 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResource-Efficient Federated Multimodal Learning via Layer-wise and Progressive Training
Paper and Code
Jul 22, 2024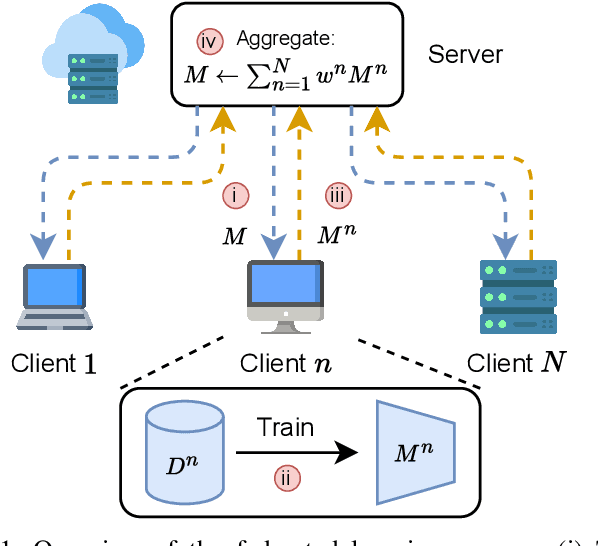
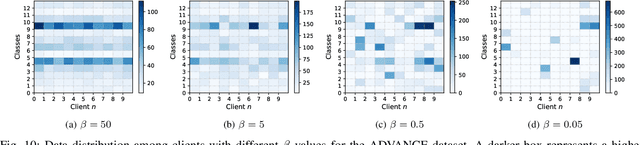
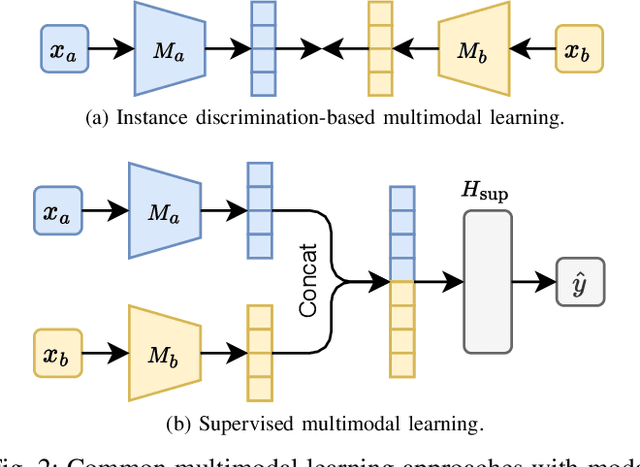
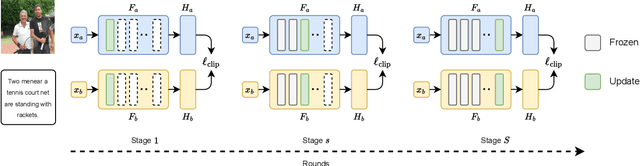
Combining different data modalities enables deep neural networks to tackle complex tasks more effectively, making multimodal learning increasingly popular. To harness multimodal data closer to end users, it is essential to integrate multimodal learning with privacy-preserving training approaches such as federated learning (FL). However, compared to conventional unimodal learning, multimodal setting requires dedicated encoders for each modality, resulting in larger and more complex models that demand significant resources. This presents a substantial challenge for FL clients operating with limited computational resources and communication bandwidth. To address these challenges, we introduce LW-FedMML, a layer-wise federated multimodal learning approach, which decomposes the training process into multiple steps. Each step focuses on training only a portion of the model, thereby significantly reducing the memory and computational requirements. Moreover, FL clients only need to exchange the trained model portion with the central server, lowering the resulting communication cost. We conduct extensive experiments across various FL scenarios and multimodal learning setups to validate the effectiveness of our proposed method. The results demonstrate that LW-FedMML can compete with conventional end-to-end federated multimodal learning (FedMML) while significantly reducing the resource burden on FL clients. Specifically, LW-FedMML reduces memory usage by up to $2.7\times$, computational operations (FLOPs) by $2.4\times$, and total communication cost by $2.3\times$. We also introduce a progressive training approach called Prog-FedMML. While it offers lesser resource efficiency than LW-FedMML, Prog-FedMML has the potential to surpass the performance of end-to-end FedMML, making it a viable option for scenarios with fewer resource constraints.