 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCDKT-FL: Cross-Device Knowledge Transfer using Proxy Dataset in Federated Learning
Paper and Code
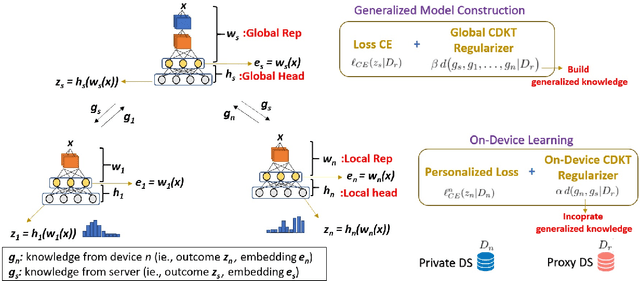
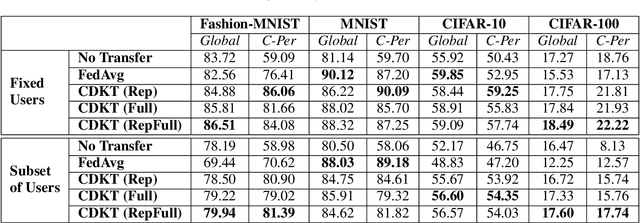
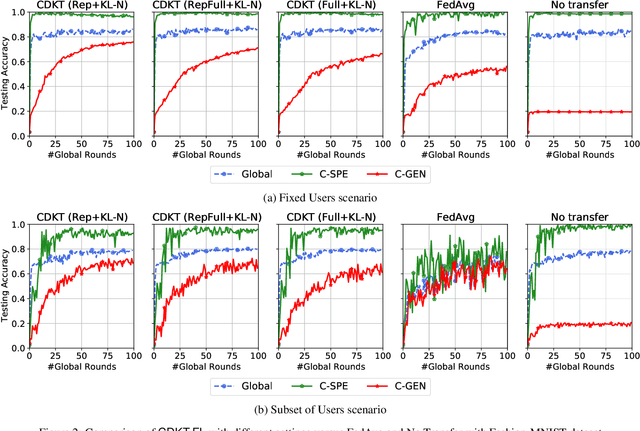
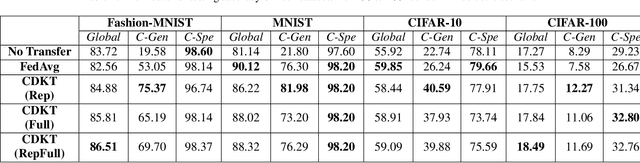
In a practical setting towards better generalization abilities of client models for realizing robust personalized Federated Learning (FL) systems, efficient model aggregation methods have been considered as a critical research objective. It is a challenging issue due to the consequences of non-i.i.d. properties of client's data, often referred to as statistical heterogeneity and small local data samples from the various data distributions. Therefore, to develop robust generalized global and personalized models, conventional FL methods need redesigning the knowledge aggregation from biased local models while considering huge divergence of learning parameters due to skewed client data. In this work, we demonstrate that the knowledge transfer mechanism is a de facto technique to achieve these objectives and develop a novel knowledge distillation-based approach to study the extent of knowledge transfer between the global model and local models. Henceforth, our method considers the suitability of transferring the outcome distribution and (or) the embedding vector of representation from trained models during cross-device knowledge transfer using a small proxy dataset in heterogeneous FL. In doing so, we alternatively perform cross-device knowledge transfer following general formulations as 1) global knowledge transfer and 2) on-device knowledge transfer. Through simulations on four federated datasets, we show the proposed method achieves significant speedups and high personalized performance of local models. Furthermore, the proposed approach offers a more stable algorithm than FedAvg during the training, with minimal communication data load when exchanging the trained model's outcomes and representation.