 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotion-Aware Classroom Quality Assessment Leveraging IoT-Based Real-Time Student Monitoring
Mar 17, 2026This study presents high-throughput, real-time multi-agent affective computing framework designed to enhance classroom learning through emotional state monitoring. As large classroom sizes and limited teacher student interaction increasingly challenge educators, there is a growing need for scalable, data-driven tools capable of capturing students' emotional and engagement patterns in real time. The system was evaluated using the Classroom Emotion Dataset, consisting of 1,500 labeled images and 300 classroom detection videos. Tailored for IoT devices, the system addresses load balancing and latency challenges through efficient real-time processing. Field testing was conducted across three educational institutions in a large metropolitan area: a primary school (hereafter school A), a secondary school (school B), and a high school (school C). The system demonstrated robust performance, detecting up to 50 faces at 25 FPS and achieving 88% overall accuracy in classifying classroom engagement states. Implementation results showed positive outcomes, with favorable feedback from students, teachers, and parents regarding improved classroom interaction and teaching adaptation. Key contributions of this research include establishing a practical, IoT-based framework for emotion-aware learning environments and introducing the 'Classroom Emotion Dataset' to facilitate further validation and research.
LiveNeRF: Efficient Face Replacement Through Neural Radiance Fields Integration
Nov 10, 2025Face replacement technology enables significant advancements in entertainment, education, and communication applications, including dubbing, virtual avatars, and cross-cultural content adaptation. Our LiveNeRF framework addresses critical limitations of existing methods by achieving real-time performance (33 FPS) with superior visual quality, enabling practical deployment in live streaming, video conferencing, and interactive media. The technology particularly benefits content creators, educators, and individuals with speech impairments through accessible avatar communication. While acknowledging potential misuse in unauthorized deepfake creation, we advocate for responsible deployment with user consent verification and integration with detection systems to ensure positive societal impact while minimizing risks.
Lightspeed Geometric Dataset Distance via Sliced Optimal Transport
Jan 31, 2025



We introduce sliced optimal transport dataset distance (s-OTDD), a model-agnostic, embedding-agnostic approach for dataset comparison that requires no training, is robust to variations in the number of classes, and can handle disjoint label sets. The core innovation is Moment Transform Projection (MTP), which maps a label, represented as a distribution over features, to a real number. Using MTP, we derive a data point projection that transforms datasets into one-dimensional distributions. The s-OTDD is defined as the expected Wasserstein distance between the projected distributions, with respect to random projection parameters. Leveraging the closed form solution of one-dimensional optimal transport, s-OTDD achieves (near-)linear computational complexity in the number of data points and feature dimensions and is independent of the number of classes. With its geometrically meaningful projection, s-OTDD strongly correlates with the optimal transport dataset distance while being more efficient than existing dataset discrepancy measures. Moreover, it correlates well with the performance gap in transfer learning and classification accuracy in data augmentation.
Robotic Object Insertion with a Soft Wrist through Sim-to-Real Privileged Training
Aug 30, 2024



This study addresses contact-rich object insertion tasks under unstructured environments using a robot with a soft wrist, enabling safe contact interactions. For the unstructured environments, we assume that there are uncertainties in object grasp and hole pose and that the soft wrist pose cannot be directly measured. Recent methods employ learning approaches and force/torque sensors for contact localization; however, they require data collection in the real world. This study proposes a sim-to-real approach using a privileged training strategy. This method has two steps. 1) The teacher policy is trained to complete the task with sensor inputs and ground truth privileged information such as the peg pose, and then 2) the student encoder is trained with data produced from teacher policy rollouts to estimate the privileged information from sensor history. We performed sim-to-real experiments under grasp and hole pose uncertainties. This resulted in 100\%, 95\%, and 80\% success rates for circular peg insertion with 0, +5, and -5 degree peg misalignments, respectively, and start positions randomly shifted $\pm$ 10 mm from a default position. Also, we tested the proposed method with a square peg that was never seen during training. Additional simulation evaluations revealed that using the privileged strategy improved success rates compared to training with only simulated sensor data. Our results demonstrate the advantage of using sim-to-real privileged training for soft robots, which has the potential to alleviate human engineering efforts for robotic assembly.
Equivariant Reinforcement Learning under Partial Observability
Aug 26, 2024Incorporating inductive biases is a promising approach for tackling challenging robot learning domains with sample-efficient solutions. This paper identifies partially observable domains where symmetries can be a useful inductive bias for efficient learning. Specifically, by encoding the equivariance regarding specific group symmetries into the neural networks, our actor-critic reinforcement learning agents can reuse solutions in the past for related scenarios. Consequently, our equivariant agents outperform non-equivariant approaches significantly in terms of sample efficiency and final performance, demonstrated through experiments on a range of robotic tasks in simulation and real hardware.
Marginal Fairness Sliced Wasserstein Barycenter
May 13, 2024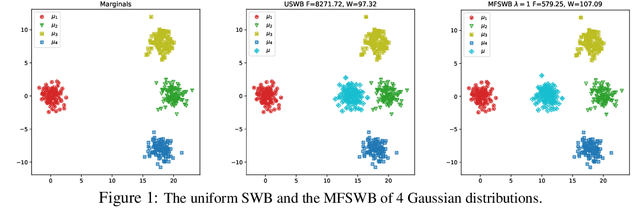
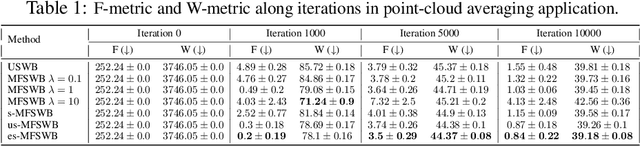
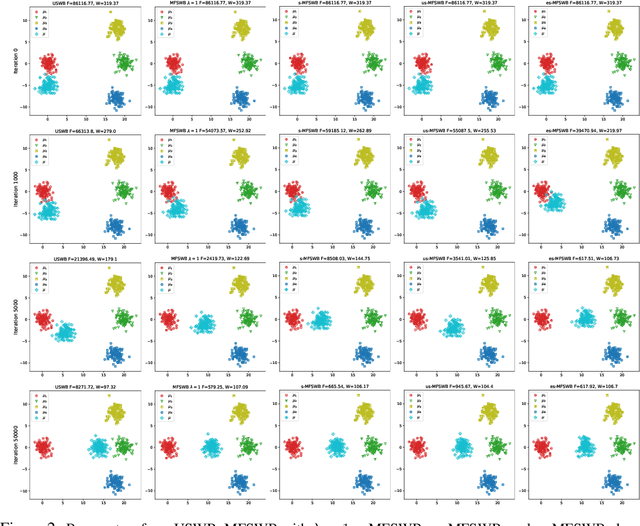
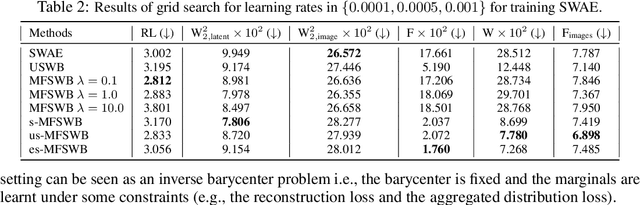
The sliced Wasserstein barycenter (SWB) is a widely acknowledged method for efficiently generalizing the averaging operation within probability measure spaces. However, achieving marginal fairness SWB, ensuring approximately equal distances from the barycenter to marginals, remains unexplored. The uniform weighted SWB is not necessarily the optimal choice to obtain the desired marginal fairness barycenter due to the heterogeneous structure of marginals and the non-optimality of the optimization. As the first attempt to tackle the problem, we define the marginal fairness sliced Wasserstein barycenter (MFSWB) as a constrained SWB problem. Due to the computational disadvantages of the formal definition, we propose two hyperparameter-free and computationally tractable surrogate MFSWB problems that implicitly minimize the distances to marginals and encourage marginal fairness at the same time. To further improve the efficiency, we perform slicing distribution selection and obtain the third surrogate definition by introducing a new slicing distribution that focuses more on marginally unfair projecting directions. We discuss the relationship of the three proposed problems and their relationship to sliced multi-marginal Wasserstein distance. Finally, we conduct experiments on finding 3D point-clouds averaging, color harmonization, and training of sliced Wasserstein autoencoder with class-fairness representation to show the favorable performance of the proposed surrogate MFSWB problems.
Symmetry-aware Reinforcement Learning for Robotic Assembly under Partial Observability with a Soft Wrist
Feb 28, 2024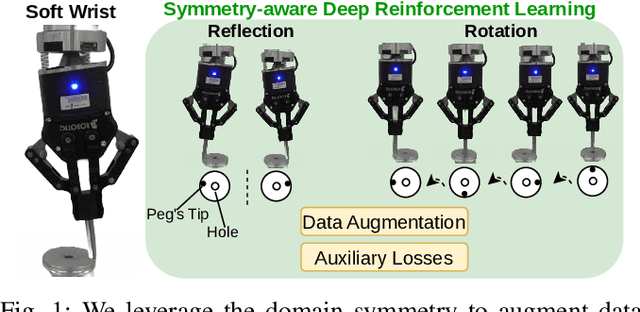
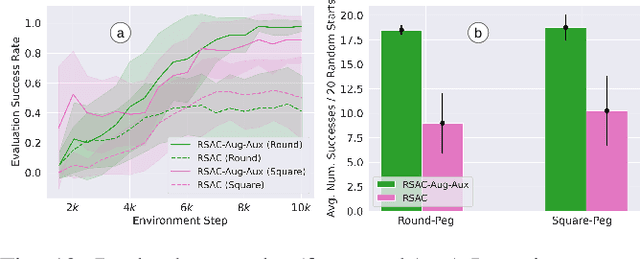
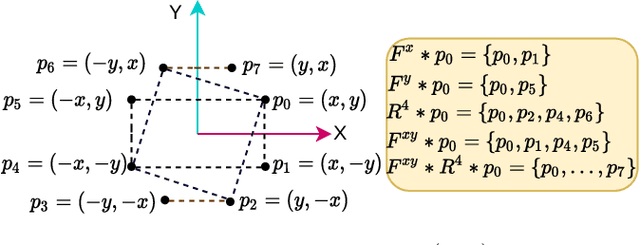
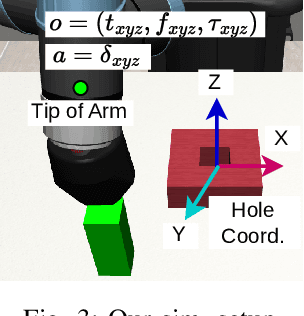
This study tackles the representative yet challenging contact-rich peg-in-hole task of robotic assembly, using a soft wrist that can operate more safely and tolerate lower-frequency control signals than a rigid one. Previous studies often use a fully observable formulation, requiring external setups or estimators for the peg-to-hole pose. In contrast, we use a partially observable formulation and deep reinforcement learning from demonstrations to learn a memory-based agent that acts purely on haptic and proprioceptive signals. Moreover, previous works do not incorporate potential domain symmetry and thus must search for solutions in a bigger space. Instead, we propose to leverage the symmetry for sample efficiency by augmenting the training data and constructing auxiliary losses to force the agent to adhere to the symmetry. Results in simulation with five different symmetric peg shapes show that our proposed agent can be comparable to or even outperform a state-based agent. In particular, the sample efficiency also allows us to learn directly on the real robot within 3 hours.
On-Robot Bayesian Reinforcement Learning for POMDPs
Jul 22, 2023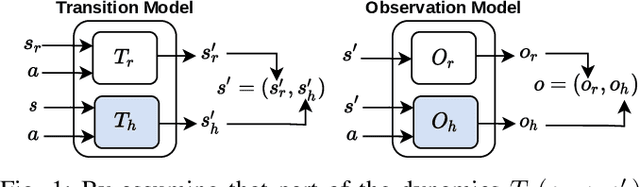
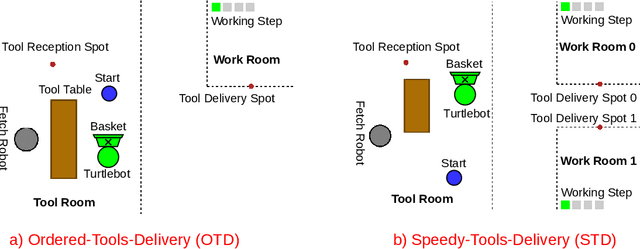

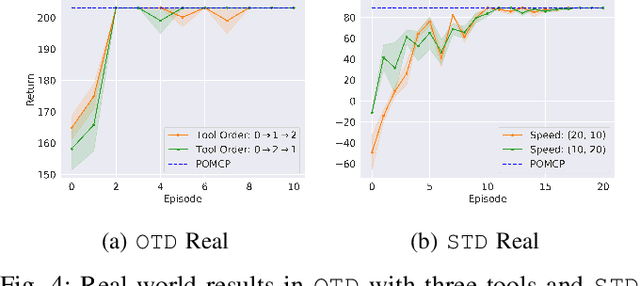
Robot learning is often difficult due to the expense of gathering data. The need for large amounts of data can, and should, be tackled with effective algorithms and leveraging expert information on robot dynamics. Bayesian reinforcement learning (BRL), thanks to its sample efficiency and ability to exploit prior knowledge, is uniquely positioned as such a solution method. Unfortunately, the application of BRL has been limited due to the difficulties of representing expert knowledge as well as solving the subsequent inference problem. This paper advances BRL for robotics by proposing a specialized framework for physical systems. In particular, we capture this knowledge in a factored representation, then demonstrate the posterior factorizes in a similar shape, and ultimately formalize the model in a Bayesian framework. We then introduce a sample-based online solution method, based on Monte-Carlo tree search and particle filtering, specialized to solve the resulting model. This approach can, for example, utilize typical low-level robot simulators and handle uncertainty over unknown dynamics of the environment. We empirically demonstrate its efficiency by performing on-robot learning in two human-robot interaction tasks with uncertainty about human behavior, achieving near-optimal performance after only a handful of real-world episodes. A video of learned policies is at https://youtu.be/H9xp60ngOes.
Learning from Pixels with Expert Observations
Jul 15, 2023



In reinforcement learning (RL), sparse rewards can present a significant challenge. Fortunately, expert actions can be utilized to overcome this issue. However, acquiring explicit expert actions can be costly, and expert observations are often more readily available. This paper presents a new approach that uses expert observations for learning in robot manipulation tasks with sparse rewards from pixel observations. Specifically, our technique involves using expert observations as intermediate visual goals for a goal-conditioned RL agent, enabling it to complete a task by successively reaching a series of goals. We demonstrate the efficacy of our method in five challenging block construction tasks in simulation and show that when combined with two state-of-the-art agents, our approach can significantly improve their performance while requiring 4-20 times fewer expert actions during training. Moreover, our method is also superior to a hierarchical baseline.
Leveraging Fully Observable Policies for Learning under Partial Observability
Nov 10, 2022



Reinforcement learning in partially observable domains is challenging due to the lack of observable state information. Thankfully, learning offline in a simulator with such state information is often possible. In particular, we propose a method for partially observable reinforcement learning that uses a fully observable policy (which we call a state expert) during offline training to improve online performance. Based on Soft Actor-Critic (SAC), our agent balances performing actions similar to the state expert and getting high returns under partial observability. Our approach can leverage the fully-observable policy for exploration and parts of the domain that are fully observable while still being able to learn under partial observability. On six robotics domains, our method outperforms pure imitation, pure reinforcement learning, the sequential or parallel combination of both types, and a recent state-of-the-art method in the same setting. A successful policy transfer to a physical robot in a manipulation task from pixels shows our approach's practicality in learning interesting policies under partial observability.