 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrategic Decision-Making Under Uncertainty through Bi-Level Game Theory and Distributionally Robust Optimization
Nov 07, 2025In strategic scenarios where decision-makers operate at different hierarchical levels, traditional optimization methods are often inadequate for handling uncertainties from incomplete information or unpredictable external factors. To fill this gap, we introduce a mathematical framework that integrates bi-level game theory with distributionally robust optimization (DRO), particularly suited for complex network systems. Our approach leverages the hierarchical structure of bi-level games to model leader-follower interactions while incorporating distributional robustness to guard against worst-case probability distributions. To ensure computational tractability, the Karush-Kuhn-Tucker (KKT) conditions are used to transform the bi-level challenge into a more manageable single-level model, and the infinite-dimensional DRO problem is reformulated into a finite equivalent. We propose a generalized algorithm to solve this integrated model. Simulation results validate our framework's efficacy, demonstrating that under high uncertainty, the proposed model achieves up to a 22\% cost reduction compared to traditional stochastic methods while maintaining a service level of over 90\%. This highlights its potential to significantly improve decision quality and robustness in networked systems such as transportation and communication networks.
Large Language Models-Empowered Wireless Networks: Fundamentals, Architecture, and Challenges
Jun 12, 2025The rapid advancement of wireless networks has resulted in numerous challenges stemming from their extensive demands for quality of service towards innovative quality of experience metrics (e.g., user-defined metrics in terms of sense of physical experience for haptics applications). In the meantime, large language models (LLMs) emerged as promising solutions for many difficult and complex applications/tasks. These lead to a notion of the integration of LLMs and wireless networks. However, this integration is challenging and needs careful attention in design. Therefore, in this article, we present a notion of rational wireless networks powered by \emph{telecom LLMs}, namely, \emph{LLM-native wireless systems}. We provide fundamentals, vision, and a case study of the distributed implementation of LLM-native wireless systems. In the case study, we propose a solution based on double deep Q-learning (DDQN) that outperforms existing DDQN solutions. Finally, we provide open challenges.
Robust Federated Learning on Edge Devices with Domain Heterogeneity
May 15, 2025



Federated Learning (FL) allows collaborative training while ensuring data privacy across distributed edge devices, making it a popular solution for privacy-sensitive applications. However, FL faces significant challenges due to statistical heterogeneity, particularly domain heterogeneity, which impedes the global mode's convergence. In this study, we introduce a new framework to address this challenge by improving the generalization ability of the FL global model under domain heterogeneity, using prototype augmentation. Specifically, we introduce FedAPC (Federated Augmented Prototype Contrastive Learning), a prototype-based FL framework designed to enhance feature diversity and model robustness. FedAPC leverages prototypes derived from the mean features of augmented data to capture richer representations. By aligning local features with global prototypes, we enable the model to learn meaningful semantic features while reducing overfitting to any specific domain. Experimental results on the Office-10 and Digits datasets illustrate that our framework outperforms SOTA baselines, demonstrating superior performance.
Towards Artificial General or Personalized Intelligence? A Survey on Foundation Models for Personalized Federated Intelligence
May 11, 2025



The rise of large language models (LLMs), such as ChatGPT, DeepSeek, and Grok-3, has reshaped the artificial intelligence landscape. As prominent examples of foundational models (FMs) built on LLMs, these models exhibit remarkable capabilities in generating human-like content, bringing us closer to achieving artificial general intelligence (AGI). However, their large-scale nature, sensitivity to privacy concerns, and substantial computational demands present significant challenges to personalized customization for end users. To bridge this gap, this paper presents the vision of artificial personalized intelligence (API), focusing on adapting these powerful models to meet the specific needs and preferences of users while maintaining privacy and efficiency. Specifically, this paper proposes personalized federated intelligence (PFI), which integrates the privacy-preserving advantages of federated learning (FL) with the zero-shot generalization capabilities of FMs, enabling personalized, efficient, and privacy-protective deployment at the edge. We first review recent advances in both FL and FMs, and discuss the potential of leveraging FMs to enhance federated systems. We then present the key motivations behind realizing PFI and explore promising opportunities in this space, including efficient PFI, trustworthy PFI, and PFI empowered by retrieval-augmented generation (RAG). Finally, we outline key challenges and future research directions for deploying FM-powered FL systems at the edge with improved personalization, computational efficiency, and privacy guarantees. Overall, this survey aims to lay the groundwork for the development of API as a complement to AGI, with a particular focus on PFI as a key enabling technique.
FedFeat+: A Robust Federated Learning Framework Through Federated Aggregation and Differentially Private Feature-Based Classifier Retraining
Apr 08, 2025In this paper, we propose the FedFeat+ framework, which distinctively separates feature extraction from classification. We develop a two-tiered model training process: following local training, clients transmit their weights and some features extracted from the feature extractor from the final local epochs to the server. The server aggregates these models using the FedAvg method and subsequently retrains the global classifier utilizing the shared features. The classifier retraining process enhances the model's understanding of the holistic view of the data distribution, ensuring better generalization across diverse datasets. This improved generalization enables the classifier to adaptively influence the feature extractor during subsequent local training epochs. We establish a balance between enhancing model accuracy and safeguarding individual privacy through the implementation of differential privacy mechanisms. By incorporating noise into the feature vectors shared with the server, we ensure that sensitive data remains confidential. We present a comprehensive convergence analysis, along with theoretical reasoning regarding performance enhancement and privacy preservation. We validate our approach through empirical evaluations conducted on benchmark datasets, including CIFAR-10, CIFAR-100, MNIST, and FMNIST, achieving high accuracy while adhering to stringent privacy guarantees. The experimental results demonstrate that the FedFeat+ framework, despite using only a lightweight two-layer CNN classifier, outperforms the FedAvg method in both IID and non-IID scenarios, achieving accuracy improvements ranging from 3.92 % to 12.34 % across CIFAR-10, CIFAR-100, and Fashion-MNIST datasets.
Resource-Efficient Beam Prediction in mmWave Communications with Multimodal Realistic Simulation Framework
Apr 07, 2025Beamforming is a key technology in millimeter-wave (mmWave) communications that improves signal transmission by optimizing directionality and intensity. However, conventional channel estimation methods, such as pilot signals or beam sweeping, often fail to adapt to rapidly changing communication environments. To address this limitation, multimodal sensing-aided beam prediction has gained significant attention, using various sensing data from devices such as LiDAR, radar, GPS, and RGB images to predict user locations or network conditions. Despite its promising potential, the adoption of multimodal sensing-aided beam prediction is hindered by high computational complexity, high costs, and limited datasets. Thus, in this paper, a resource-efficient learning approach is proposed to transfer knowledge from a multimodal network to a monomodal (radar-only) network based on cross-modal relational knowledge distillation (CRKD), while reducing computational overhead and preserving predictive accuracy. To enable multimodal learning with realistic data, a novel multimodal simulation framework is developed while integrating sensor data generated from the autonomous driving simulator CARLA with MATLAB-based mmWave channel modeling, and reflecting real-world conditions. The proposed CRKD achieves its objective by distilling relational information across different feature spaces, which enhances beam prediction performance without relying on expensive sensor data. Simulation results demonstrate that CRKD efficiently distills multimodal knowledge, allowing a radar-only model to achieve $94.62\%$ of the teacher performance. In particular, this is achieved with just $10\%$ of the teacher network's parameters, thereby significantly reducing computational complexity and dependence on multimodal sensor data.
Federated Koopman-Reservoir Learning for Large-Scale Multivariate Time-Series Anomaly Detection
Mar 14, 2025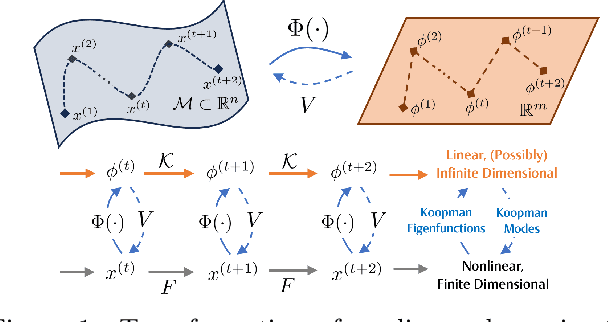
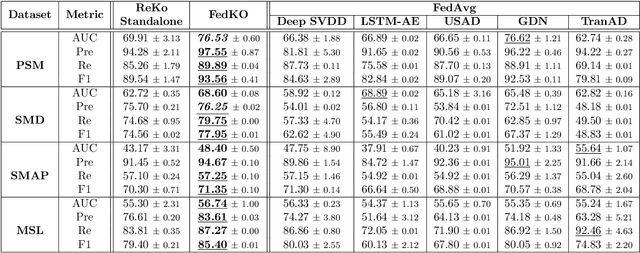
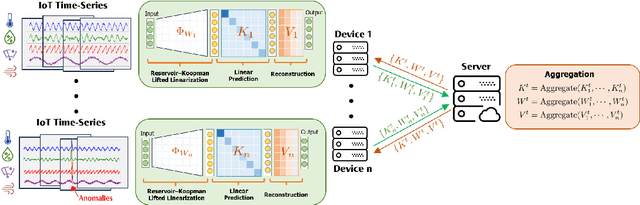
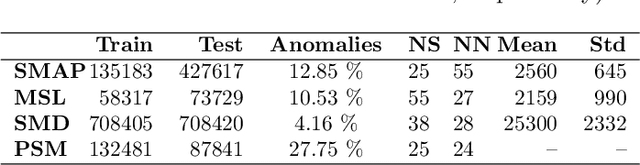
The proliferation of edge devices has dramatically increased the generation of multivariate time-series (MVTS) data, essential for applications from healthcare to smart cities. Such data streams, however, are vulnerable to anomalies that signal crucial problems like system failures or security incidents. Traditional MVTS anomaly detection methods, encompassing statistical and centralized machine learning approaches, struggle with the heterogeneity, variability, and privacy concerns of large-scale, distributed environments. In response, we introduce FedKO, a novel unsupervised Federated Learning framework that leverages the linear predictive capabilities of Koopman operator theory along with the dynamic adaptability of Reservoir Computing. This enables effective spatiotemporal processing and privacy preservation for MVTS data. FedKO is formulated as a bi-level optimization problem, utilizing a specific federated algorithm to explore a shared Reservoir-Koopman model across diverse datasets. Such a model is then deployable on edge devices for efficient detection of anomalies in local MVTS streams. Experimental results across various datasets showcase FedKO's superior performance against state-of-the-art methods in MVTS anomaly detection. Moreover, FedKO reduces up to 8x communication size and 2x memory usage, making it highly suitable for large-scale systems.
Exploring Mutual Empowerment Between Wireless Networks and RL-based LLMs: A Survey
Mar 13, 2025



Reinforcement learning (RL)-based large language models (LLMs), such as ChatGPT, DeepSeek, and Grok-3, have gained significant attention for their exceptional capabilities in natural language processing and multimodal data understanding. Meanwhile, the rapid expansion of information services has driven the growing need for intelligence, efficient, and adaptable wireless networks. Wireless networks require the empowerment of RL-based LLMs while these models also benefit from wireless networks to broaden their application scenarios. Specifically, RL-based LLMs can enhance wireless communication systems through intelligent resource allocation, adaptive network optimization, and real-time decision-making. Conversely, wireless networks provide a vital infrastructure for the efficient training, deployment, and distributed inference of RL-based LLMs, especially in decentralized and edge computing environments. This mutual empowerment highlights the need for a deeper exploration of the interplay between these two domains. We first review recent advancements in wireless communications, highlighting the associated challenges and potential solutions. We then discuss the progress of RL-based LLMs, focusing on key technologies for LLM training, challenges, and potential solutions. Subsequently, we explore the mutual empowerment between these two fields, highlighting key motivations, open challenges, and potential solutions. Finally, we provide insights into future directions, applications, and their societal impact to further explore this intersection, paving the way for next-generation intelligent communication systems. Overall, this survey provides a comprehensive overview of the relationship between RL-based LLMs and wireless networks, offering a vision where these domains empower each other to drive innovations.
Pre-trained Model Guided Mixture Knowledge Distillation for Adversarial Federated Learning
Jan 25, 2025



This paper aims to improve the robustness of a small global model while maintaining clean accuracy under adversarial attacks and non-IID challenges in federated learning. By leveraging the concise knowledge embedded in the class probabilities from a pre-trained model for both clean and adversarial image classification, we propose a Pre-trained Model-guided Adversarial Federated Learning (PM-AFL) training paradigm. This paradigm integrates vanilla mixture and adversarial mixture knowledge distillation to effectively balance accuracy and robustness while promoting local models to learn from diverse data. Specifically, for clean accuracy, we adopt a dual distillation strategy where the class probabilities of randomly paired images and their blended versions are aligned between the teacher model and the local models. For adversarial robustness, we use a similar distillation approach but replace clean samples on the local side with adversarial examples. Moreover, considering the bias between local and global models, we also incorporate a consistency regularization term to ensure that local adversarial predictions stay aligned with their corresponding global clean ones. These strategies collectively enable local models to absorb diverse knowledge from the teacher model while maintaining close alignment with the global model, thereby mitigating overfitting to local optima and enhancing the generalization of the global model. Experiments demonstrate that the PM-AFL-based paradigm outperforms other methods that integrate defense strategies by a notable margin.
Mitigating Domain Shift in Federated Learning via Intra- and Inter-Domain Prototypes
Jan 15, 2025



Federated Learning (FL) has emerged as a decentralized machine learning technique, allowing clients to train a global model collaboratively without sharing private data. However, most FL studies ignore the crucial challenge of heterogeneous domains where each client has a distinct feature distribution, which is common in real-world scenarios. Prototype learning, which leverages the mean feature vectors within the same classes, has become a prominent solution for federated learning under domain skew. However, existing federated prototype learning methods only consider inter-domain prototypes on the server and overlook intra-domain characteristics. In this work, we introduce a novel federated prototype learning method, namely I$^2$PFL, which incorporates $\textbf{I}$ntra-domain and $\textbf{I}$nter-domain $\textbf{P}$rototypes, to mitigate domain shifts and learn a generalized global model across multiple domains in federated learning. To construct intra-domain prototypes, we propose feature alignment with MixUp-based augmented prototypes to capture the diversity of local domains and enhance the generalization of local features. Additionally, we introduce a reweighting mechanism for inter-domain prototypes to generate generalized prototypes to provide inter-domain knowledge and reduce domain skew across multiple clients. Extensive experiments on the Digits, Office-10, and PACS datasets illustrate the superior performance of our method compared to other baselines.