 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-Aware Hybrid Quantum Learning via Correlation-Guided Circuit Design for Crime Pattern Analytics
Apr 11, 2026Crime pattern analysis is critical for law enforcement and predictive policing, yet the surge in criminal activities from rapid urbanization creates high-dimensional, imbalanced datasets that challenge traditional classification methods. This study presents a quantum-classical comparison framework for crime analytics, evaluating four computational paradigms: quantum models, classical baseline machine learning models, and two hybrid quantum-classical architectures. Using 16-year crime statistics, we systematically assess classification performance and computational efficiency under rigorous cross-validation methods. Experimental results show that quantum-inspired approaches, particularly QAOA, achieve up to 84.6% accuracy, while requiring fewer trainable parameters than classical baselines, suggesting practical advantages for memory-constrained edge deployment. The proposed correlation-aware circuit design demonstrates the potential of incorporating domain-specific feature relationships into quantum models. Furthermore, hybrid approaches exhibit competitive training efficiency, making them suitable candidates for resource-constrained environments. The framework's low computational overhead and compact parameter footprint suggest potential advantages for wireless sensor network deployments in smart city surveillance systems, where distributed nodes perform localized crime analytics with minimal communication costs. Our findings provide a preliminary empirical assessment of quantum-enhanced machine learning for structured crime data and motivate further investigation with larger datasets and realistic quantum hardware considerations.
A Novel Edge-Assisted Quantum-Classical Hybrid Framework for Crime Pattern Learning and Classification
Apr 08, 2026Crime pattern analysis is critical for law enforcement and predictive policing, yet the surge in criminal activities from rapid urbanization creates high-dimensional, imbalanced datasets that challenge traditional classification methods. This study presents a quantum-classical comparison framework for crime analytics, evaluating four computational paradigms: quantum models, classical baseline machine learning models, and two hybrid quantum-classical architectures. Using 16-year Bangladesh crime statistics, we systematically assess classification performance and computational efficiency under rigorous cross-validation methods. Experimental results show that quantum-inspired approaches, particularly QAOA, achieve up to 84.6% accuracy, while requiring fewer trainable parameters than classical baselines, suggesting practical advantages for memory-constrained edge deployment. The proposed correlation-aware circuit design demonstrates the potential of incorporating domain-specific feature relationships into quantum models. Furthermore, hybrid approaches exhibit competitive training efficiency, making them suitable candidates for resource-constrained environments. The framework's low computational overhead and compact parameter footprint suggest potential advantages for wireless sensor network deployments in smart city surveillance systems, where distributed nodes perform localized crime analytics with minimal communication costs. Our findings provide a preliminary empirical assessment of quantum-enhanced machine learning for structured crime data and motivate further investigation with larger datasets and realistic quantum hardware considerations.
A Multi-Prototype-Guided Federated Knowledge Distillation Approach in AI-RAN Enabled Multi-Access Edge Computing System
Mar 10, 2026With the development of wireless network, Multi-Access Edge Computing (MEC) and Artificial Intelligence (AI)-native Radio Access Network (RAN) have attracted significant attention. Particularly, the integration of AI-RAN and MEC is envisioned to transform network efficiency and responsiveness. Therefore, it is valuable to investigate AI-RAN enabled MEC system. Federated learning (FL) nowadays is emerging as a promising approach for AI-RAN enabled MEC system, in which edge devices are enabled to train a global model cooperatively without revealing their raw data. However, conventional FL encounters the challenge in processing the non-independent and identically distributed (non-IID) data. Single prototype obtained by averaging the embedding vectors per class can be employed in FL to handle the data heterogeneity issue. Nevertheless, this may result in the loss of useful information owing to the average operation. Therefore, in this paper, a multi-prototype-guided federated knowledge distillation (MP-FedKD) approach is proposed. Particularly, self-knowledge distillation is integrated into FL to deal with the non-IID issue. To cope with the problem of information loss caused by single prototype-based strategy, multi-prototype strategy is adopted, where we present a conditional hierarchical agglomerative clustering (CHAC) approach and a prototype alignment scheme. Additionally, we design a novel loss function (called LEMGP loss) for each local client, where the relationship between global prototypes and local embedding will be focused. Extensive experiments over multiple datasets with various non-IID settings showcase that the proposed MP-FedKD approach outperforms the considered state-of-the-art baselines regarding accuracy, average accuracy and errors (RMSE and MAE).
Geometric Knowledge-Assisted Federated Dual Knowledge Distillation Approach Towards Remote Sensing Satellite Imagery
Mar 08, 2026Federated learning (FL) has recently become a promising solution for analyzing remote sensing satellite imagery (RSSI). However, the large scale and inherent data heterogeneity of images collected from multiple satellites, where the local data distribution of each satellite differs from the global one, present significant challenges to effective model training. To address this issue, we propose a Geometric Knowledge-Guided Federated Dual Knowledge Distillation (GK-FedDKD) framework for RSSI analysis. In our approach, each local client first distills a teacher encoder (TE) from multiple student encoders (SEs) trained with unlabeled augmented data. The TE is then connected with a shared classifier to form a teacher network (TN) that supervises the training of a new student network (SN). The intermediate representations of the TN are used to compute local covariance matrices, which are aggregated at the server to generate global geometric knowledge (GGK). This GGK is subsequently employed for local embedding augmentation to further guide SN training. We also design a novel loss function and a multi-prototype generation pipeline to stabilize the training process. Evaluation over multiple datasets showcases that the proposed GK-FedDKD approach is superior to the considered state-of-the-art baselines, e.g., the proposed approach with the Swin-T backbone surpasses previous SOTA approaches by an average 68.89% on the EuroSAT dataset.
Towards Artificial General or Personalized Intelligence? A Survey on Foundation Models for Personalized Federated Intelligence
May 11, 2025



The rise of large language models (LLMs), such as ChatGPT, DeepSeek, and Grok-3, has reshaped the artificial intelligence landscape. As prominent examples of foundational models (FMs) built on LLMs, these models exhibit remarkable capabilities in generating human-like content, bringing us closer to achieving artificial general intelligence (AGI). However, their large-scale nature, sensitivity to privacy concerns, and substantial computational demands present significant challenges to personalized customization for end users. To bridge this gap, this paper presents the vision of artificial personalized intelligence (API), focusing on adapting these powerful models to meet the specific needs and preferences of users while maintaining privacy and efficiency. Specifically, this paper proposes personalized federated intelligence (PFI), which integrates the privacy-preserving advantages of federated learning (FL) with the zero-shot generalization capabilities of FMs, enabling personalized, efficient, and privacy-protective deployment at the edge. We first review recent advances in both FL and FMs, and discuss the potential of leveraging FMs to enhance federated systems. We then present the key motivations behind realizing PFI and explore promising opportunities in this space, including efficient PFI, trustworthy PFI, and PFI empowered by retrieval-augmented generation (RAG). Finally, we outline key challenges and future research directions for deploying FM-powered FL systems at the edge with improved personalization, computational efficiency, and privacy guarantees. Overall, this survey aims to lay the groundwork for the development of API as a complement to AGI, with a particular focus on PFI as a key enabling technique.
FedFeat+: A Robust Federated Learning Framework Through Federated Aggregation and Differentially Private Feature-Based Classifier Retraining
Apr 08, 2025In this paper, we propose the FedFeat+ framework, which distinctively separates feature extraction from classification. We develop a two-tiered model training process: following local training, clients transmit their weights and some features extracted from the feature extractor from the final local epochs to the server. The server aggregates these models using the FedAvg method and subsequently retrains the global classifier utilizing the shared features. The classifier retraining process enhances the model's understanding of the holistic view of the data distribution, ensuring better generalization across diverse datasets. This improved generalization enables the classifier to adaptively influence the feature extractor during subsequent local training epochs. We establish a balance between enhancing model accuracy and safeguarding individual privacy through the implementation of differential privacy mechanisms. By incorporating noise into the feature vectors shared with the server, we ensure that sensitive data remains confidential. We present a comprehensive convergence analysis, along with theoretical reasoning regarding performance enhancement and privacy preservation. We validate our approach through empirical evaluations conducted on benchmark datasets, including CIFAR-10, CIFAR-100, MNIST, and FMNIST, achieving high accuracy while adhering to stringent privacy guarantees. The experimental results demonstrate that the FedFeat+ framework, despite using only a lightweight two-layer CNN classifier, outperforms the FedAvg method in both IID and non-IID scenarios, achieving accuracy improvements ranging from 3.92 % to 12.34 % across CIFAR-10, CIFAR-100, and Fashion-MNIST datasets.
Pre-trained Model Guided Mixture Knowledge Distillation for Adversarial Federated Learning
Jan 25, 2025



This paper aims to improve the robustness of a small global model while maintaining clean accuracy under adversarial attacks and non-IID challenges in federated learning. By leveraging the concise knowledge embedded in the class probabilities from a pre-trained model for both clean and adversarial image classification, we propose a Pre-trained Model-guided Adversarial Federated Learning (PM-AFL) training paradigm. This paradigm integrates vanilla mixture and adversarial mixture knowledge distillation to effectively balance accuracy and robustness while promoting local models to learn from diverse data. Specifically, for clean accuracy, we adopt a dual distillation strategy where the class probabilities of randomly paired images and their blended versions are aligned between the teacher model and the local models. For adversarial robustness, we use a similar distillation approach but replace clean samples on the local side with adversarial examples. Moreover, considering the bias between local and global models, we also incorporate a consistency regularization term to ensure that local adversarial predictions stay aligned with their corresponding global clean ones. These strategies collectively enable local models to absorb diverse knowledge from the teacher model while maintaining close alignment with the global model, thereby mitigating overfitting to local optima and enhancing the generalization of the global model. Experiments demonstrate that the PM-AFL-based paradigm outperforms other methods that integrate defense strategies by a notable margin.
Federated Hybrid Training and Self-Adversarial Distillation: Towards Robust Edge Networks
Dec 26, 2024



Federated learning (FL) is a distributed training technology that enhances data privacy in mobile edge networks by allowing data owners to collaborate without transmitting raw data to the edge server. However, data heterogeneity and adversarial attacks pose challenges to develop an unbiased and robust global model for edge deployment. To address this, we propose Federated hyBrid Adversarial training and self-adversarial disTillation (FedBAT), a new framework designed to improve both robustness and generalization of the global model. FedBAT seamlessly integrates hybrid adversarial training and self-adversarial distillation into the conventional FL framework from data augmentation and feature distillation perspectives. From a data augmentation perspective, we propose hybrid adversarial training to defend against adversarial attacks by balancing accuracy and robustness through a weighted combination of standard and adversarial training. From a feature distillation perspective, we introduce a novel augmentation-invariant adversarial distillation method that aligns local adversarial features of augmented images with their corresponding unbiased global clean features. This alignment can effectively mitigate bias from data heterogeneity while enhancing both the robustness and generalization of the global model. Extensive experimental results across multiple datasets demonstrate that FedBAT yields comparable or superior performance gains in improving robustness while maintaining accuracy compared to several baselines.
Advancing Ultra-Reliable 6G: Transformer and Semantic Localization Empowered Robust Beamforming in Millimeter-Wave Communications
Jun 04, 2024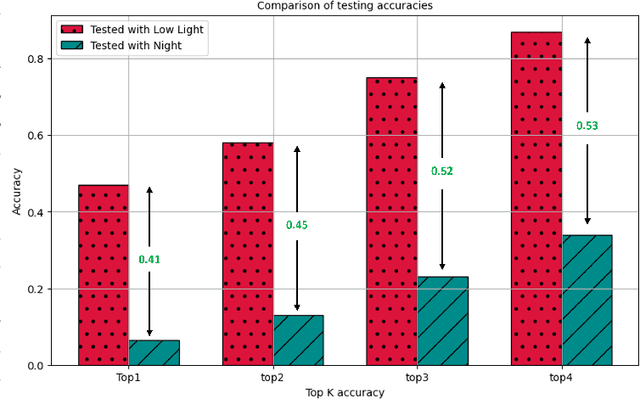
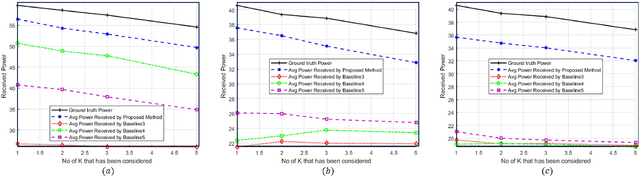
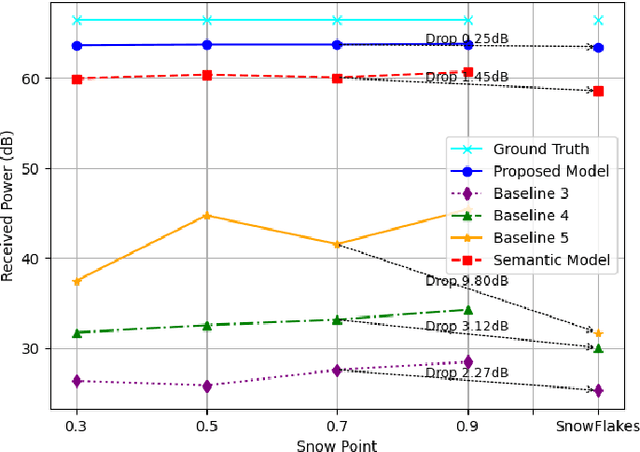
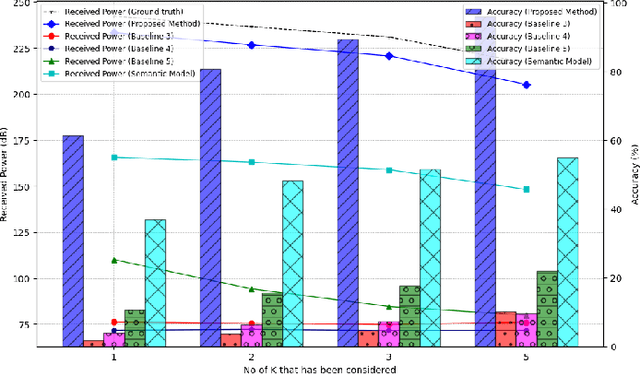
Advancements in 6G wireless technology have elevated the importance of beamforming, especially for attaining ultra-high data rates via millimeter-wave (mmWave) frequency deployment. Although promising, mmWave bands require substantial beam training to achieve precise beamforming. While initial deep learning models that use RGB camera images demonstrated promise in reducing beam training overhead, their performance suffers due to sensitivity to lighting and environmental variations. Due to this sensitivity, Quality of Service (QoS) fluctuates, eventually affecting the stability and dependability of networks in dynamic environments. This emphasizes a critical need for more robust solutions. This paper proposes a robust beamforming technique to ensure consistent QoS under varying environmental conditions. An optimization problem has been formulated to maximize users' data rates. To solve the formulated NP-hard optimization problem, we decompose it into two subproblems: the semantic localization problem and the optimal beam selection problem. To solve the semantic localization problem, we propose a novel method that leverages the k-means clustering and YOLOv8 model. To solve the beam selection problem, we propose a novel lightweight hybrid architecture that utilizes various data sources and a weighted entropy-based mechanism to predict the optimal beams. Rapid and accurate beam predictions are needed to maintain QoS. A novel metric, Accuracy-Complexity Efficiency (ACE), has been proposed to quantify this. Six testing scenarios have been developed to evaluate the robustness of the proposed model. Finally, the simulation result demonstrates that the proposed model outperforms several state-of-the-art baselines regarding beam prediction accuracy, received power, and ACE in the developed test scenarios.
FedCCL: Federated Dual-Clustered Feature Contrast Under Domain Heterogeneity
Apr 14, 2024



Federated learning (FL) facilitates a privacy-preserving neural network training paradigm through collaboration between edge clients and a central server. One significant challenge is that the distributed data is not independently and identically distributed (non-IID), typically including both intra-domain and inter-domain heterogeneity. However, recent research is limited to simply using averaged signals as a form of regularization and only focusing on one aspect of these non-IID challenges. Given these limitations, this paper clarifies these two non-IID challenges and attempts to introduce cluster representation to address them from both local and global perspectives. Specifically, we propose a dual-clustered feature contrast-based FL framework with dual focuses. First, we employ clustering on the local representations of each client, aiming to capture intra-class information based on these local clusters at a high level of granularity. Then, we facilitate cross-client knowledge sharing by pulling the local representation closer to clusters shared by clients with similar semantics while pushing them away from clusters with dissimilar semantics. Second, since the sizes of local clusters belonging to the same class may differ for each client, we further utilize clustering on the global side and conduct averaging to create a consistent global signal for guiding each local training in a contrastive manner. Experimental results on multiple datasets demonstrate that our proposal achieves comparable or superior performance gain under intra-domain and inter-domain heterogeneity.