 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Domain Shift in Federated Learning via Intra- and Inter-Domain Prototypes
Jan 15, 2025



Federated Learning (FL) has emerged as a decentralized machine learning technique, allowing clients to train a global model collaboratively without sharing private data. However, most FL studies ignore the crucial challenge of heterogeneous domains where each client has a distinct feature distribution, which is common in real-world scenarios. Prototype learning, which leverages the mean feature vectors within the same classes, has become a prominent solution for federated learning under domain skew. However, existing federated prototype learning methods only consider inter-domain prototypes on the server and overlook intra-domain characteristics. In this work, we introduce a novel federated prototype learning method, namely I$^2$PFL, which incorporates $\textbf{I}$ntra-domain and $\textbf{I}$nter-domain $\textbf{P}$rototypes, to mitigate domain shifts and learn a generalized global model across multiple domains in federated learning. To construct intra-domain prototypes, we propose feature alignment with MixUp-based augmented prototypes to capture the diversity of local domains and enhance the generalization of local features. Additionally, we introduce a reweighting mechanism for inter-domain prototypes to generate generalized prototypes to provide inter-domain knowledge and reduce domain skew across multiple clients. Extensive experiments on the Digits, Office-10, and PACS datasets illustrate the superior performance of our method compared to other baselines.
CLIP-PING: Boosting Lightweight Vision-Language Models with Proximus Intrinsic Neighbors Guidance
Dec 05, 2024



Beyond the success of Contrastive Language-Image Pre-training (CLIP), recent trends mark a shift toward exploring the applicability of lightweight vision-language models for resource-constrained scenarios. These models often deliver suboptimal performance when relying solely on a single image-text contrastive learning objective, spotlighting the need for more effective training mechanisms that guarantee robust cross-modal feature alignment. In this work, we propose CLIP-PING: Contrastive Language-Image Pre-training with Proximus Intrinsic Neighbors Guidance, a simple and efficient training paradigm designed to boost the performance of lightweight vision-language models with minimal computational overhead and lower data demands. CLIP-PING bootstraps unimodal features extracted from arbitrary pre-trained encoders to obtain intrinsic guidance of proximus neighbor samples, i.e., nearest-neighbor (NN) and cross nearest-neighbor (XNN). We find that extra contrastive supervision from these neighbors substantially boosts cross-modal alignment, enabling lightweight models to learn more generic features with rich semantic diversity. Extensive experiments reveal that CLIP-PING notably surpasses its peers in zero-shot generalization and cross-modal retrieval tasks. Specifically, a 5.5% gain on zero-shot ImageNet1K with 10.7% (I2T) and 5.7% (T2I) on Flickr30K, compared to the original CLIP when using ViT-XS image encoder trained on 3 million (image, text) pairs. Moreover, CLIP-PING showcases strong transferability under the linear evaluation protocol across several downstream tasks.
Resource-Efficient Federated Multimodal Learning via Layer-wise and Progressive Training
Jul 22, 2024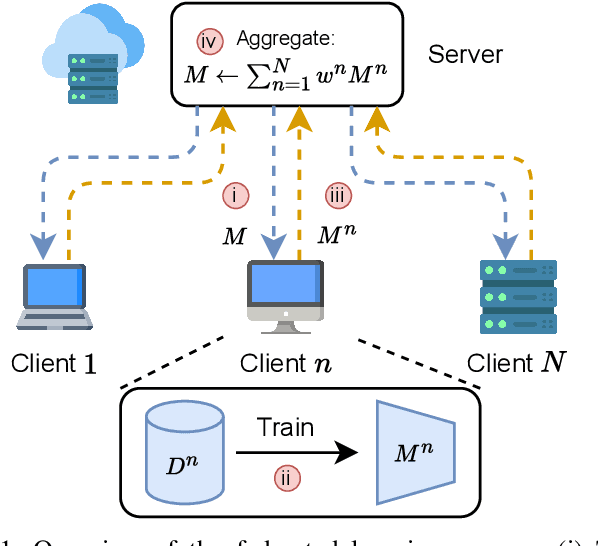
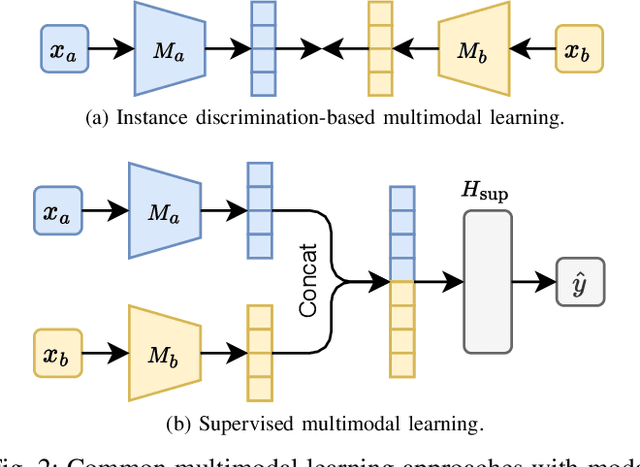
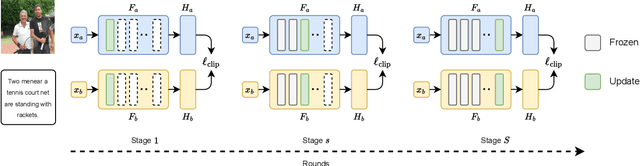
Combining different data modalities enables deep neural networks to tackle complex tasks more effectively, making multimodal learning increasingly popular. To harness multimodal data closer to end users, it is essential to integrate multimodal learning with privacy-preserving training approaches such as federated learning (FL). However, compared to conventional unimodal learning, multimodal setting requires dedicated encoders for each modality, resulting in larger and more complex models that demand significant resources. This presents a substantial challenge for FL clients operating with limited computational resources and communication bandwidth. To address these challenges, we introduce LW-FedMML, a layer-wise federated multimodal learning approach, which decomposes the training process into multiple steps. Each step focuses on training only a portion of the model, thereby significantly reducing the memory and computational requirements. Moreover, FL clients only need to exchange the trained model portion with the central server, lowering the resulting communication cost. We conduct extensive experiments across various FL scenarios and multimodal learning setups to validate the effectiveness of our proposed method. The results demonstrate that LW-FedMML can compete with conventional end-to-end federated multimodal learning (FedMML) while significantly reducing the resource burden on FL clients. Specifically, LW-FedMML reduces memory usage by up to $2.7\times$, computational operations (FLOPs) by $2.4\times$, and total communication cost by $2.3\times$. We also introduce a progressive training approach called Prog-FedMML. While it offers lesser resource efficiency than LW-FedMML, Prog-FedMML has the potential to surpass the performance of end-to-end FedMML, making it a viable option for scenarios with fewer resource constraints.
Cross-Modal Prototype based Multimodal Federated Learning under Severely Missing Modality
Jan 25, 2024Multimodal federated learning (MFL) has emerged as a decentralized machine learning paradigm, allowing multiple clients with different modalities to collaborate on training a machine learning model across diverse data sources without sharing their private data. However, challenges, such as data heterogeneity and severely missing modalities, pose crucial hindrances to the robustness of MFL, significantly impacting the performance of global model. The absence of a modality introduces misalignment during the local training phase, stemming from zero-filling in the case of clients with missing modalities. Consequently, achieving robust generalization in global model becomes imperative, especially when dealing with clients that have incomplete data. In this paper, we propose Multimodal Federated Cross Prototype Learning (MFCPL), a novel approach for MFL under severely missing modalities by conducting the complete prototypes to provide diverse modality knowledge in modality-shared level with the cross-modal regularization and modality-specific level with cross-modal contrastive mechanism. Additionally, our approach introduces the cross-modal alignment to provide regularization for modality-specific features, thereby enhancing overall performance, particularly in scenarios involving severely missing modalities. Through extensive experiments on three multimodal datasets, we demonstrate the effectiveness of MFCPL in mitigating these challenges and improving the overall performance.
LW-FedSSL: Resource-efficient Layer-wise Federated Self-supervised Learning
Jan 22, 2024

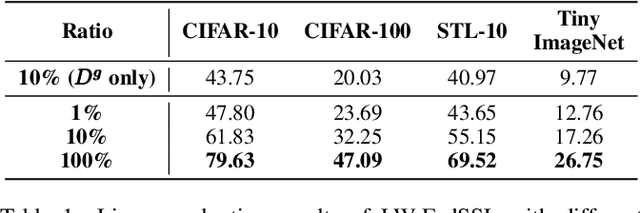

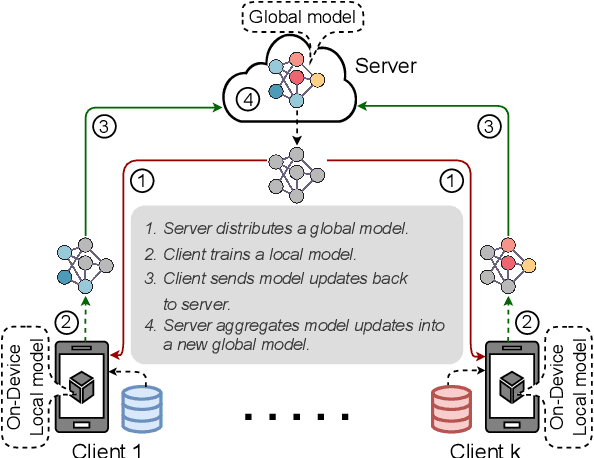
Many recent studies integrate federated learning (FL) with self-supervised learning (SSL) to take advantage of raw training data distributed across edge devices. However, edge devices often struggle with high computation and communication costs imposed by SSL and FL algorithms. To tackle this hindrance, we propose LW-FedSSL, a layer-wise federated self-supervised learning approach that allows edge devices to incrementally train one layer of the model at a time. LW-FedSSL comprises server-side calibration and representation alignment mechanisms to maintain comparable performance with end-to-end FedSSL while significantly lowering clients' resource requirements. The server-side calibration mechanism takes advantage of the resource-rich server in an FL environment to assist in global model training. Meanwhile, the representation alignment mechanism encourages closeness between representations of FL local models and those of the global model. Our experiments show that LW-FedSSL has a $3.3 \times$ lower memory requirement and a $3.2 \times$ cheaper communication cost than its end-to-end counterpart. We also explore a progressive training strategy called Prog-FedSSL that outperforms end-to-end training with a similar memory requirement and a $1.8 \times$ cheaper communication cost.
OnDev-LCT: On-Device Lightweight Convolutional Transformers towards federated learning
Jan 22, 2024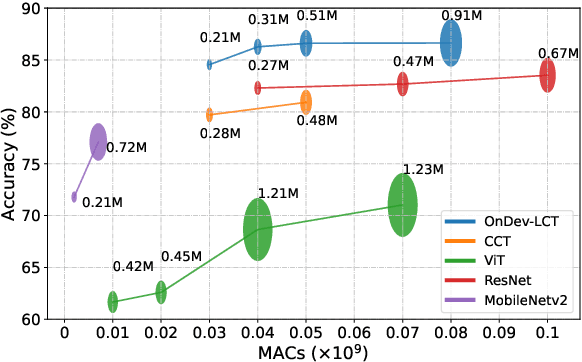
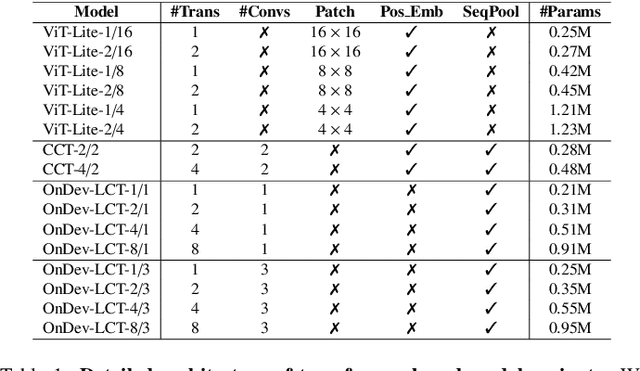
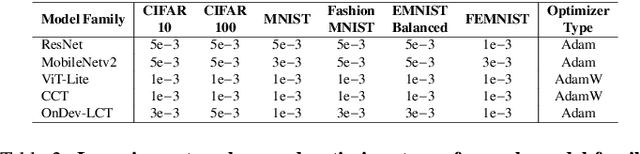
Federated learning (FL) has emerged as a promising approach to collaboratively train machine learning models across multiple edge devices while preserving privacy. The success of FL hinges on the efficiency of participating models and their ability to handle the unique challenges of distributed learning. While several variants of Vision Transformer (ViT) have shown great potential as alternatives to modern convolutional neural networks (CNNs) for centralized training, the unprecedented size and higher computational demands hinder their deployment on resource-constrained edge devices, challenging their widespread application in FL. Since client devices in FL typically have limited computing resources and communication bandwidth, models intended for such devices must strike a balance between model size, computational efficiency, and the ability to adapt to the diverse and non-IID data distributions encountered in FL. To address these challenges, we propose OnDev-LCT: Lightweight Convolutional Transformers for On-Device vision tasks with limited training data and resources. Our models incorporate image-specific inductive biases through the LCT tokenizer by leveraging efficient depthwise separable convolutions in residual linear bottleneck blocks to extract local features, while the multi-head self-attention (MHSA) mechanism in the LCT encoder implicitly facilitates capturing global representations of images. Extensive experiments on benchmark image datasets indicate that our models outperform existing lightweight vision models while having fewer parameters and lower computational demands, making them suitable for FL scenarios with data heterogeneity and communication bottlenecks.
Contrastive encoder pre-training-based clustered federated learning for heterogeneous data
Nov 28, 2023Federated learning (FL) is a promising approach that enables distributed clients to collaboratively train a global model while preserving their data privacy. However, FL often suffers from data heterogeneity problems, which can significantly affect its performance. To address this, clustered federated learning (CFL) has been proposed to construct personalized models for different client clusters. One effective client clustering strategy is to allow clients to choose their own local models from a model pool based on their performance. However, without pre-trained model parameters, such a strategy is prone to clustering failure, in which all clients choose the same model. Unfortunately, collecting a large amount of labeled data for pre-training can be costly and impractical in distributed environments. To overcome this challenge, we leverage self-supervised contrastive learning to exploit unlabeled data for the pre-training of FL systems. Together, self-supervised pre-training and client clustering can be crucial components for tackling the data heterogeneity issues of FL. Leveraging these two crucial strategies, we propose contrastive pre-training-based clustered federated learning (CP-CFL) to improve the model convergence and overall performance of FL systems. In this work, we demonstrate the effectiveness of CP-CFL through extensive experiments in heterogeneous FL settings, and present various interesting observations.
FedMEKT: Distillation-based Embedding Knowledge Transfer for Multimodal Federated Learning
Jul 25, 2023



Federated learning (FL) enables a decentralized machine learning paradigm for multiple clients to collaboratively train a generalized global model without sharing their private data. Most existing works simply propose typical FL systems for single-modal data, thus limiting its potential on exploiting valuable multimodal data for future personalized applications. Furthermore, the majority of FL approaches still rely on the labeled data at the client side, which is limited in real-world applications due to the inability of self-annotation from users. In light of these limitations, we propose a novel multimodal FL framework that employs a semi-supervised learning approach to leverage the representations from different modalities. Bringing this concept into a system, we develop a distillation-based multimodal embedding knowledge transfer mechanism, namely FedMEKT, which allows the server and clients to exchange the joint knowledge of their learning models extracted from a small multimodal proxy dataset. Our FedMEKT iteratively updates the generalized global encoders with the joint embedding knowledge from the participating clients. Thereby, to address the modality discrepancy and labeled data constraint in existing FL systems, our proposed FedMEKT comprises local multimodal autoencoder learning, generalized multimodal autoencoder construction, and generalized classifier learning. Through extensive experiments on three multimodal human activity recognition datasets, we demonstrate that FedMEKT achieves superior global encoder performance on linear evaluation and guarantees user privacy for personal data and model parameters while demanding less communication cost than other baselines.
CDKT-FL: Cross-Device Knowledge Transfer using Proxy Dataset in Federated Learning
Apr 04, 2022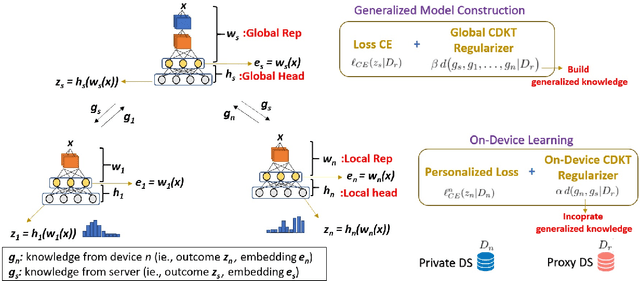
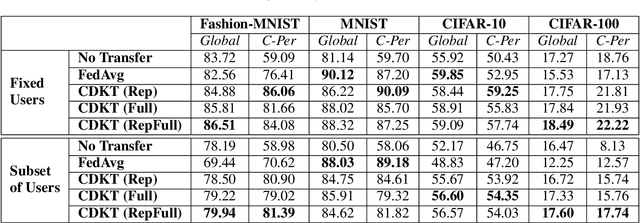
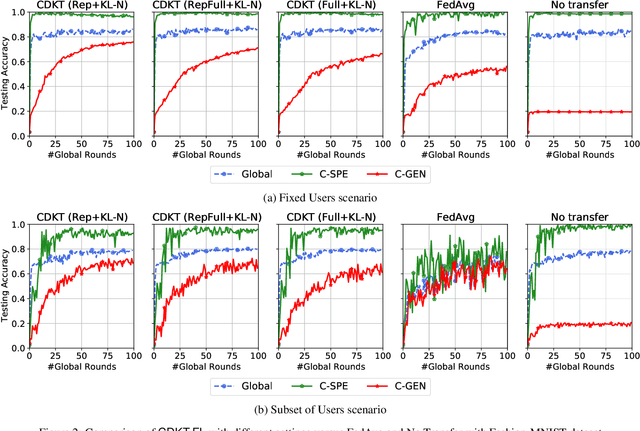
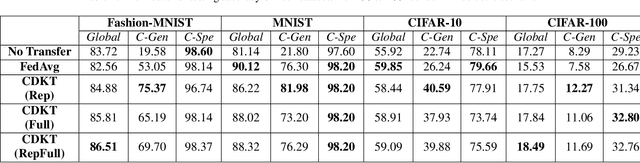
In a practical setting towards better generalization abilities of client models for realizing robust personalized Federated Learning (FL) systems, efficient model aggregation methods have been considered as a critical research objective. It is a challenging issue due to the consequences of non-i.i.d. properties of client's data, often referred to as statistical heterogeneity and small local data samples from the various data distributions. Therefore, to develop robust generalized global and personalized models, conventional FL methods need redesigning the knowledge aggregation from biased local models while considering huge divergence of learning parameters due to skewed client data. In this work, we demonstrate that the knowledge transfer mechanism is a de facto technique to achieve these objectives and develop a novel knowledge distillation-based approach to study the extent of knowledge transfer between the global model and local models. Henceforth, our method considers the suitability of transferring the outcome distribution and (or) the embedding vector of representation from trained models during cross-device knowledge transfer using a small proxy dataset in heterogeneous FL. In doing so, we alternatively perform cross-device knowledge transfer following general formulations as 1) global knowledge transfer and 2) on-device knowledge transfer. Through simulations on four federated datasets, we show the proposed method achieves significant speedups and high personalized performance of local models. Furthermore, the proposed approach offers a more stable algorithm than FedAvg during the training, with minimal communication data load when exchanging the trained model's outcomes and representation.
Edge-assisted Democratized Learning Towards Federated Analytics
Dec 01, 2020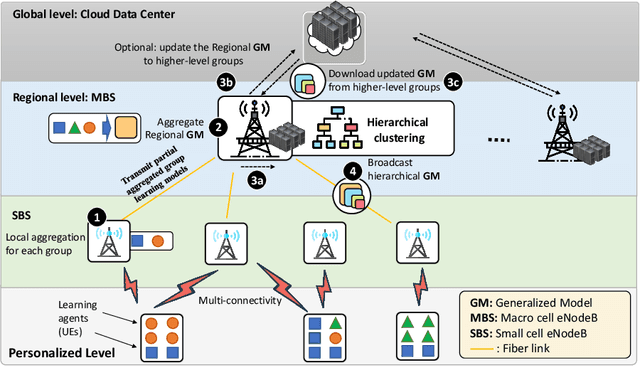
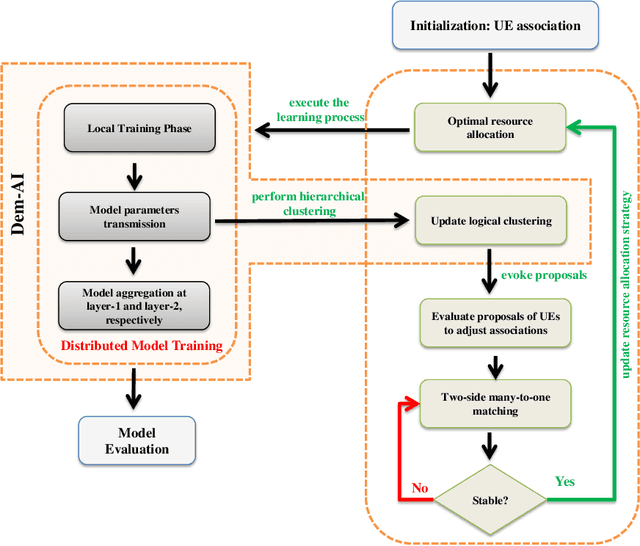
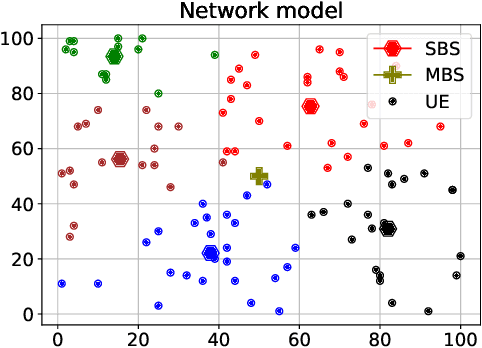
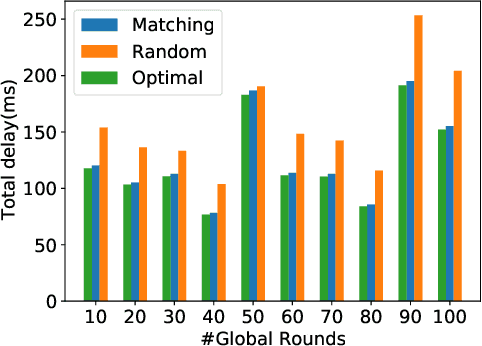
A recent take towards Federated Analytics (FA), which allows analytical insights of distributed datasets, reuses the Federated Learning (FL) infrastructure to evaluate the population-level summary of model performances. However, the current realization of FL adopts single server-multiple client architecture with limited scope for FA, which often results in learning models with poor generalization, i.e., an ability to handle new/unseen data, for real-world applications. Moreover, a hierarchical FL structure with distributed computing platforms demonstrates incoherent model performances at different aggregation levels. Therefore, we need to design a robust learning mechanism than the FL that (i) unleashes a viable infrastructure for FA and (ii) trains learning models with better generalization capability. In this work, we adopt the novel democratized learning (Dem-AI) principles and designs to meet these objectives. Firstly, we show the hierarchical learning structure of the proposed edge-assisted democratized learning mechanism, namely Edge-DemLearn, as a practical framework to empower generalization capability in support of FA. Secondly, we validate Edge-DemLearn as a flexible model training mechanism to build a distributed control and aggregation methodology in regions by leveraging the distributed computing infrastructure. The distributed edge computing servers construct regional models, minimize the communication loads, and ensure distributed data analytic application's scalability. To that end, we adhere to a near-optimal two-sided many-to-one matching approach to handle the combinatorial constraints in Edge-DemLearn and solve it for fast knowledge acquisition with optimization of resource allocation and associations between multiple servers and devices. Extensive simulation results on real datasets demonstrate the effectiveness of the proposed methods.