 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQTSeg: A Query Token-Based Architecture for Efficient 2D Medical Image Segmentation
Dec 23, 2024Medical image segmentation is crucial in assisting medical doctors in making diagnoses and enabling accurate automatic diagnosis. While advanced convolutional neural networks (CNNs) excel in segmenting regions of interest with pixel-level precision, they often struggle with long-range dependencies, which is crucial for enhancing model performance. Conversely, transformer architectures leverage attention mechanisms to excel in handling long-range dependencies. However, the computational complexity of transformers grows quadratically, posing resource-intensive challenges, especially with high-resolution medical images. Recent research aims to combine CNN and transformer architectures to mitigate their drawbacks and enhance performance while keeping resource demands low. Nevertheless, existing approaches have not fully leveraged the strengths of both architectures to achieve high accuracy with low computational requirements. To address this gap, we propose a novel architecture for 2D medical image segmentation (QTSeg) that leverages a feature pyramid network (FPN) as the image encoder, a multi-level feature fusion (MLFF) as the adaptive module between encoder and decoder and a multi-query mask decoder (MQM Decoder) as the mask decoder. In the first step, an FPN model extracts pyramid features from the input image. Next, MLFF is incorporated between the encoder and decoder to adapt features from different encoder stages to the decoder. Finally, an MQM Decoder is employed to improve mask generation by integrating query tokens with pyramid features at all stages of the mask decoder. Our experimental results show that QTSeg outperforms state-of-the-art methods across all metrics with lower computational demands than the baseline and the existing methods. Code is available at https://github.com/tpnam0901/QTSeg (v0.1.0)
vieCap4H-VLSP 2021: Vietnamese Image Captioning for Healthcare Domain using Swin Transformer and Attention-based LSTM
Sep 03, 2022
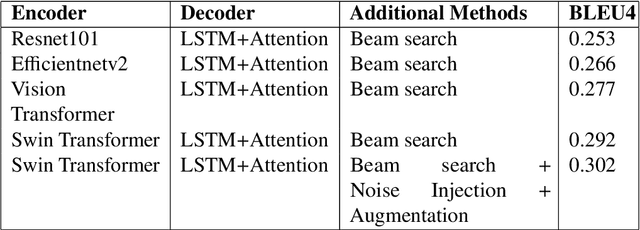
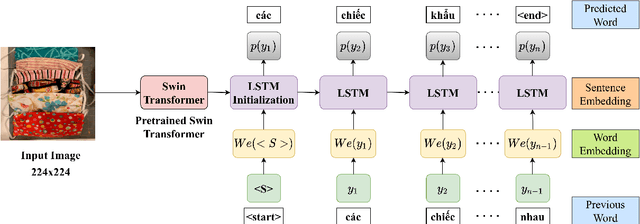

This study presents our approach on the automatic Vietnamese image captioning for healthcare domain in text processing tasks of Vietnamese Language and Speech Processing (VLSP) Challenge 2021, as shown in Figure 1. In recent years, image captioning often employs a convolutional neural network-based architecture as an encoder and a long short-term memory (LSTM) as a decoder to generate sentences. These models perform remarkably well in different datasets. Our proposed model also has an encoder and a decoder, but we instead use a Swin Transformer in the encoder, and a LSTM combined with an attention module in the decoder. The study presents our training experiments and techniques used during the competition. Our model achieves a BLEU4 score of 0.293 on the vietCap4H dataset, and the score is ranked the 3$^{rd}$ place on the private leaderboard. Our code can be found at \url{https://git.io/JDdJm}.
Hybrid Data Augmentation and Deep Attention-based Dilated Convolutional-Recurrent Neural Networks for Speech Emotion Recognition
Sep 18, 2021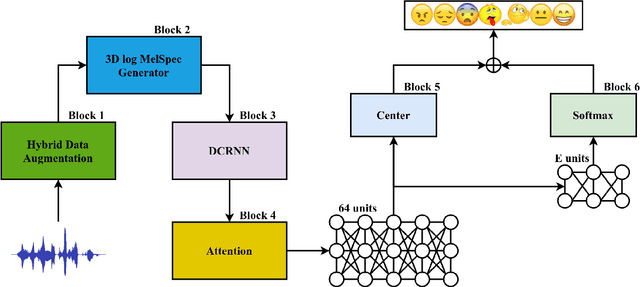
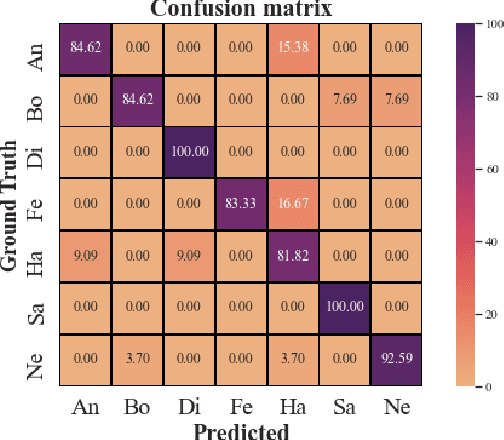
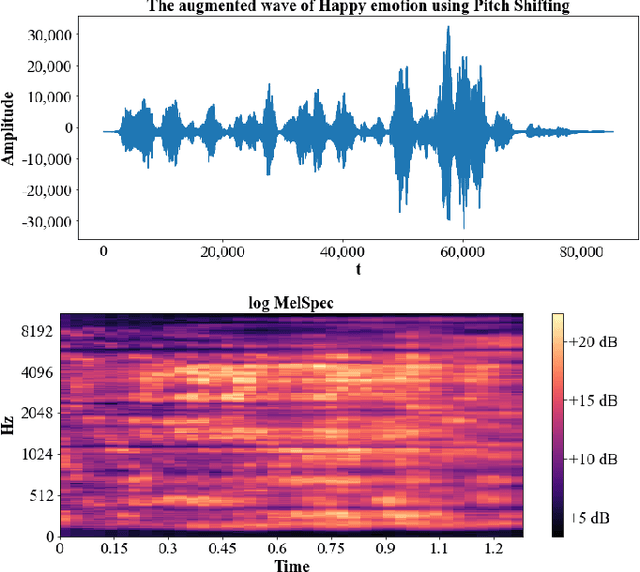
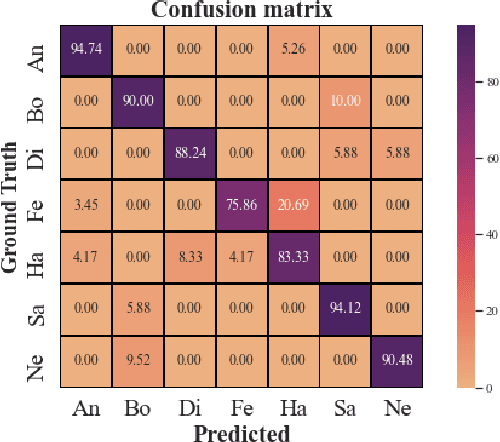
Speech emotion recognition (SER) has been one of the significant tasks in Human-Computer Interaction (HCI) applications. However, it is hard to choose the optimal features and deal with imbalance labeled data. In this article, we investigate hybrid data augmentation (HDA) methods to generate and balance data based on traditional and generative adversarial networks (GAN) methods. To evaluate the effectiveness of HDA methods, a deep learning framework namely (ADCRNN) is designed by integrating deep dilated convolutional-recurrent neural networks with an attention mechanism. Besides, we choose 3D log Mel-spectrogram (MelSpec) features as the inputs for the deep learning framework. Furthermore, we reconfigure a loss function by combining a softmax loss and a center loss to classify the emotions. For validating our proposed methods, we use the EmoDB dataset that consists of several emotions with imbalanced samples. Experimental results prove that the proposed methods achieve better accuracy than the state-of-the-art methods on the EmoDB with 87.12% and 88.47% for the traditional and GAN-based methods, respectively.
Fruit-CoV: An Efficient Vision-based Framework for Speedy Detection and Diagnosis of SARS-CoV-2 Infections Through Recorded Cough Sounds
Sep 06, 2021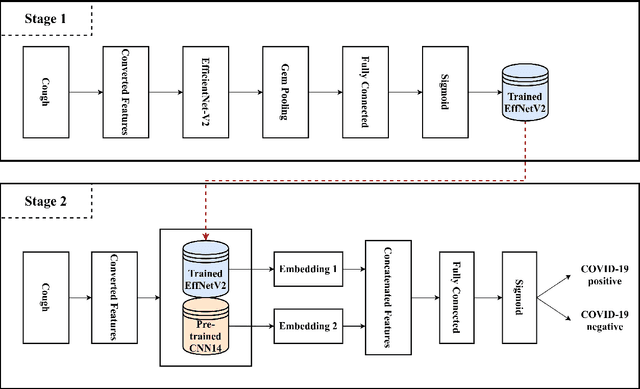
SARS-CoV-2 is colloquially known as COVID-19 that had an initial outbreak in December 2019. The deadly virus has spread across the world, taking part in the global pandemic disease since March 2020. In addition, a recent variant of SARS-CoV-2 named Delta is intractably contagious and responsible for more than four million deaths over the world. Therefore, it is vital to possess a self-testing service of SARS-CoV-2 at home. In this study, we introduce Fruit-CoV, a two-stage vision framework, which is capable of detecting SARS-CoV-2 infections through recorded cough sounds. Specifically, we convert sounds into Log-Mel Spectrograms and use the EfficientNet-V2 network to extract its visual features in the first stage. In the second stage, we use 14 convolutional layers extracted from the large-scale Pretrained Audio Neural Networks for audio pattern recognition (PANNs) and the Wavegram-Log-Mel-CNN to aggregate feature representations of the Log-Mel Spectrograms. Finally, we use the combined features to train a binary classifier. In this study, we use a dataset provided by the AICovidVN 115M Challenge, which includes a total of 7371 recorded cough sounds collected throughout Vietnam, India, and Switzerland. Experimental results show that our proposed model achieves an AUC score of 92.8% and ranks the 1st place on the leaderboard of the AICovidVN Challenge. More importantly, our proposed framework can be integrated into a call center or a VoIP system to speed up detecting SARS-CoV-2 infections through online/recorded cough sounds.
Detecting Drill Failure in the Small Short-sound Drill Dataset
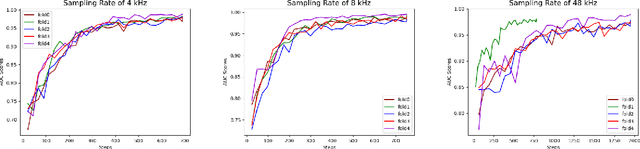
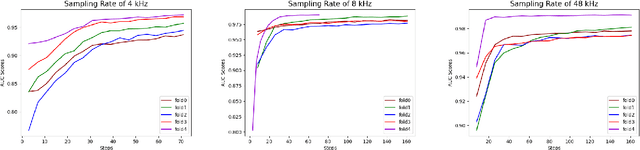
Aug 25, 2021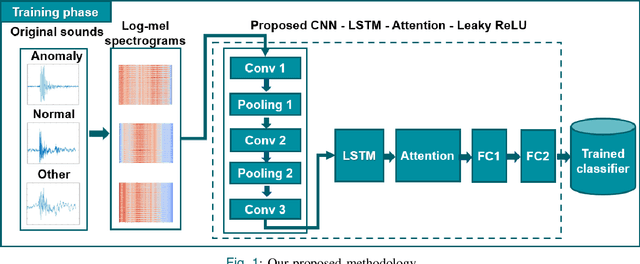
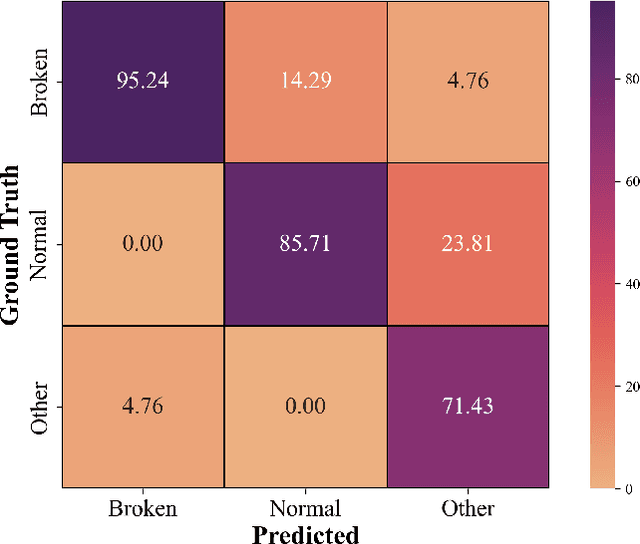

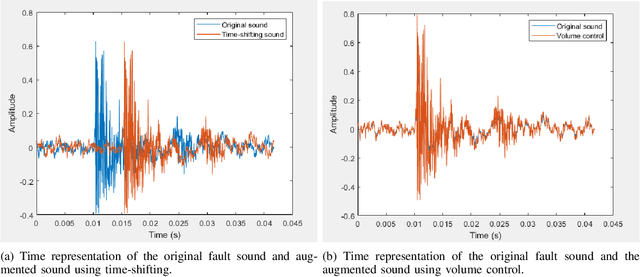
Monitoring the conditions of machines is vital in the manufacturing industry. Early detection of faulty components in machines for stopping and repairing the failed components can minimize the downtime of the machine. This article presents an approach to detect the failure occurring in drill machines based on drill sounds from Valmet AB. The drill dataset includes three classes: anomalous sounds, normal sounds, and irrelevant sounds, which are also labeled as ``Broken", ``Normal", and ``Other", respectively. Detecting drill failure effectively remains a challenge due to the following reasons. The waveform of drill sound is complex and short for detection. Additionally, in realistic soundscapes, there are sounds and noise in the context at the same time. Moreover, the balanced dataset is small to apply state-of-the-art deep learning techniques. To overcome these aforementioned difficulties, we augmented sounds to increase the number of sounds in the dataset. We then proposed a convolutional neural network (CNN) combined with a long short-term memory (LSTM) to extract features from log-Mel spectrograms and learn global high-level feature representation for the classification of three classes. A leaky rectified linear unit (Leaky ReLU) was utilized as the activation function for our proposed CNN instead of the rectified linear unit (ReLU). Moreover, we deployed an attention mechanism at the frame level after the LSTM layer to learn long-term global feature representations. As a result, the proposed method reached an overall accuracy of 92.35% for the drill failure detection system.