 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnDev-LCT: On-Device Lightweight Convolutional Transformers towards federated learning
Paper and Code
Jan 22, 2024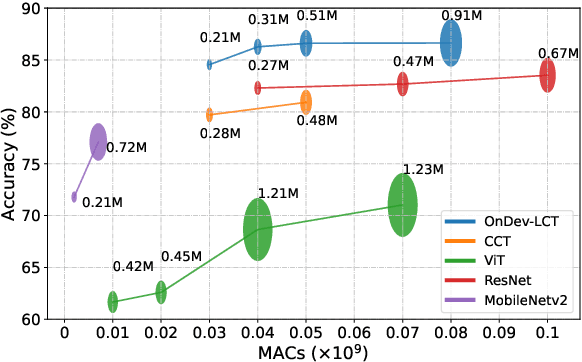
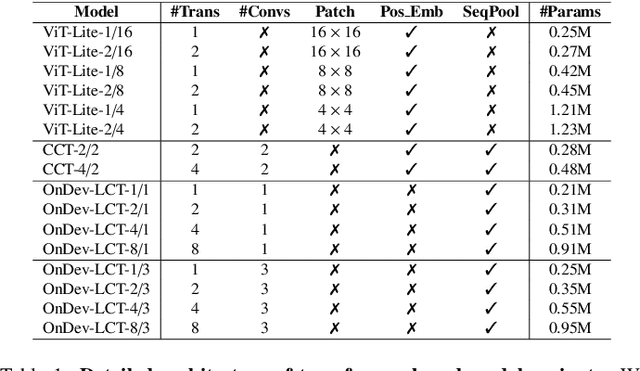
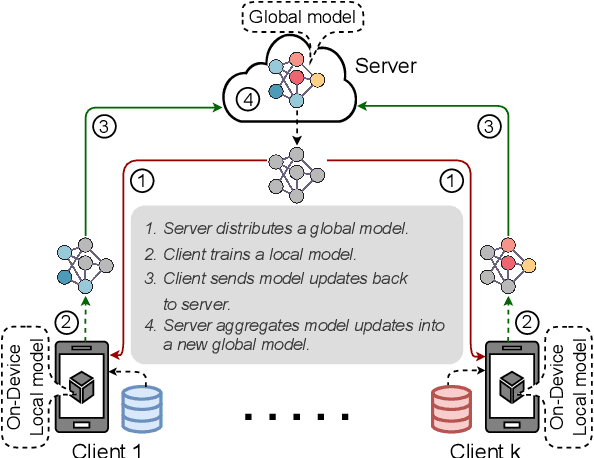
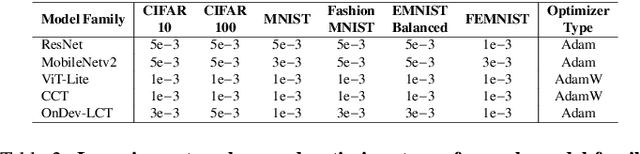
Federated learning (FL) has emerged as a promising approach to collaboratively train machine learning models across multiple edge devices while preserving privacy. The success of FL hinges on the efficiency of participating models and their ability to handle the unique challenges of distributed learning. While several variants of Vision Transformer (ViT) have shown great potential as alternatives to modern convolutional neural networks (CNNs) for centralized training, the unprecedented size and higher computational demands hinder their deployment on resource-constrained edge devices, challenging their widespread application in FL. Since client devices in FL typically have limited computing resources and communication bandwidth, models intended for such devices must strike a balance between model size, computational efficiency, and the ability to adapt to the diverse and non-IID data distributions encountered in FL. To address these challenges, we propose OnDev-LCT: Lightweight Convolutional Transformers for On-Device vision tasks with limited training data and resources. Our models incorporate image-specific inductive biases through the LCT tokenizer by leveraging efficient depthwise separable convolutions in residual linear bottleneck blocks to extract local features, while the multi-head self-attention (MHSA) mechanism in the LCT encoder implicitly facilitates capturing global representations of images. Extensive experiments on benchmark image datasets indicate that our models outperform existing lightweight vision models while having fewer parameters and lower computational demands, making them suitable for FL scenarios with data heterogeneity and communication bottlenecks.