 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgevieCap4H-VLSP 2021: Vietnamese Image Captioning for Healthcare Domain using Swin Transformer and Attention-based LSTM
Sep 03, 2022
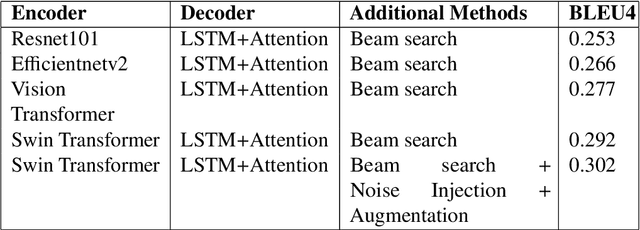
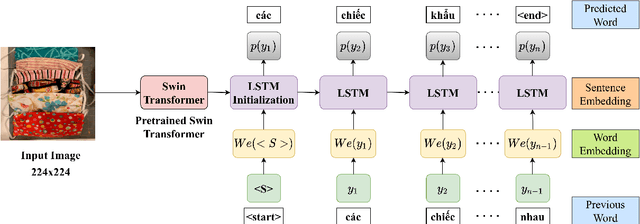

This study presents our approach on the automatic Vietnamese image captioning for healthcare domain in text processing tasks of Vietnamese Language and Speech Processing (VLSP) Challenge 2021, as shown in Figure 1. In recent years, image captioning often employs a convolutional neural network-based architecture as an encoder and a long short-term memory (LSTM) as a decoder to generate sentences. These models perform remarkably well in different datasets. Our proposed model also has an encoder and a decoder, but we instead use a Swin Transformer in the encoder, and a LSTM combined with an attention module in the decoder. The study presents our training experiments and techniques used during the competition. Our model achieves a BLEU4 score of 0.293 on the vietCap4H dataset, and the score is ranked the 3$^{rd}$ place on the private leaderboard. Our code can be found at \url{https://git.io/JDdJm}.
Fruit-CoV: An Efficient Vision-based Framework for Speedy Detection and Diagnosis of SARS-CoV-2 Infections Through Recorded Cough Sounds
Sep 06, 2021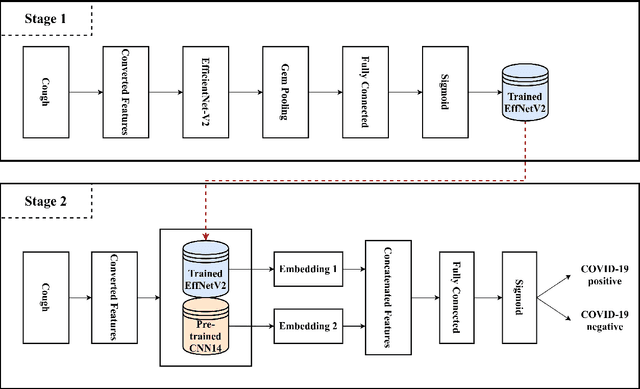
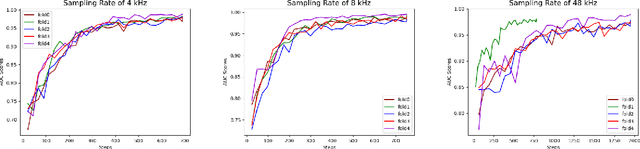
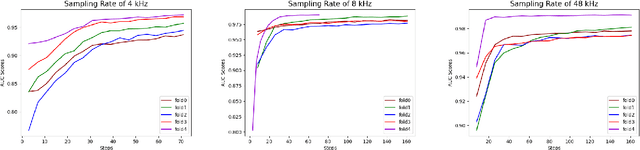
SARS-CoV-2 is colloquially known as COVID-19 that had an initial outbreak in December 2019. The deadly virus has spread across the world, taking part in the global pandemic disease since March 2020. In addition, a recent variant of SARS-CoV-2 named Delta is intractably contagious and responsible for more than four million deaths over the world. Therefore, it is vital to possess a self-testing service of SARS-CoV-2 at home. In this study, we introduce Fruit-CoV, a two-stage vision framework, which is capable of detecting SARS-CoV-2 infections through recorded cough sounds. Specifically, we convert sounds into Log-Mel Spectrograms and use the EfficientNet-V2 network to extract its visual features in the first stage. In the second stage, we use 14 convolutional layers extracted from the large-scale Pretrained Audio Neural Networks for audio pattern recognition (PANNs) and the Wavegram-Log-Mel-CNN to aggregate feature representations of the Log-Mel Spectrograms. Finally, we use the combined features to train a binary classifier. In this study, we use a dataset provided by the AICovidVN 115M Challenge, which includes a total of 7371 recorded cough sounds collected throughout Vietnam, India, and Switzerland. Experimental results show that our proposed model achieves an AUC score of 92.8% and ranks the 1st place on the leaderboard of the AICovidVN Challenge. More importantly, our proposed framework can be integrated into a call center or a VoIP system to speed up detecting SARS-CoV-2 infections through online/recorded cough sounds.
Self-boosted Time-series Forecasting with Multi-task and Multi-view Learning
Sep 17, 2019
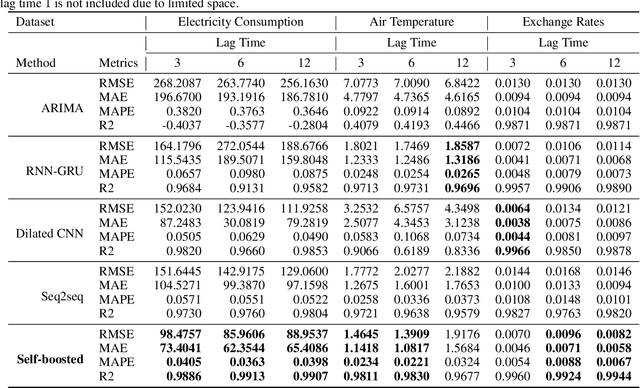

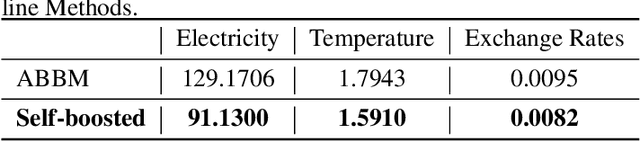
A robust model for time series forecasting is highly important in many domains, including but not limited to financial forecast, air temperature and electricity consumption. To improve forecasting performance, traditional approaches usually require additional feature sets. However, adding more feature sets from different sources of data is not always feasible due to its accessibility limitation. In this paper, we propose a novel self-boosted mechanism in which the original time series is decomposed into multiple time series. These time series played the role of additional features in which the closely related time series group is used to feed into multi-task learning model, and the loosely related group is fed into multi-view learning part to utilize its complementary information. We use three real-world datasets to validate our model and show the superiority of our proposed method over existing state-of-the-art baseline methods.