 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulation-Driven Evolutionary Motion Parameterization for Contact-Rich Granular Scooping with a Soft Conical Robotic Hand
Apr 07, 2026Tool-based scooping is vital in robot-assisted tasks, enabling interaction with objects of varying sizes, shapes, and material states. Recent studies have shown that flexible, reconfigurable soft robotic end-effectors can adapt their shape to maintain consistent contact with container surfaces during scooping, improving efficiency compared to rigid tools. These soft tools can adjust to varying container sizes and materials without requiring complex sensing or control. However, the inherent compliance and complex deformation behavior of soft robotics introduce significant control complexity that limits practical applications. To address this challenge, this paper presents the development of a physics-based simulation model of a deformable soft conical robotic hand that captures its passive reconfiguration dynamics and enables systematic trajectory optimization for scooping tasks. We propose a novel physics-based simulation approach that accurately models the soft tool's morphing behavior from flat sheets to adaptive conical structures, combined with an evolutionary strategy framework that automatically optimizes scooping trajectories without manual parameter tuning. We validate the optimized trajectories through both simulation and real-robot experiments. The results demonstrate strong generalization and successfully address a range of challenging tasks previously beyond the reach of existing approaches. Videos of our experiments are available online: https://sites.google.com/view/scoopsh
A Soft Wrist with Anisotropic and Selectable Stiffness for Robust Robot Learning in Contact-rich Manipulation
Feb 16, 2026Contact-rich manipulation tasks in unstructured environments pose significant robustness challenges for robot learning, where unexpected collisions can cause damage and hinder policy acquisition. Existing soft end-effectors face fundamental limitations: they either provide a limited deformation range, lack directional stiffness control, or require complex actuation systems that compromise practicality. This study introduces CLAW (Compliant Leaf-spring Anisotropic soft Wrist), a novel soft wrist mechanism that addresses these limitations through a simple yet effective design using two orthogonal leaf springs and rotary joints with a locking mechanism. CLAW provides large 6-degree-of-freedom deformation (40mm lateral, 20mm vertical), anisotropic stiffness that is tunable across three distinct modes, while maintaining lightweight construction (330g) at low cost ($550). Experimental evaluations using imitation learning demonstrate that CLAW achieves 76% success rate in benchmark peg-insertion tasks, outperforming both the Fin Ray gripper (43%) and rigid gripper alternatives (36%). CLAW successfully handles diverse contact-rich scenarios, including precision assembly with tight tolerances and delicate object manipulation, demonstrating its potential to enable robust robot learning in contact-rich domains. Project page: https://project-page-manager.github.io/CLAW/
Tactile Memory with Soft Robot: Robust Object Insertion via Masked Encoding and Soft Wrist
Jan 27, 2026Tactile memory, the ability to store and retrieve touch-based experience, is critical for contact-rich tasks such as key insertion under uncertainty. To replicate this capability, we introduce Tactile Memory with Soft Robot (TaMeSo-bot), a system that integrates a soft wrist with tactile retrieval-based control to enable safe and robust manipulation. The soft wrist allows safe contact exploration during data collection, while tactile memory reuses past demonstrations via retrieval for flexible adaptation to unseen scenarios. The core of this system is the Masked Tactile Trajectory Transformer (MAT$^\text{3}$), which jointly models spatiotemporal interactions between robot actions, distributed tactile feedback, force-torque measurements, and proprioceptive signals. Through masked-token prediction, MAT$^\text{3}$ learns rich spatiotemporal representations by inferring missing sensory information from context, autonomously extracting task-relevant features without explicit subtask segmentation. We validate our approach on peg-in-hole tasks with diverse pegs and conditions in real-robot experiments. Our extensive evaluation demonstrates that MAT$^\text{3}$ achieves higher success rates than the baselines over all conditions and shows remarkable capability to adapt to unseen pegs and conditions.
Stable In-hand Manipulation for a Lightweight Four-motor Prosthetic Hand
Jan 12, 2026Electric prosthetic hands should be lightweight to decrease the burden on the user, shaped like human hands for cosmetic purposes, and designed with motors enclosed inside to protect them from damage and dirt. Additionally, in-hand manipulation is necessary to perform daily activities such as transitioning between different postures, particularly through rotational movements, such as reorienting a pen into a writing posture after picking it up from a desk. We previously developed PLEXUS hand (Precision-Lateral dEXteroUS manipulation hand), a lightweight (311 g) prosthetic hand driven by four motors. This prosthetic performed reorientation between precision and lateral grasps with various objects. However, its controller required predefined object widths and was limited to handling lightweight objects (of weight up to 34 g). This study addresses these limitations by employing motor current feedback. Combined with the hand's previously optimized single-axis thumb, this approach achieves more stable manipulation by estimating the object's width and adjusting the index finger position to maintain stable object holding during the reorientation. Experimental validation using primitive objects of various widths (5-30 mm) and shapes (cylinders and prisms) resulted in a 100% success rate with lightweight objects and maintained a high success rate (>=80) even with heavy aluminum prisms (of weight up to 289 g). By contrast, the performance without index finger coordination dropped to just 40% on the heaviest 289 g prism. The hand also successfully executed several daily tasks, including closing bottle caps and orienting a pen for writing.
SCU-Hand: Soft Conical Universal Robotic Hand for Scooping Granular Media from Containers of Various Sizes
May 07, 2025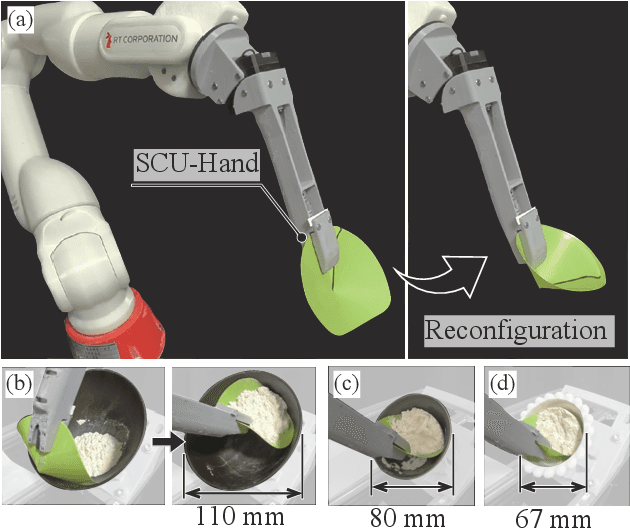
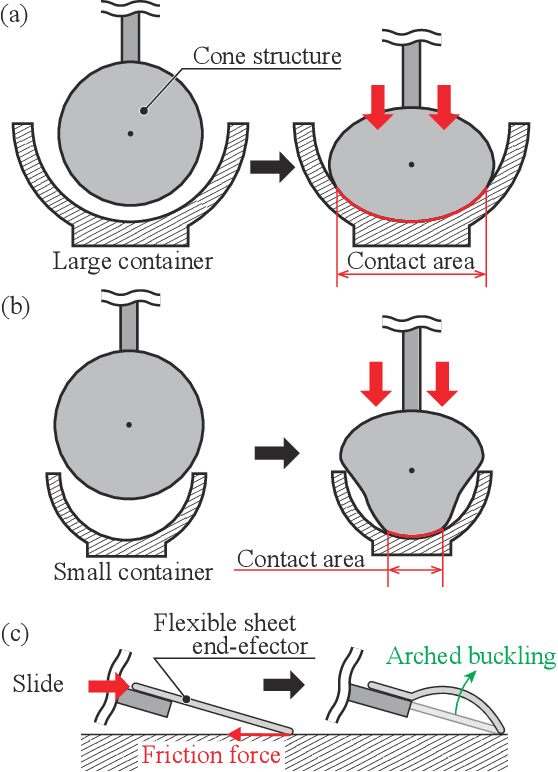
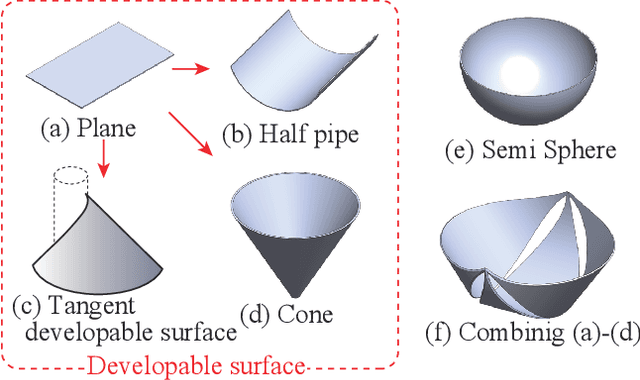
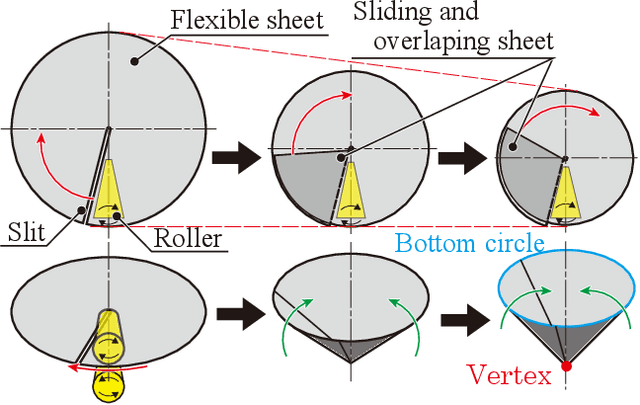
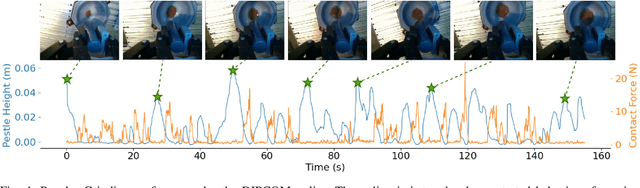
Automating small-scale experiments in materials science presents challenges due to the heterogeneous nature of experimental setups. This study introduces the SCU-Hand (Soft Conical Universal Robot Hand), a novel end-effector designed to automate the task of scooping powdered samples from various container sizes using a robotic arm. The SCU-Hand employs a flexible, conical structure that adapts to different container geometries through deformation, maintaining consistent contact without complex force sensing or machine learning-based control methods. Its reconfigurable mechanism allows for size adjustment, enabling efficient scooping from diverse container types. By combining soft robotics principles with a sheet-morphing design, our end-effector achieves high flexibility while retaining the necessary stiffness for effective powder manipulation. We detail the design principles, fabrication process, and experimental validation of the SCU-Hand. Experimental validation showed that the scooping capacity is about 20% higher than that of a commercial tool, with a scooping performance of more than 95% for containers of sizes between 67 mm to 110 mm. This research contributes to laboratory automation by offering a cost-effective, easily implementable solution for automating tasks such as materials synthesis and characterization processes.
KeyMPs: One-Shot Vision-Language Guided Motion Generation by Sequencing DMPs for Occlusion-Rich Tasks
Apr 14, 2025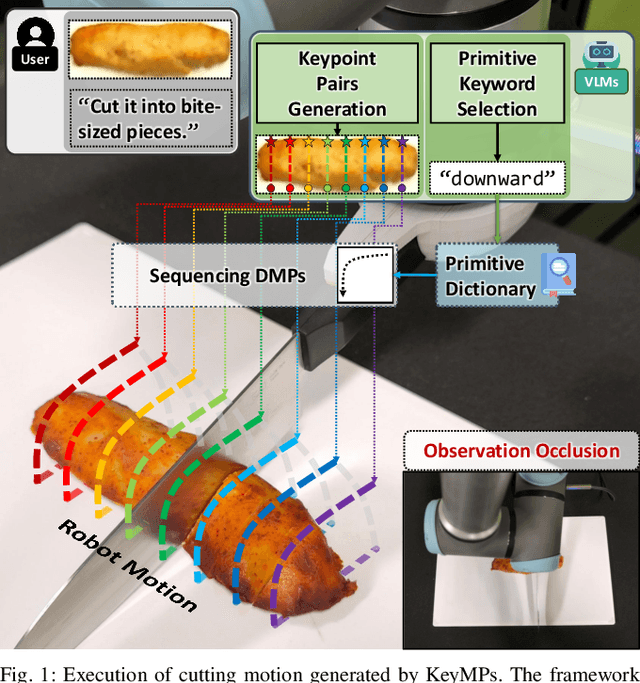
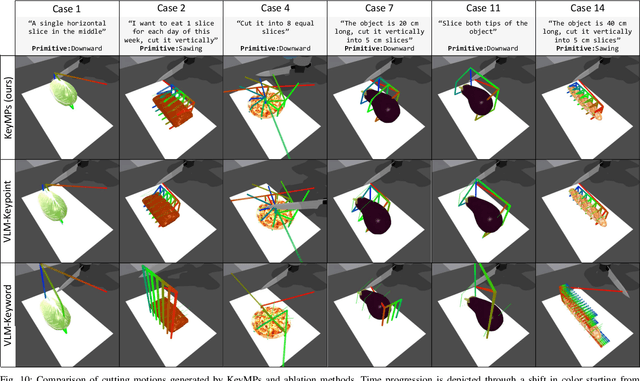
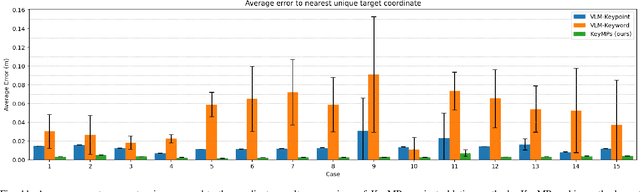
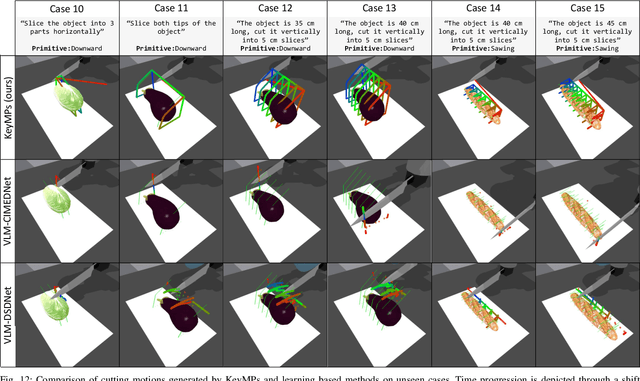
Dynamic Movement Primitives (DMPs) provide a flexible framework wherein smooth robotic motions are encoded into modular parameters. However, they face challenges in integrating multimodal inputs commonly used in robotics like vision and language into their framework. To fully maximize DMPs' potential, enabling them to handle multimodal inputs is essential. In addition, we also aim to extend DMPs' capability to handle object-focused tasks requiring one-shot complex motion generation, as observation occlusion could easily happen mid-execution in such tasks (e.g., knife occlusion in cake icing, hand occlusion in dough kneading, etc.). A promising approach is to leverage Vision-Language Models (VLMs), which process multimodal data and can grasp high-level concepts. However, they typically lack enough knowledge and capabilities to directly infer low-level motion details and instead only serve as a bridge between high-level instructions and low-level control. To address this limitation, we propose Keyword Labeled Primitive Selection and Keypoint Pairs Generation Guided Movement Primitives (KeyMPs), a framework that combines VLMs with sequencing of DMPs. KeyMPs use VLMs' high-level reasoning capability to select a reference primitive through keyword labeled primitive selection and VLMs' spatial awareness to generate spatial scaling parameters used for sequencing DMPs by generalizing the overall motion through keypoint pairs generation, which together enable one-shot vision-language guided motion generation that aligns with the intent expressed in the multimodal input. We validate our approach through an occlusion-rich manipulation task, specifically object cutting experiments in both simulated and real-world environments, demonstrating superior performance over other DMP-based methods that integrate VLMs support.
Learning Diffusion Policies from Demonstrations For Compliant Contact-rich Manipulation
Oct 25, 2024
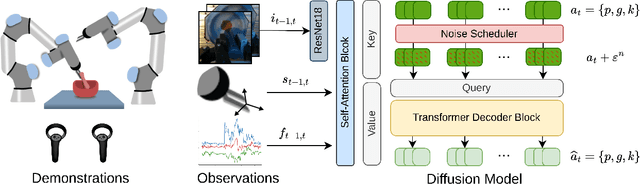

Robots hold great promise for performing repetitive or hazardous tasks, but achieving human-like dexterity, especially in contact-rich and dynamic environments, remains challenging. Rigid robots, which rely on position or velocity control, often struggle with maintaining stable contact and applying consistent force in force-intensive tasks. Learning from Demonstration has emerged as a solution, but tasks requiring intricate maneuvers, such as powder grinding, present unique difficulties. This paper introduces Diffusion Policies For Compliant Manipulation (DIPCOM), a novel diffusion-based framework designed for compliant control tasks. By leveraging generative diffusion models, we develop a policy that predicts Cartesian end-effector poses and adjusts arm stiffness to maintain the necessary force. Our approach enhances force control through multimodal distribution modeling, improves the integration of diffusion policies in compliance control, and extends our previous work by demonstrating its effectiveness in real-world tasks. We present a detailed comparison between our framework and existing methods, highlighting the advantages and best practices for deploying diffusion-based compliance control.
Visuo-Tactile Zero-Shot Object Recognition with Vision-Language Model
Sep 14, 2024
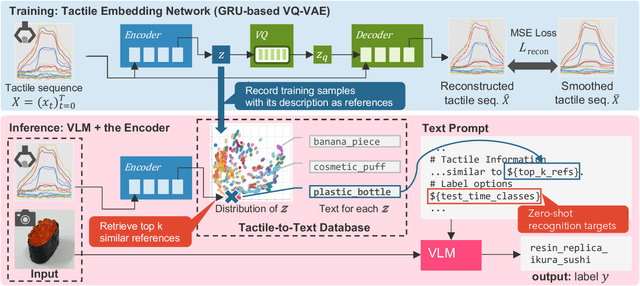
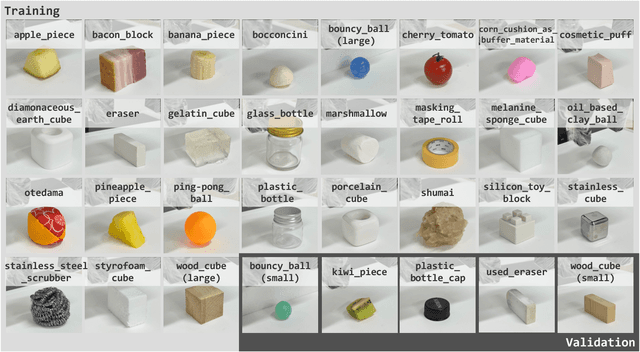
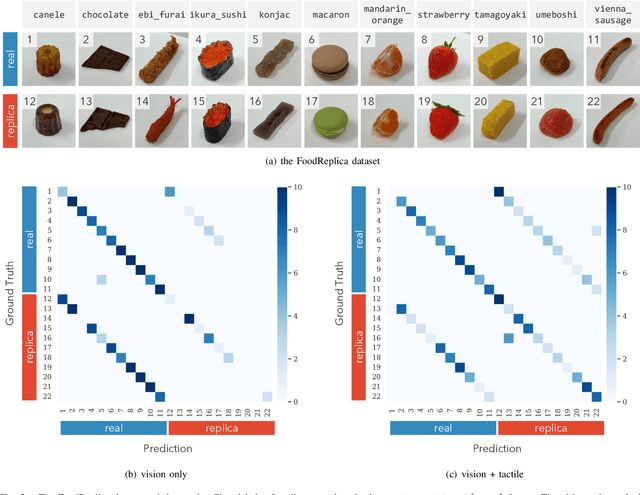
Tactile perception is vital, especially when distinguishing visually similar objects. We propose an approach to incorporate tactile data into a Vision-Language Model (VLM) for visuo-tactile zero-shot object recognition. Our approach leverages the zero-shot capability of VLMs to infer tactile properties from the names of tactilely similar objects. The proposed method translates tactile data into a textual description solely by annotating object names for each tactile sequence during training, making it adaptable to various contexts with low training costs. The proposed method was evaluated on the FoodReplica and Cube datasets, demonstrating its effectiveness in recognizing objects that are difficult to distinguish by vision alone.
Near-Optimal Policy Identification in Robust Constrained Markov Decision Processes via Epigraph Form
Sep 02, 2024


Designing a safe policy for uncertain environments is crucial in real-world control applications. However, this challenge remains inadequately addressed within the Markov decision process (MDP) framework. This paper presents the first algorithm capable of identifying a near-optimal policy in a robust constrained MDP (RCMDP), where an optimal policy minimizes cumulative cost while satisfying constraints in the worst-case scenario across a set of environments. We first prove that the conventional Lagrangian max-min formulation with policy gradient methods can become trapped in suboptimal solutions by encountering a sum of conflicting gradients from the objective and constraint functions during its inner minimization problem. To address this, we leverage the epigraph form of the RCMDP problem, which resolves the conflict by selecting a single gradient from either the objective or the constraints. Building on the epigraph form, we propose a binary search algorithm with a policy gradient subroutine and prove that it identifies an $\varepsilon$-optimal policy in an RCMDP with $\tilde{\mathcal{O}}(\varepsilon^{-4})$ policy evaluations.
Robotic Object Insertion with a Soft Wrist through Sim-to-Real Privileged Training
Aug 30, 2024



This study addresses contact-rich object insertion tasks under unstructured environments using a robot with a soft wrist, enabling safe contact interactions. For the unstructured environments, we assume that there are uncertainties in object grasp and hole pose and that the soft wrist pose cannot be directly measured. Recent methods employ learning approaches and force/torque sensors for contact localization; however, they require data collection in the real world. This study proposes a sim-to-real approach using a privileged training strategy. This method has two steps. 1) The teacher policy is trained to complete the task with sensor inputs and ground truth privileged information such as the peg pose, and then 2) the student encoder is trained with data produced from teacher policy rollouts to estimate the privileged information from sensor history. We performed sim-to-real experiments under grasp and hole pose uncertainties. This resulted in 100\%, 95\%, and 80\% success rates for circular peg insertion with 0, +5, and -5 degree peg misalignments, respectively, and start positions randomly shifted $\pm$ 10 mm from a default position. Also, we tested the proposed method with a square peg that was never seen during training. Additional simulation evaluations revealed that using the privileged strategy improved success rates compared to training with only simulated sensor data. Our results demonstrate the advantage of using sim-to-real privileged training for soft robots, which has the potential to alleviate human engineering efforts for robotic assembly.