 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobotic Object Insertion with a Soft Wrist through Sim-to-Real Privileged Training
Aug 30, 2024



This study addresses contact-rich object insertion tasks under unstructured environments using a robot with a soft wrist, enabling safe contact interactions. For the unstructured environments, we assume that there are uncertainties in object grasp and hole pose and that the soft wrist pose cannot be directly measured. Recent methods employ learning approaches and force/torque sensors for contact localization; however, they require data collection in the real world. This study proposes a sim-to-real approach using a privileged training strategy. This method has two steps. 1) The teacher policy is trained to complete the task with sensor inputs and ground truth privileged information such as the peg pose, and then 2) the student encoder is trained with data produced from teacher policy rollouts to estimate the privileged information from sensor history. We performed sim-to-real experiments under grasp and hole pose uncertainties. This resulted in 100\%, 95\%, and 80\% success rates for circular peg insertion with 0, +5, and -5 degree peg misalignments, respectively, and start positions randomly shifted $\pm$ 10 mm from a default position. Also, we tested the proposed method with a square peg that was never seen during training. Additional simulation evaluations revealed that using the privileged strategy improved success rates compared to training with only simulated sensor data. Our results demonstrate the advantage of using sim-to-real privileged training for soft robots, which has the potential to alleviate human engineering efforts for robotic assembly.
An Electromagnetism-Inspired Method for Estimating In-Grasp Torque from Visuotactile Sensors
Apr 24, 2024



Tactile sensing has become a popular sensing modality for robot manipulators, due to the promise of providing robots with the ability to measure the rich contact information that gets transmitted through its sense of touch. Among the diverse range of information accessible from tactile sensors, torques transmitted from the grasped object to the fingers through extrinsic environmental contact may be particularly important for tasks such as object insertion. However, tactile torque estimation has received relatively little attention when compared to other sensing modalities, such as force, texture, or slip identification. In this work, we introduce the notion of the Tactile Dipole Moment, which we use to estimate tilt torques from gel-based visuotactile sensors. This method does not rely on deep learning, sensor-specific mechanical, or optical modeling, and instead takes inspiration from electromechanics to analyze the vector field produced from 2D marker displacements. Despite the simplicity of our technique, we demonstrate its ability to provide accurate torque readings over two different tactile sensors and three object geometries, and highlight its practicality for the task of USB stick insertion with a compliant robot arm. These results suggest that simple analytical calculations based on dipole moments can sufficiently extract physical quantities from visuotactile sensors.
OPT-Mimic: Imitation of Optimized Trajectories for Dynamic Quadruped Behaviors
Oct 03, 2022
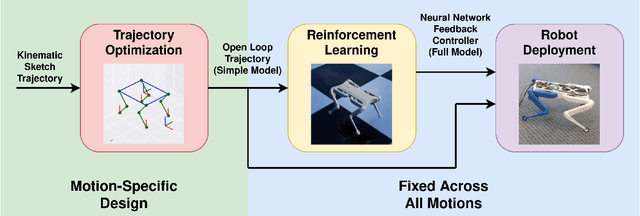

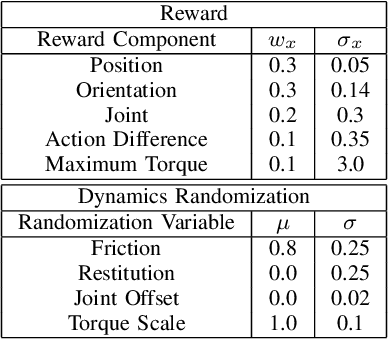
Reinforcement Learning (RL) has seen many recent successes for quadruped robot control. The imitation of reference motions provides a simple and powerful prior for guiding solutions towards desired solutions without the need for meticulous reward design. While much work uses motion capture data or hand-crafted trajectories as the reference motion, relatively little work has explored the use of reference motions coming from model-based trajectory optimization. In this work, we investigate several design considerations that arise with such a framework, as demonstrated through four dynamic behaviours: trot, front hop, 180 backflip, and biped stepping. These are trained in simulation and transferred to a physical Solo 8 quadruped robot without further adaptation. In particular, we explore the space of feed-forward designs afforded by the trajectory optimizer to understand its impact on RL learning efficiency and sim-to-real transfer. These findings contribute to the long standing goal of producing robot controllers that combine the interpretability and precision of model-based optimization with the robustness that model-free RL-based controllers offer.