 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReliable Explanations or Random Noise? A Reliability Metric for XAI
Feb 04, 2026In recent years, explaining decisions made by complex machine learning models has become essential in high-stakes domains such as energy systems, healthcare, finance, and autonomous systems. However, the reliability of these explanations, namely, whether they remain stable and consistent under realistic, non-adversarial changes, remains largely unmeasured. Widely used methods such as SHAP and Integrated Gradients (IG) are well-motivated by axiomatic notions of attribution, yet their explanations can vary substantially even under system-level conditions, including small input perturbations, correlated representations, and minor model updates. Such variability undermines explanation reliability, as reliable explanations should remain consistent across equivalent input representations and small, performance-preserving model changes. We introduce the Explanation Reliability Index (ERI), a family of metrics that quantifies explanation stability under four reliability axioms: robustness to small input perturbations, consistency under feature redundancy, smoothness across model evolution, and resilience to mild distributional shifts. For each axiom, we derive formal guarantees, including Lipschitz-type bounds and temporal stability results. We further propose ERI-T, a dedicated measure of temporal reliability for sequential models, and introduce ERI-Bench, a benchmark designed to systematically stress-test explanation reliability across synthetic and real-world datasets. Experimental results reveal widespread reliability failures in popular explanation methods, showing that explanations can be unstable under realistic deployment conditions. By exposing and quantifying these instabilities, ERI enables principled assessment of explanation reliability and supports more trustworthy explainable AI (XAI) systems.
Context Dependence and Reliability in Autoregressive Language Models
Feb 01, 2026Large language models (LLMs) generate outputs by utilizing extensive context, which often includes redundant information from prompts, retrieved passages, and interaction history. In critical applications, it is vital to identify which context elements actually influence the output, as standard explanation methods struggle with redundancy and overlapping context. Minor changes in input can lead to unpredictable shifts in attribution scores, undermining interpretability and raising concerns about risks like prompt injection. This work addresses the challenge of distinguishing essential context elements from correlated ones. We introduce RISE (Redundancy-Insensitive Scoring of Explanation), a method that quantifies the unique influence of each input relative to others, minimizing the impact of redundancies and providing clearer, stable attributions. Experiments demonstrate that RISE offers more robust explanations than traditional methods, emphasizing the importance of conditional information for trustworthy LLM explanations and monitoring.
Explainability of Complex AI Models with Correlation Impact Ratio
Jan 10, 2026Complex AI systems make better predictions but often lack transparency, limiting trustworthiness, interpretability, and safe deployment. Common post hoc AI explainers, such as LIME, SHAP, HSIC, and SAGE, are model agnostic but are too restricted in one significant regard: they tend to misrank correlated features and require costly perturbations, which do not scale to high dimensional data. We introduce ExCIR (Explainability through Correlation Impact Ratio), a theoretically grounded, simple, and reliable metric for explaining the contribution of input features to model outputs, which remains stable and consistent under noise and sampling variations. We demonstrate that ExCIR captures dependencies arising from correlated features through a lightweight single pass formulation. Experimental evaluations on diverse datasets, including EEG, synthetic vehicular data, Digits, and Cats-Dogs, validate the effectiveness and stability of ExCIR across domains, achieving more interpretable feature explanations than existing methods while remaining computationally efficient. To this end, we further extend ExCIR with an information theoretic foundation that unifies the correlation ratio with Canonical Correlation Analysis under mutual information bounds, enabling multi output and class conditioned explainability at scale.
Link-Aware Energy-Frugal Continual Learning for Fault Detection in IoT Networks
Dec 15, 2025The use of lightweight machine learning (ML) models in internet of things (IoT) networks enables resource constrained IoT devices to perform on-device inference for several critical applications. However, the inference accuracy deteriorates due to the non-stationarity in the IoT environment and limited initial training data. To counteract this, the deployed models can be updated occasionally with new observed data samples. However, this approach consumes additional energy, which is undesirable for energy constrained IoT devices. This letter introduces an event-driven communication framework that strategically integrates continual learning (CL) in IoT networks for energy-efficient fault detection. Our framework enables the IoT device and the edge server (ES) to collaboratively update the lightweight ML model by adapting to the wireless link conditions for communication and the available energy budget. Evaluation on real-world datasets show that the proposed approach can outperform both periodic sampling and non-adaptive CL in terms of inference recall; our proposed approach achieves up to a 42.8% improvement, even under tight energy and bandwidth constraint.
Energy-Efficient Federated Learning with Relay-Assisted Aggregation in IIoT Networks
Dec 10, 2025This paper presents an energy-efficient transmission framework for federated learning (FL) in industrial Internet of Things (IIoT) environments with strict latency and energy constraints. Machinery subnetworks (SNs) collaboratively train a global model by uploading local updates to an edge server (ES), either directly or via neighboring SNs acting as decode-and-forward relays. To enhance communication efficiency, relays perform partial aggregation before forwarding the models to the ES, significantly reducing overhead and training latency. We analyze the convergence behavior of this relay-assisted FL scheme. To address the inherent energy efficiency (EE) challenges, we decompose the original non-convex optimization problem into sub-problems addressing computation and communication energy separately. An SN grouping algorithm categorizes devices into single-hop and two-hop transmitters based on latency minimization, followed by a relay selection mechanism. To improve FL reliability, we further maximize the number of SNs that meet the roundwise delay constraint, promoting broader participation and improved convergence stability under practical IIoT data distributions. Transmit power levels are then optimized to maximize EE, and a sequential parametric convex approximation (SPCA) method is proposed for joint configuration of system parameters. We further extend the EE formulation to the imperfect channel state information (ICSI). Simulation results demonstrate that the proposed framework significantly enhances convergence speed, reduces outage probability from 10-2 in single-hop to 10-6 and achieves substantial energy savings, with the SPCA approach reducing energy consumption by at least 2x compared to unaggregated cooperation and up to 6x over single-hop transmission.
Experimental Study of Low-Latency Video Streaming in an ORAN Setup with Generative AI
Dec 17, 2024Video streaming services depend on the underlying communication infrastructure and available network resources to offer ultra-low latency, high-quality content delivery. Open Radio Access Network (ORAN) provides a dynamic, programmable, and flexible RAN architecture that can be configured to support the requirements of time-critical applications. This work considers a setup in which the constrained network resources are supplemented by \gls{GAI} and \gls{MEC} {techniques} in order to reach a satisfactory video quality. Specifically, we implement a novel semantic control channel that enables \gls{MEC} to support low-latency applications by tight coupling among the ORAN xApp, \gls{MEC}, and the control channel. The proposed concepts are experimentally verified with an actual ORAN setup that supports video streaming. The performance evaluation includes the \gls{PSNR} metric and end-to-end latency. Our findings reveal that latency adjustments can yield gains in image \gls{PSNR}, underscoring the trade-off potential for optimized video quality in resource-limited environments.
Scalable Data Transmission Framework for Earth Observation Satellites with Channel Adaptation
Dec 16, 2024The immense volume of data generated by Earth observation (EO) satellites presents significant challenges in transmitting it to Earth over rate-limited satellite-to-ground communication links. This paper presents an efficient downlink framework for multi-spectral satellite images, leveraging adaptive transmission techniques based on pixel importance and link capacity. By integrating semantic communication principles, the framework prioritizes critical information, such as changed multi-spectral pixels, to optimize data transmission. The process involves preprocessing, assessing pixel importance to encode only significant changes, and dynamically adjusting transmissions to match channel conditions. Experimental results on the real dataset and simulated link demonstrate that the proposed approach ensures high-quality data delivery while significantly reducing number of transmitted data, making it highly suitable for satellite-based EO applications.
Time-constrained Federated Learning (FL) in Push-Pull IoT Wireless Access
Nov 13, 2024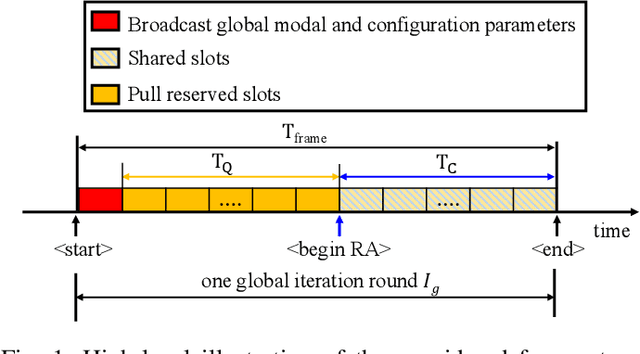
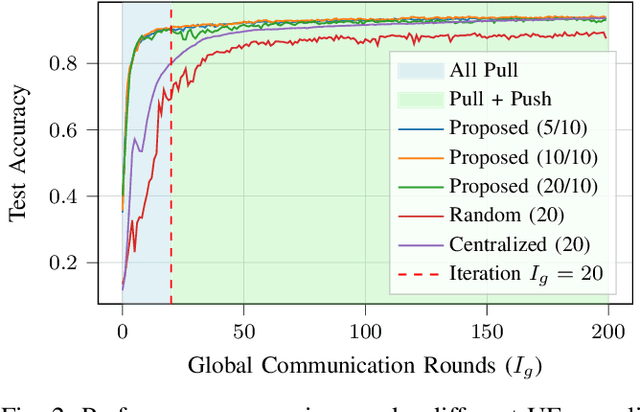
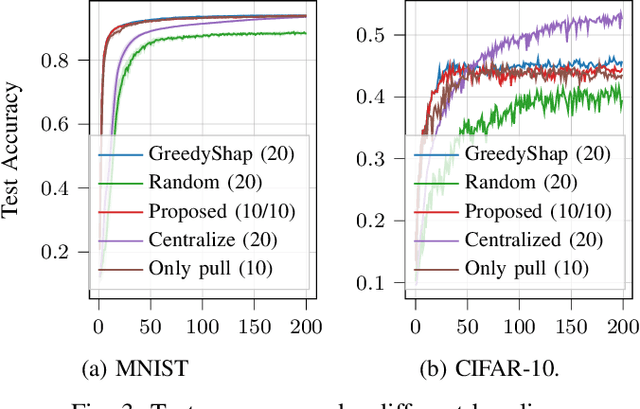
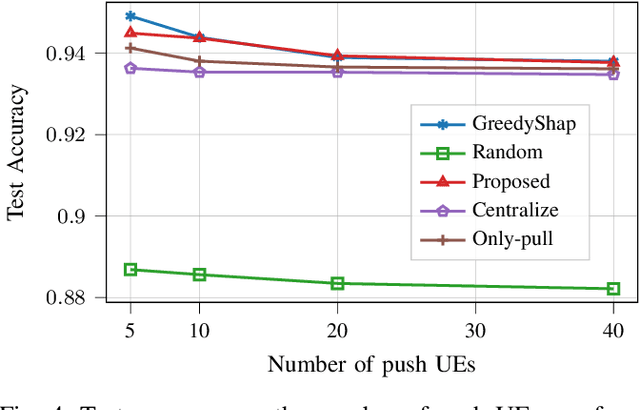
Training a high-quality Federated Learning (FL) model at the network edge is challenged by limited transmission resources. Although various device scheduling strategies have been proposed, it remains unclear how scheduling decisions affect the FL model performance under temporal constraints. This is pronounced when the wireless medium is shared to enable the participation of heterogeneous Internet of Things (IoT) devices with distinct communication modes: (1) a scheduling (pull) scheme, that selects devices with valuable updates, and (2) random access (push), in which interested devices transmit model parameters. The motivation for pushing data is the improved representation of own data distribution within the trained FL model and thereby better generalization. The scheduling strategy affects the transmission opportunities for push-based communication during the access phase, extending the number of communication rounds required for model convergence. This work investigates the interplay of push-pull interactions in a time-constrained FL setting, where the communication opportunities are finite, with a utility-based analytical model. Using real-world datasets, we provide a performance tradeoff analysis that validates the significance of strategic device scheduling under push-pull wireless access for several practical settings. The simulation results elucidate the impact of the device sampling strategy on learning efficiency under timing constraints.
Digital Twin for Autonomous Guided Vehicles based on Integrated Sensing and Communications
Sep 12, 2024



This paper presents a Digital Twin (DT) framework for the remote control of an Autonomous Guided Vehicle (AGV) within a Network Control System (NCS). The AGV is monitored and controlled using Integrated Sensing and Communications (ISAC). In order to meet the real-time requirements, the DT computes the control signals and dynamically allocates resources for sensing and communication. A Reinforcement Learning (RL) algorithm is derived to learn and provide suitable actions while adjusting for the uncertainty in the AGV's position. We present closed-form expressions for the achievable communication rate and the Cramer-Rao bound (CRB) to determine the required number of Orthogonal Frequency-Division Multiplexing (OFDM) subcarriers, meeting the needs of both sensing and communication. The proposed algorithm is validated through a millimeter-Wave (mmWave) simulation, demonstrating significant improvements in both control precision and communication efficiency.
Timely Communication from Sensors for Wireless Networked Control in Cloud-Based Digital Twins
Aug 05, 2024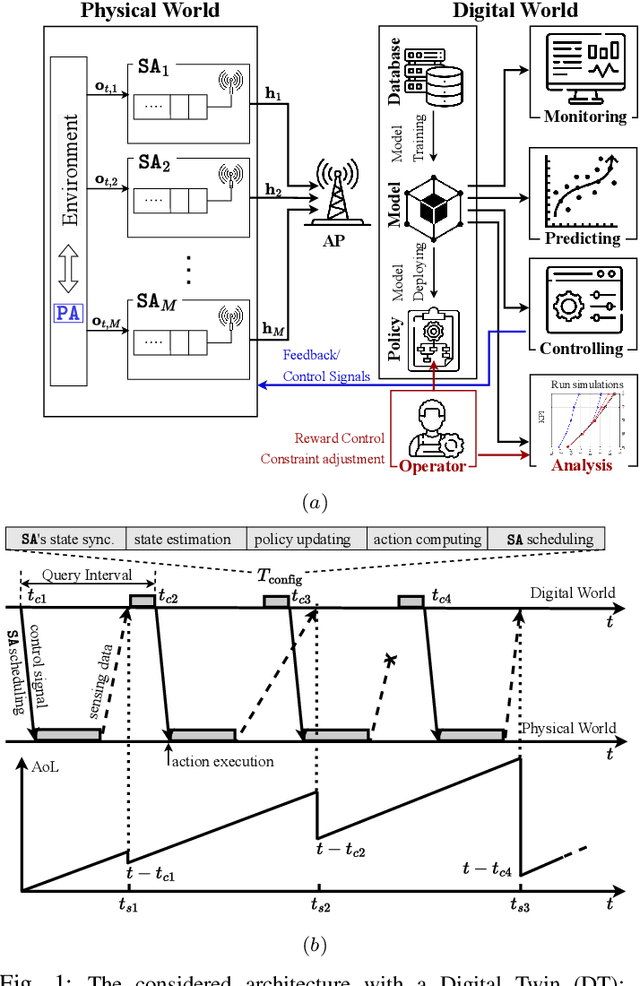
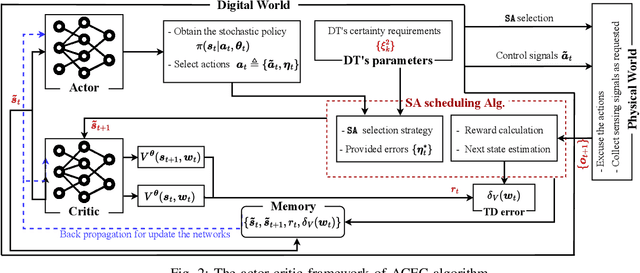
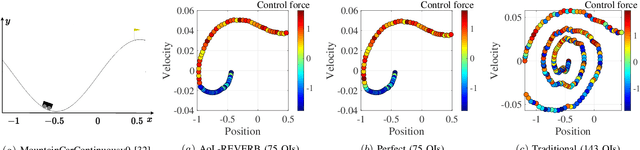
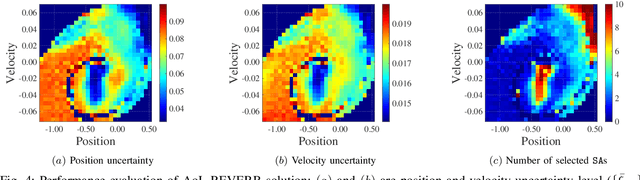
We consider a Wireless Networked Control System (WNCS) where sensors provide observations to build a DT model of the underlying system dynamics. The focus is on control, scheduling, and resource allocation for sensory observation to ensure timely delivery to the DT model deployed in the cloud. \phuc{Timely and relevant information, as characterized by optimized data acquisition policy and low latency, are instrumental in ensuring that the DT model can accurately estimate and predict system states. However, optimizing closed-loop control with DT and acquiring data for efficient state estimation and control computing pose a non-trivial problem given the limited network resources, partial state vector information, and measurement errors encountered at distributed sensing agents.} To address this, we propose the \emph{Age-of-Loop REinforcement learning and Variational Extended Kalman filter with Robust Belief (AoL-REVERB)}, which leverages an uncertainty-control reinforcement learning solution combined with an algorithm based on Value of Information (VoI) for performing optimal control and selecting the most informative sensors to satisfy the prediction accuracy of DT. Numerical results demonstrate that the DT platform can offer satisfactory performance while halving the communication overhead.