 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic AI as a Network Control-Plane Intelligence Layer for Federated Learning over 6G
Mar 11, 2026The shift toward user-customized on-device learning places new demands on wireless systems: models must be trained on diverse, distributed data while meeting strict latency, bandwidth, and reliability constraints. To address this, we propose an Agentic AI as the control layer for managing federated learning (FL) over 6G networks, which translates high-level task goals into actions that are aware of network conditions. Rather than simply viewing FL as a learning challenge, our system sees it as a combined task of learning and network management. A set of specialized agents focused on retrieval, planning, coding, and evaluation utilizes monitoring tools and optimization methods to handle client selection, incentive structuring, scheduling, resource allocation, adaptive local training, and code generation. The use of closed-loop evaluation and memory allows the system to consistently refine its decisions, taking into account varying signal-to-noise ratios, bandwidth conditions, and device capabilities. Finally, our case study has demonstrated the effectiveness of the Agentic AI system's use of tools for achieving high performance.
Towards Artificial General or Personalized Intelligence? A Survey on Foundation Models for Personalized Federated Intelligence
May 11, 2025



The rise of large language models (LLMs), such as ChatGPT, DeepSeek, and Grok-3, has reshaped the artificial intelligence landscape. As prominent examples of foundational models (FMs) built on LLMs, these models exhibit remarkable capabilities in generating human-like content, bringing us closer to achieving artificial general intelligence (AGI). However, their large-scale nature, sensitivity to privacy concerns, and substantial computational demands present significant challenges to personalized customization for end users. To bridge this gap, this paper presents the vision of artificial personalized intelligence (API), focusing on adapting these powerful models to meet the specific needs and preferences of users while maintaining privacy and efficiency. Specifically, this paper proposes personalized federated intelligence (PFI), which integrates the privacy-preserving advantages of federated learning (FL) with the zero-shot generalization capabilities of FMs, enabling personalized, efficient, and privacy-protective deployment at the edge. We first review recent advances in both FL and FMs, and discuss the potential of leveraging FMs to enhance federated systems. We then present the key motivations behind realizing PFI and explore promising opportunities in this space, including efficient PFI, trustworthy PFI, and PFI empowered by retrieval-augmented generation (RAG). Finally, we outline key challenges and future research directions for deploying FM-powered FL systems at the edge with improved personalization, computational efficiency, and privacy guarantees. Overall, this survey aims to lay the groundwork for the development of API as a complement to AGI, with a particular focus on PFI as a key enabling technique.
FedFeat+: A Robust Federated Learning Framework Through Federated Aggregation and Differentially Private Feature-Based Classifier Retraining
Apr 08, 2025In this paper, we propose the FedFeat+ framework, which distinctively separates feature extraction from classification. We develop a two-tiered model training process: following local training, clients transmit their weights and some features extracted from the feature extractor from the final local epochs to the server. The server aggregates these models using the FedAvg method and subsequently retrains the global classifier utilizing the shared features. The classifier retraining process enhances the model's understanding of the holistic view of the data distribution, ensuring better generalization across diverse datasets. This improved generalization enables the classifier to adaptively influence the feature extractor during subsequent local training epochs. We establish a balance between enhancing model accuracy and safeguarding individual privacy through the implementation of differential privacy mechanisms. By incorporating noise into the feature vectors shared with the server, we ensure that sensitive data remains confidential. We present a comprehensive convergence analysis, along with theoretical reasoning regarding performance enhancement and privacy preservation. We validate our approach through empirical evaluations conducted on benchmark datasets, including CIFAR-10, CIFAR-100, MNIST, and FMNIST, achieving high accuracy while adhering to stringent privacy guarantees. The experimental results demonstrate that the FedFeat+ framework, despite using only a lightweight two-layer CNN classifier, outperforms the FedAvg method in both IID and non-IID scenarios, achieving accuracy improvements ranging from 3.92 % to 12.34 % across CIFAR-10, CIFAR-100, and Fashion-MNIST datasets.
Federated Hybrid Training and Self-Adversarial Distillation: Towards Robust Edge Networks
Dec 26, 2024



Federated learning (FL) is a distributed training technology that enhances data privacy in mobile edge networks by allowing data owners to collaborate without transmitting raw data to the edge server. However, data heterogeneity and adversarial attacks pose challenges to develop an unbiased and robust global model for edge deployment. To address this, we propose Federated hyBrid Adversarial training and self-adversarial disTillation (FedBAT), a new framework designed to improve both robustness and generalization of the global model. FedBAT seamlessly integrates hybrid adversarial training and self-adversarial distillation into the conventional FL framework from data augmentation and feature distillation perspectives. From a data augmentation perspective, we propose hybrid adversarial training to defend against adversarial attacks by balancing accuracy and robustness through a weighted combination of standard and adversarial training. From a feature distillation perspective, we introduce a novel augmentation-invariant adversarial distillation method that aligns local adversarial features of augmented images with their corresponding unbiased global clean features. This alignment can effectively mitigate bias from data heterogeneity while enhancing both the robustness and generalization of the global model. Extensive experimental results across multiple datasets demonstrate that FedBAT yields comparable or superior performance gains in improving robustness while maintaining accuracy compared to several baselines.
QTSeg: A Query Token-Based Architecture for Efficient 2D Medical Image Segmentation
Dec 23, 2024Medical image segmentation is crucial in assisting medical doctors in making diagnoses and enabling accurate automatic diagnosis. While advanced convolutional neural networks (CNNs) excel in segmenting regions of interest with pixel-level precision, they often struggle with long-range dependencies, which is crucial for enhancing model performance. Conversely, transformer architectures leverage attention mechanisms to excel in handling long-range dependencies. However, the computational complexity of transformers grows quadratically, posing resource-intensive challenges, especially with high-resolution medical images. Recent research aims to combine CNN and transformer architectures to mitigate their drawbacks and enhance performance while keeping resource demands low. Nevertheless, existing approaches have not fully leveraged the strengths of both architectures to achieve high accuracy with low computational requirements. To address this gap, we propose a novel architecture for 2D medical image segmentation (QTSeg) that leverages a feature pyramid network (FPN) as the image encoder, a multi-level feature fusion (MLFF) as the adaptive module between encoder and decoder and a multi-query mask decoder (MQM Decoder) as the mask decoder. In the first step, an FPN model extracts pyramid features from the input image. Next, MLFF is incorporated between the encoder and decoder to adapt features from different encoder stages to the decoder. Finally, an MQM Decoder is employed to improve mask generation by integrating query tokens with pyramid features at all stages of the mask decoder. Our experimental results show that QTSeg outperforms state-of-the-art methods across all metrics with lower computational demands than the baseline and the existing methods. Code is available at https://github.com/tpnam0901/QTSeg (v0.1.0)
Federated Learning and RAG Integration: A Scalable Approach for Medical Large Language Models
Dec 18, 2024

This study analyzes the performance of domain-specific Large Language Models (LLMs) for the medical field by integrating Retrieval-Augmented Generation (RAG) systems within a federated learning framework. Leveraging the inherent advantages of federated learning, such as preserving data privacy and enabling distributed computation, this research explores the integration of RAG systems with models trained under varying client configurations to optimize performance. Experimental results demonstrate that the federated learning-based models integrated with RAG systems consistently outperform their non-integrated counterparts across all evaluation metrics. This study highlights the potential of combining federated learning and RAG systems for developing domain-specific LLMs in the medical field, providing a scalable and privacy-preserving solution for enhancing text generation capabilities.
CLIP-PING: Boosting Lightweight Vision-Language Models with Proximus Intrinsic Neighbors Guidance
Dec 05, 2024



Beyond the success of Contrastive Language-Image Pre-training (CLIP), recent trends mark a shift toward exploring the applicability of lightweight vision-language models for resource-constrained scenarios. These models often deliver suboptimal performance when relying solely on a single image-text contrastive learning objective, spotlighting the need for more effective training mechanisms that guarantee robust cross-modal feature alignment. In this work, we propose CLIP-PING: Contrastive Language-Image Pre-training with Proximus Intrinsic Neighbors Guidance, a simple and efficient training paradigm designed to boost the performance of lightweight vision-language models with minimal computational overhead and lower data demands. CLIP-PING bootstraps unimodal features extracted from arbitrary pre-trained encoders to obtain intrinsic guidance of proximus neighbor samples, i.e., nearest-neighbor (NN) and cross nearest-neighbor (XNN). We find that extra contrastive supervision from these neighbors substantially boosts cross-modal alignment, enabling lightweight models to learn more generic features with rich semantic diversity. Extensive experiments reveal that CLIP-PING notably surpasses its peers in zero-shot generalization and cross-modal retrieval tasks. Specifically, a 5.5% gain on zero-shot ImageNet1K with 10.7% (I2T) and 5.7% (T2I) on Flickr30K, compared to the original CLIP when using ViT-XS image encoder trained on 3 million (image, text) pairs. Moreover, CLIP-PING showcases strong transferability under the linear evaluation protocol across several downstream tasks.
Design Optimization of NOMA Aided Multi-STAR-RIS for Indoor Environments: A Convex Approximation Imitated Reinforcement Learning Approach
Jun 19, 2024



Sixth-generation (6G) networks leverage simultaneously transmitting and reflecting reconfigurable intelligent surfaces (STAR-RISs) to overcome the limitations of traditional RISs. STAR-RISs offer 360-degree full-space coverage and optimized transmission and reflection for enhanced network performance and dynamic control of the indoor propagation environment. However, deploying STAR-RISs indoors presents challenges in interference mitigation, power consumption, and real-time configuration. In this work, a novel network architecture utilizing multiple access points (APs) and STAR-RISs is proposed for indoor communication. An optimization problem encompassing user assignment, access point beamforming, and STAR-RIS phase control for reflection and transmission is formulated. The inherent complexity of the formulated problem necessitates a decomposition approach for an efficient solution. This involves tackling different sub-problems with specialized techniques: a many-to-one matching algorithm is employed to assign users to appropriate access points, optimizing resource allocation. To facilitate efficient resource management, access points are grouped using a correlation-based K-means clustering algorithm. Multi-agent deep reinforcement learning (MADRL) is leveraged to optimize the control of the STAR-RIS. Within the proposed MADRL framework, a novel approach is introduced where each decision variable acts as an independent agent, enabling collaborative learning and decision-making. Additionally, the proposed MADRL approach incorporates convex approximation (CA). This technique utilizes suboptimal solutions from successive convex approximation (SCA) to accelerate policy learning for the agents, thereby leading to faster environment adaptation and convergence. Simulations demonstrate significant network utility improvements compared to baseline approaches.
An Efficient Video Streaming Architecture with QoS Control for Virtual Desktop Infrastructure in Cloud Computing
Mar 11, 2022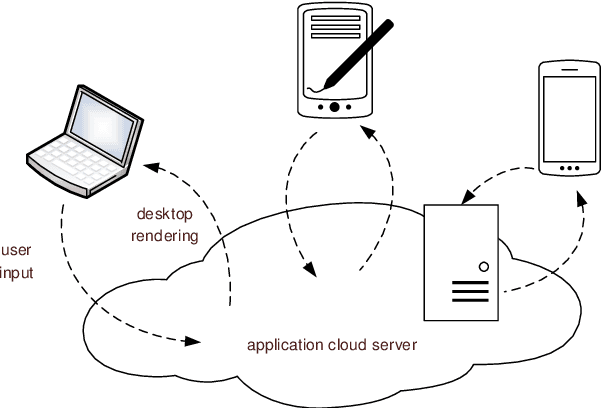

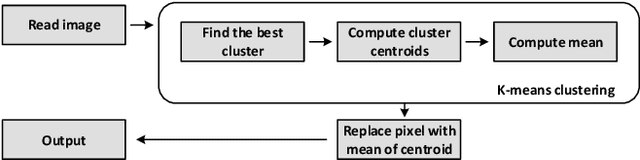
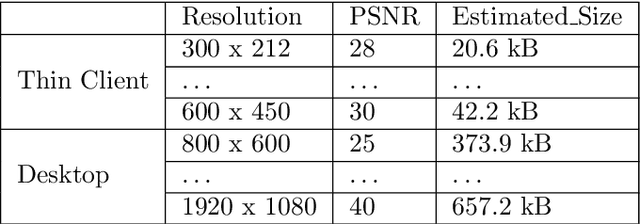
In virtual desktop infrastructure (VDI) environments, the remote display protocol has a big responsibility to transmit video data from a data center-hosted desktop to the endpoint. The protocol must ensure a high level of client perceived end-to-end quality of service (QoS) under heavy work load conditions. Each remote display protocol works differently depending on the network and which applications are being delivered. In healthcare applications, doctors and nurses can use mobile devices directly to monitor patients. Moreover, the ability to implement tasks requiring high consumption of CPU and other resources is applicable to a variety of applications including research and cloud gaming. Such computer games and complex processes will run on powerful cloud servers and the screen contents will be transmitted to the client. TO enable such applications, remote display technology requires further enhancements to meet more stringent requirements on bandwidth and QoS, an to allow realtime operation. In this paper, we present an architecture including flexible QoS control to improve the user quality of experience (QoE). The QoS control is developed based on linear regression modeling using historical network data. Additionally, the architecture includes a novel compression algorithm of 2D images, designed to guarantee the best image quality and to reduce video delay; this algorithm is based on k-means clustering and can satisfy the requirements of realtime onboard processing. Through simulations with a real work dataset collected by the MIT Computer Science and Artificial Lab, we present experimental as well as explain the performance of the QoS system.
Self-organizing Democratized Learning: Towards Large-scale Distributed Learning Systems
Jul 07, 2020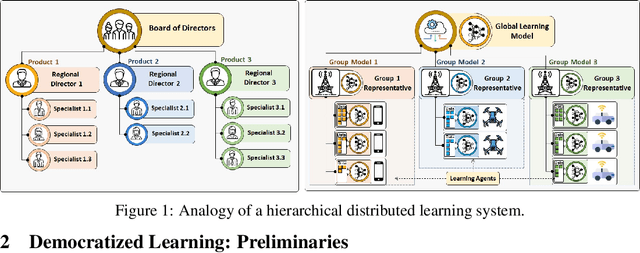
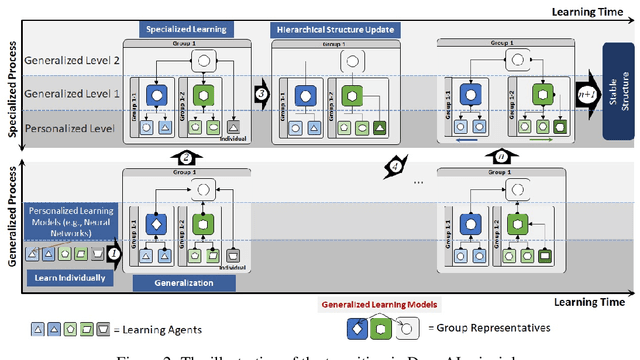
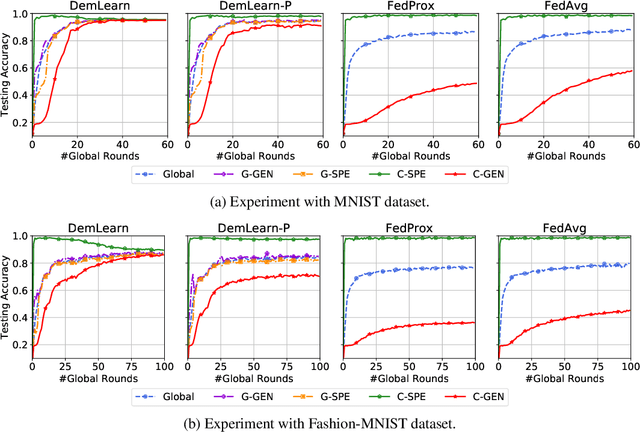
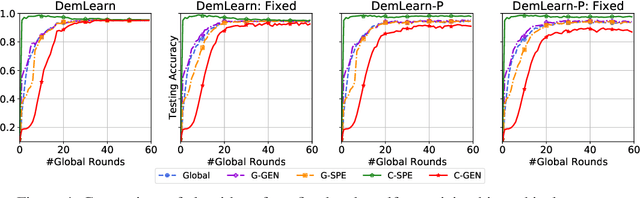
Emerging cross-device artificial intelligence (AI) applications require a transition from conventional centralized learning systems towards large-scale distributed AI systems that can collaboratively perform complex learning tasks. In this regard, democratized learning (Dem-AI) (Minh et al. 2020) lays out a holistic philosophy with underlying principles for building large-scale distributed and democratized machine learning systems. The outlined principles are meant to provide a generalization of distributed learning that goes beyond existing mechanisms such as federated learning. Inspired from this philosophy, a novel distributed learning approach is proposed in this paper. The approach consists of a self-organizing hierarchical structuring mechanism based on agglomerative clustering, hierarchical generalization, and corresponding learning mechanism. Subsequently, a hierarchical generalized learning problem in a recursive form is formulated and shown to be approximately solved using the solutions of distributed personalized learning problems and hierarchical generalized averaging mechanism. To that end, a distributed learning algorithm, namely DemLearn and its variant, DemLearn-P is proposed. Extensive experiments on benchmark MNIST and Fashion-MNIST datasets show that proposed algorithms demonstrate better results in the generalization performance of learning model at agents compared to the conventional FL algorithms. Detailed analysis provides useful configurations to further tune up both the generalization and specialization performance of the learning models in Dem-AI systems.