-a-judge. While prior works mainly focus on point-wise and pair-wise evaluation paradigms. Rubric-based evaluation, where LLMs select a score from multiple rubrics, has received less analysis. In this work, we show that rubric-based evaluation implicitly resembles a multi-choice setting and therefore has position bias: LLMs prefer score options appearing at specific positions in the rubric list. Through controlled experiments across multiple models and datasets, we demonstrate consistent position bias. To mitigate this bias, we propose a balanced permutation strategy that evenly distributes each score option across positions. We show that aggregating scores across balanced permutations not only reveals latent position bias, but also improves correlation between the LLM-as-a-Judge and human. Our results suggest that rubric-based LLM-as-a-Judge is not inherently point-wise and that simple permutation-based calibration can substantially improve its reliability.
WarrantScore: Modeling Warrants between Claims and Evidence for Substantiation Evaluation in Peer Reviews
Jan 24, 2026The scientific peer-review process is facing a shortage of human resources due to the rapid growth in the number of submitted papers. The use of language models to reduce the human cost of peer review has been actively explored as a potential solution to this challenge. A method has been proposed to evaluate the level of substantiation in scientific reviews in a manner that is interpretable by humans. This method extracts the core components of an argument, claims and evidence, and assesses the level of substantiation based on the proportion of claims supported by evidence. The level of substantiation refers to the extent to which claims are based on objective facts. However, when assessing the level of substantiation, simply detecting the presence or absence of supporting evidence for a claim is insufficient; it is also necessary to accurately assess the logical inference between a claim and its evidence. We propose a new evaluation metric for scientific review comments that assesses the logical inference between claims and evidence. Experimental results show that the proposed method achieves a higher correlation with human scores than conventional methods, indicating its potential to better support the efficiency of the peer-review process.
Symmetry-Breaking in Multi-Agent Navigation: Winding Number-Aware MPC with a Learned Topological Strategy
Nov 19, 2025We address the fundamental challenge of resolving symmetry-induced deadlocks in distributed multi-agent navigation by proposing a new hierarchical navigation method. When multiple agents interact, it is inherently difficult for them to autonomously break the symmetry of deciding how to pass each other. To tackle this problem, we introduce an approach that quantifies cooperative symmetry-breaking strategies using a topological invariant called the winding number, and learns the strategies themselves through reinforcement learning. Our method features a hierarchical policy consisting of a learning-based Planner, which plans topological cooperative strategies, and a model-based Controller, which executes them. Through reinforcement learning, the Planner learns to produce two types of parameters for the Controller: one is the topological cooperative strategy represented by winding numbers, and the other is a set of dynamic weights that determine which agent interaction to prioritize in dense scenarios where multiple agents cross simultaneously. The Controller then generates collision-free and efficient motions based on the strategy and weights provided by the Planner. This hierarchical structure combines the flexible decision-making ability of learning-based methods with the reliability of model-based approaches. Simulation and real-world robot experiments demonstrate that our method outperforms existing baselines, particularly in dense environments, by efficiently avoiding collisions and deadlocks while achieving superior navigation performance. The code for the experiments is available at https://github.com/omron-sinicx/WNumMPC.
Self Iterative Label Refinement via Robust Unlabeled Learning
Feb 18, 2025Recent advances in large language models (LLMs) have yielded impressive performance on various tasks, yet they often depend on high-quality feedback that can be costly. Self-refinement methods attempt to leverage LLMs' internal evaluation mechanisms with minimal human supervision; however, these approaches frequently suffer from inherent biases and overconfidence, especially in domains where the models lack sufficient internal knowledge, resulting in performance degradation. As an initial step toward enhancing self-refinement for broader applications, we introduce an iterative refinement pipeline that employs the Unlabeled-Unlabeled learning framework to improve LLM-generated pseudo-labels for classification tasks. By exploiting two unlabeled datasets with differing positive class ratios, our approach iteratively denoises and refines the initial pseudo-labels, thereby mitigating the adverse effects of internal biases with minimal human supervision. Evaluations on diverse datasets, including low-resource language corpora, patent classifications, and protein structure categorizations, demonstrate that our method consistently outperforms both initial LLM's classification performance and the self-refinement approaches by cutting-edge models (e.g., GPT-4o and DeepSeek-R1).
Near-Optimal Policy Identification in Robust Constrained Markov Decision Processes via Epigraph Form
Sep 02, 2024


Designing a safe policy for uncertain environments is crucial in real-world control applications. However, this challenge remains inadequately addressed within the Markov decision process (MDP) framework. This paper presents the first algorithm capable of identifying a near-optimal policy in a robust constrained MDP (RCMDP), where an optimal policy minimizes cumulative cost while satisfying constraints in the worst-case scenario across a set of environments. We first prove that the conventional Lagrangian max-min formulation with policy gradient methods can become trapped in suboptimal solutions by encountering a sum of conflicting gradients from the objective and constraint functions during its inner minimization problem. To address this, we leverage the epigraph form of the RCMDP problem, which resolves the conflict by selecting a single gradient from either the objective or the constraints. Building on the epigraph form, we propose a binary search algorithm with a policy gradient subroutine and prove that it identifies an $\varepsilon$-optimal policy in an RCMDP with $\tilde{\mathcal{O}}(\varepsilon^{-4})$ policy evaluations.
Symmetry-aware Reinforcement Learning for Robotic Assembly under Partial Observability with a Soft Wrist
Feb 28, 2024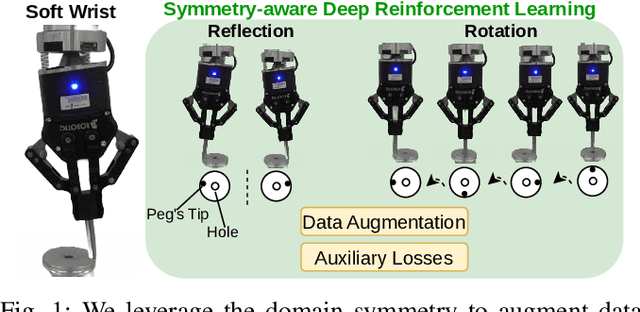
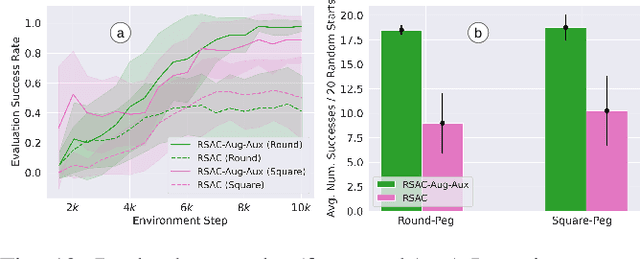
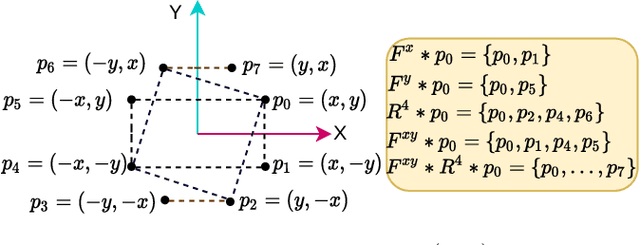
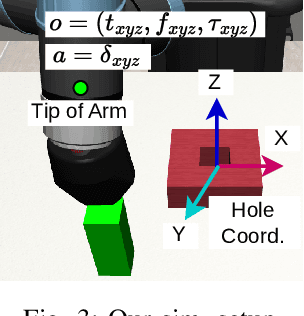
This study tackles the representative yet challenging contact-rich peg-in-hole task of robotic assembly, using a soft wrist that can operate more safely and tolerate lower-frequency control signals than a rigid one. Previous studies often use a fully observable formulation, requiring external setups or estimators for the peg-to-hole pose. In contrast, we use a partially observable formulation and deep reinforcement learning from demonstrations to learn a memory-based agent that acts purely on haptic and proprioceptive signals. Moreover, previous works do not incorporate potential domain symmetry and thus must search for solutions in a bigger space. Instead, we propose to leverage the symmetry for sample efficiency by augmenting the training data and constructing auxiliary losses to force the agent to adhere to the symmetry. Results in simulation with five different symmetric peg shapes show that our proposed agent can be comparable to or even outperform a state-based agent. In particular, the sample efficiency also allows us to learn directly on the real robot within 3 hours.
A Policy Gradient Primal-Dual Algorithm for Constrained MDPs with Uniform PAC Guarantees
Feb 02, 2024

We study a primal-dual reinforcement learning (RL) algorithm for the online constrained Markov decision processes (CMDP) problem, wherein the agent explores an optimal policy that maximizes return while satisfying constraints. Despite its widespread practical use, the existing theoretical literature on primal-dual RL algorithms for this problem only provides sublinear regret guarantees and fails to ensure convergence to optimal policies. In this paper, we introduce a novel policy gradient primal-dual algorithm with uniform probably approximate correctness (Uniform-PAC) guarantees, simultaneously ensuring convergence to optimal policies, sublinear regret, and polynomial sample complexity for any target accuracy. Notably, this represents the first Uniform-PAC algorithm for the online CMDP problem. In addition to the theoretical guarantees, we empirically demonstrate in a simple CMDP that our algorithm converges to optimal policies, while an existing algorithm exhibits oscillatory performance and constraint violation.
Multi-Agent Behavior Retrieval
Dec 04, 2023This paper aims to enable multi-agent systems to effectively utilize past memories to adapt to novel collaborative tasks in a data-efficient fashion. We propose the Multi-Agent Coordination Skill Database, a repository for storing a collection of coordinated behaviors associated with the key vector distinctive to them. Our Transformer-based skill encoder effectively captures spatio-temporal interactions that contribute to coordination and provide a skill representation unique to each coordinated behavior. By leveraging a small number of demonstrations of the target task, the database allows us to train the policy using a dataset augmented with the retrieved demonstrations. Experimental evaluations clearly demonstrate that our method achieves a significantly higher success rate in push manipulation tasks compared to baseline methods like few-shot imitation learning. Furthermore, we validate the effectiveness of our retrieve-and-learn framework in a real environment using a team of wheeled robots.