 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonkey Jump : MoE-Style PEFT for Efficient Multi-Task Learning
Jan 09, 2026Mixture-of-experts variants of parameter-efficient fine-tuning enable per-token specialization, but they introduce additional trainable routers and expert parameters, increasing memory usage and training cost. This undermines the core goal of parameter-efficient fine-tuning. We propose Monkey Jump, a method that brings mixture-of-experts-style specialization to parameter-efficient fine-tuning without introducing extra trainable parameters for experts or routers. Instead of adding new adapters as experts, Monkey Jump treats the adapters already present in each Transformer block (such as query, key, value, up, and down projections) as implicit experts and routes tokens among them. Routing is performed using k-means clustering with exponentially moving averaged cluster centers, requiring no gradients and no learned parameters. We theoretically show that token-wise routing increases expressivity and can outperform shared adapters by avoiding cancellation effects. Across multi-task experiments covering 14 text, 14 image, and 19 video benchmarks, Monkey Jump achieves competitive performance with mixture-of-experts-based parameter-efficient fine-tuning methods while using 7 to 29 times fewer trainable parameters, up to 48 percent lower memory consumption, and 1.5 to 2 times faster training. Monkey Jump is architecture-agnostic and can be applied to any adapter-based parameter-efficient fine-tuning method.
Explainable Detection of Implicit Influential Patterns in Conversations via Data Augmentation
Jun 17, 2025In the era of digitalization, as individuals increasingly rely on digital platforms for communication and news consumption, various actors employ linguistic strategies to influence public perception. While models have become proficient at detecting explicit patterns, which typically appear in texts as single remarks referred to as utterances, such as social media posts, malicious actors have shifted toward utilizing implicit influential verbal patterns embedded within conversations. These verbal patterns aim to mentally penetrate the victim's mind in order to influence them, enabling the actor to obtain the desired information through implicit means. This paper presents an improved approach for detecting such implicit influential patterns. Furthermore, the proposed model is capable of identifying the specific locations of these influential elements within a conversation. To achieve this, the existing dataset was augmented using the reasoning capabilities of state-of-the-art language models. Our designed framework resulted in a 6% improvement in the detection of implicit influential patterns in conversations. Moreover, this approach improved the multi-label classification tasks related to both the techniques used for influence and the vulnerability of victims by 33% and 43%, respectively.
PEFT A2Z: Parameter-Efficient Fine-Tuning Survey for Large Language and Vision Models
Apr 19, 2025



Large models such as Large Language Models (LLMs) and Vision Language Models (VLMs) have transformed artificial intelligence, powering applications in natural language processing, computer vision, and multimodal learning. However, fully fine-tuning these models remains expensive, requiring extensive computational resources, memory, and task-specific data. Parameter-Efficient Fine-Tuning (PEFT) has emerged as a promising solution that allows adapting large models to downstream tasks by updating only a small portion of parameters. This survey presents a comprehensive overview of PEFT techniques, focusing on their motivations, design principles, and effectiveness. We begin by analyzing the resource and accessibility challenges posed by traditional fine-tuning and highlight key issues, such as overfitting, catastrophic forgetting, and parameter inefficiency. We then introduce a structured taxonomy of PEFT methods -- grouped into additive, selective, reparameterized, hybrid, and unified frameworks -- and systematically compare their mechanisms and trade-offs. Beyond taxonomy, we explore the impact of PEFT across diverse domains, including language, vision, and generative modeling, showing how these techniques offer strong performance with lower resource costs. We also discuss important open challenges in scalability, interpretability, and robustness, and suggest future directions such as federated learning, domain adaptation, and theoretical grounding. Our goal is to provide a unified understanding of PEFT and its growing role in enabling practical, efficient, and sustainable use of large models.
Predicting Through Generation: Why Generation Is Better for Prediction
Feb 25, 2025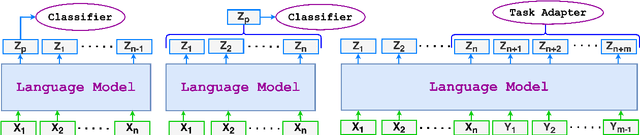
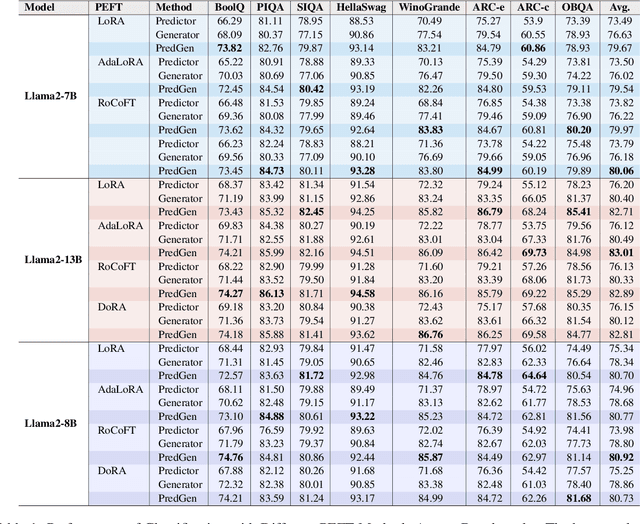
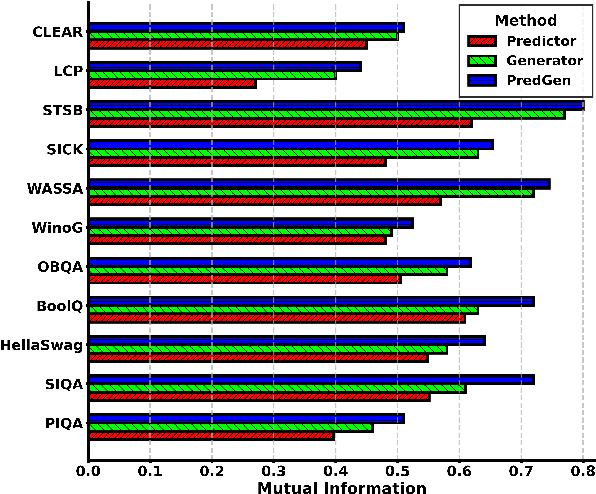
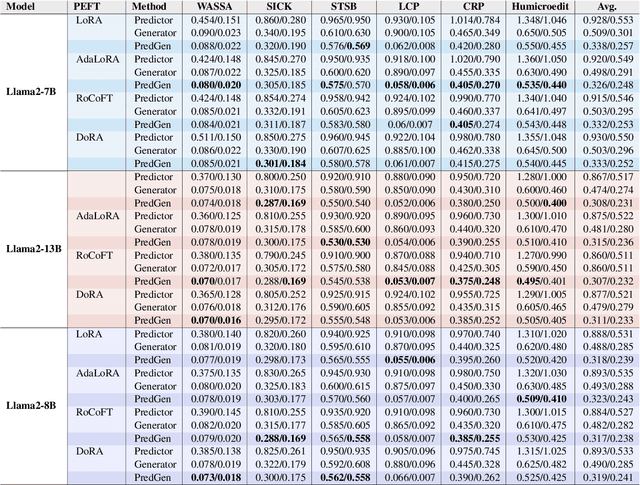
This paper argues that generating output tokens is more effective than using pooled representations for prediction tasks because token-level generation retains more mutual information. Since LLMs are trained on massive text corpora using next-token prediction, generation aligns naturally with their learned behavior. Using the Data Processing Inequality (DPI), we provide both theoretical and empirical evidence supporting this claim. However, autoregressive models face two key challenges when used for prediction: (1) exposure bias, where the model sees ground truth tokens during training but relies on its own predictions during inference, leading to errors, and (2) format mismatch, where discrete tokens do not always align with the tasks required output structure. To address these challenges, we introduce PredGen(Predicting Through Generating), an end to end framework that (i) uses scheduled sampling to reduce exposure bias, and (ii) introduces a task adapter to convert the generated tokens into structured outputs. Additionally, we introduce Writer-Director Alignment Loss (WDAL), which ensures consistency between token generation and final task predictions, improving both text coherence and numerical accuracy. We evaluate PredGen on multiple classification and regression benchmarks. Our results show that PredGen consistently outperforms standard baselines, demonstrating its effectiveness in structured prediction tasks.
BnTTS: Few-Shot Speaker Adaptation in Low-Resource Setting
Feb 09, 2025



This paper introduces BnTTS (Bangla Text-To-Speech), the first framework for Bangla speaker adaptation-based TTS, designed to bridge the gap in Bangla speech synthesis using minimal training data. Building upon the XTTS architecture, our approach integrates Bangla into a multilingual TTS pipeline, with modifications to account for the phonetic and linguistic characteristics of the language. We pre-train BnTTS on 3.85k hours of Bangla speech dataset with corresponding text labels and evaluate performance in both zero-shot and few-shot settings on our proposed test dataset. Empirical evaluations in few-shot settings show that BnTTS significantly improves the naturalness, intelligibility, and speaker fidelity of synthesized Bangla speech. Compared to state-of-the-art Bangla TTS systems, BnTTS exhibits superior performance in Subjective Mean Opinion Score (SMOS), Naturalness, and Clarity metrics.
Does Self-Attention Need Separate Weights in Transformers?
Nov 30, 2024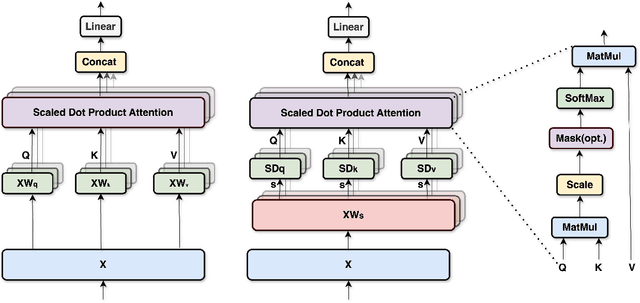

The success of self-attention lies in its ability to capture long-range dependencies and enhance context understanding, but it is limited by its computational complexity and challenges in handling sequential data with inherent directionality. This work introduces a shared weight self-attention-based BERT model that only learns one weight matrix for (Key, Value, and Query) representations instead of three individual matrices for each of them. Our shared weight attention reduces the training parameter size by more than half and training time by around one-tenth. Furthermore, we demonstrate higher prediction accuracy on small tasks of GLUE over the BERT baseline and in particular a generalization power on noisy and out-of-domain data. Experimental results indicate that our shared self-attention method achieves a parameter size reduction of 66.53% in the attention block. In the GLUE dataset, the shared weight self-attention-based BERT model demonstrates accuracy improvements of 0.38%, 5.81%, and 1.06% over the standard, symmetric, and pairwise attention-based BERT models, respectively. The model and source code are available at Anonymous.
RoCoFT: Efficient Finetuning of Large Language Models with Row-Column Updates
Oct 15, 2024



We propose RoCoFT, a parameter-efficient fine-tuning method for large-scale language models (LMs) based on updating only a few rows and columns of the weight matrices in transformers. Through extensive experiments with medium-size LMs like BERT and RoBERTa, and larger LMs like Bloom-7B, Llama2-7B, and Llama2-13B, we show that our method gives comparable or better accuracies than state-of-art PEFT methods while also being more memory and computation-efficient. We also study the reason behind the effectiveness of our method with tools from neural tangent kernel theory. We empirically demonstrate that our kernel, constructed using a restricted set of row and column parameters, are numerically close to the full-parameter kernel and gives comparable classification performance. Ablation studies are conducted to investigate the impact of different algorithmic choices, including the selection strategy for rows and columns as well as the optimal rank for effective implementation of our method.
LLM-Mixer: Multiscale Mixing in LLMs for Time Series Forecasting
Oct 15, 2024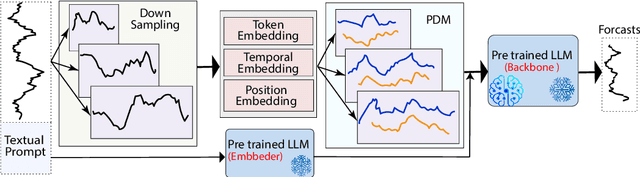


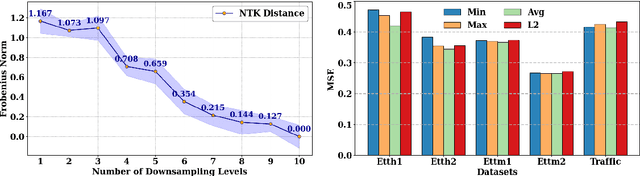
Time series forecasting remains a challenging task, particularly in the context of complex multiscale temporal patterns. This study presents LLM-Mixer, a framework that improves forecasting accuracy through the combination of multiscale time-series decomposition with pre-trained LLMs (Large Language Models). LLM-Mixer captures both short-term fluctuations and long-term trends by decomposing the data into multiple temporal resolutions and processing them with a frozen LLM, guided by a textual prompt specifically designed for time-series data. Extensive experiments conducted on multivariate and univariate datasets demonstrate that LLM-Mixer achieves competitive performance, outperforming recent state-of-the-art models across various forecasting horizons. This work highlights the potential of combining multiscale analysis and LLMs for effective and scalable time-series forecasting.
Parameter-Efficient Fine-Tuning of Large Language Models using Semantic Knowledge Tuning
Oct 11, 2024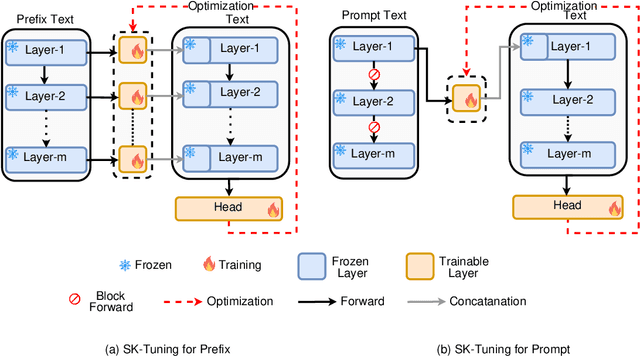
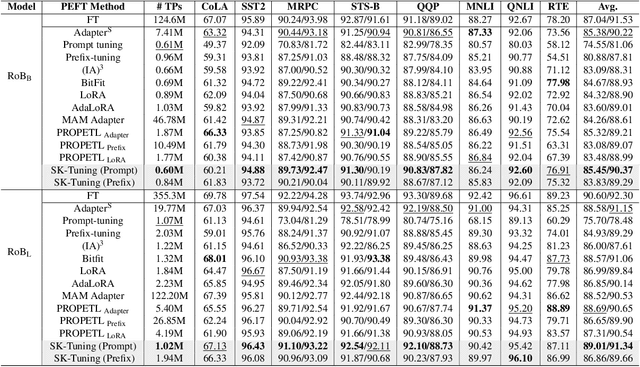
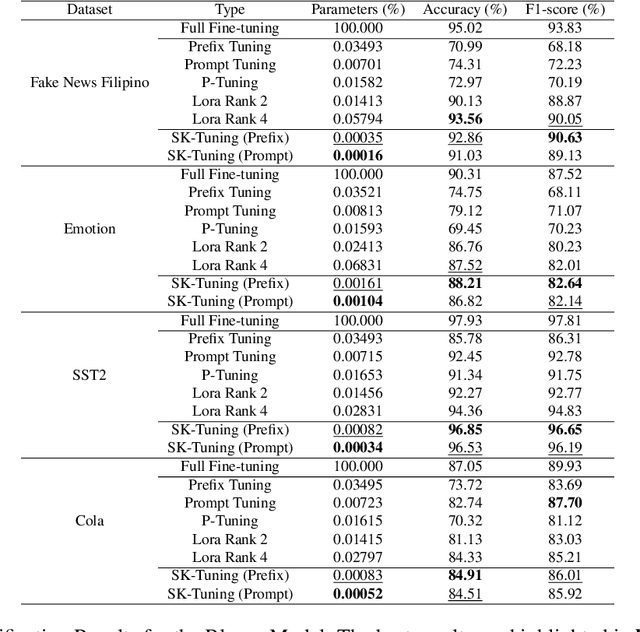
Large Language Models (LLMs) are gaining significant popularity in recent years for specialized tasks using prompts due to their low computational cost. Standard methods like prefix tuning utilize special, modifiable tokens that lack semantic meaning and require extensive training for best performance, often falling short. In this context, we propose a novel method called Semantic Knowledge Tuning (SK-Tuning) for prompt and prefix tuning that employs meaningful words instead of random tokens. This method involves using a fixed LLM to understand and process the semantic content of the prompt through zero-shot capabilities. Following this, it integrates the processed prompt with the input text to improve the model's performance on particular tasks. Our experimental results show that SK-Tuning exhibits faster training times, fewer parameters, and superior performance on tasks such as text classification and understanding compared to other tuning methods. This approach offers a promising method for optimizing the efficiency and effectiveness of LLMs in processing language tasks.
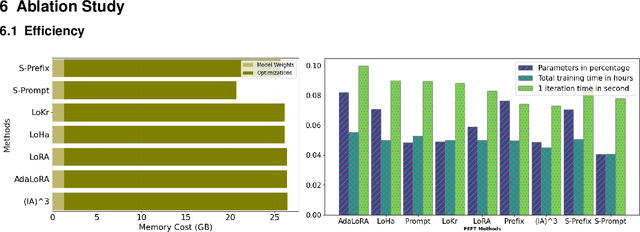
Propulsion: Steering LLM with Tiny Fine-Tuning
Sep 18, 2024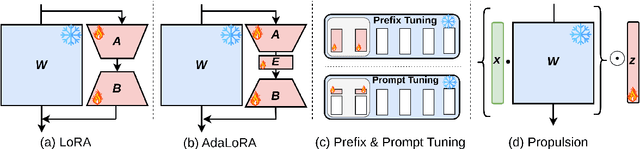
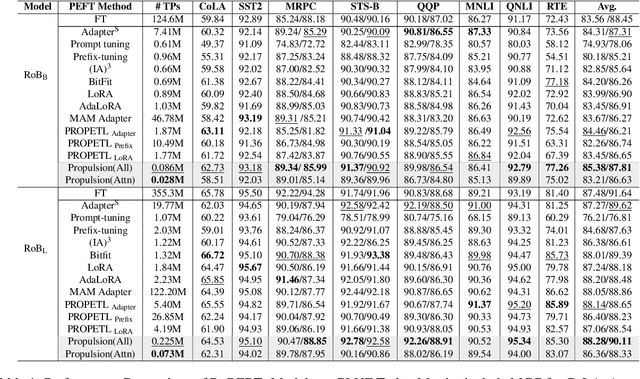
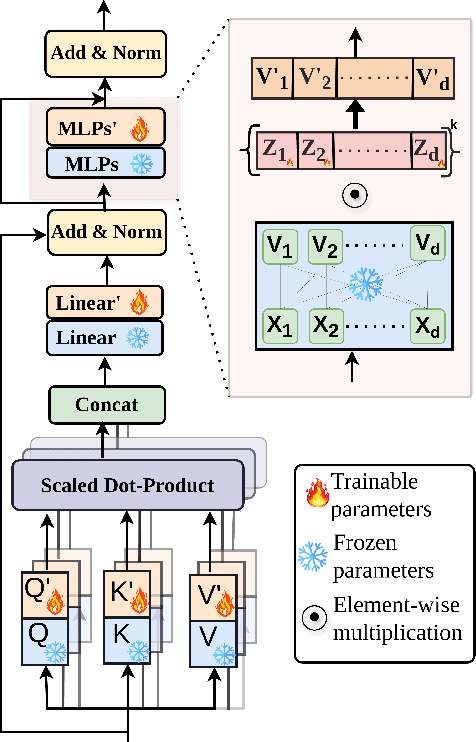
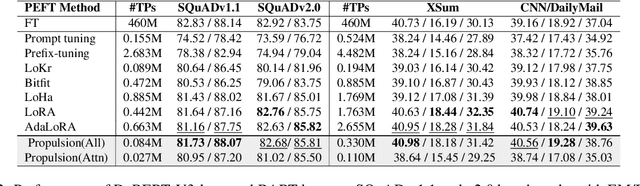
The rapid advancements in Large Language Models (LLMs) have revolutionized natural language processing (NLP) and related fields. However, fine-tuning these models for specific tasks remains computationally expensive and risks degrading pre-learned features. To address these challenges, we propose Propulsion, a novel parameter efficient fine-tuning (PEFT) method designed to optimize task-specific performance while drastically reducing computational overhead. Inspired by the concept of controlled adjustments in physical motion, Propulsion selectively re-scales specific dimensions of a pre-trained model, guiding output predictions toward task objectives without modifying the model's parameters. By introducing lightweight, trainable Propulsion parameters at the pre-trained layer, we minimize the number of parameters updated during fine-tuning, preventing overfitting or overwriting of existing knowledge. Our theoretical analysis, supported by Neural Tangent Kernel (NTK) theory, shows that Propulsion approximates the performance of full fine-tuning with far fewer trainable parameters. Empirically, Propulsion reduces the parameter count from 355.3 million to just 0.086 million, achieving over a 10x reduction compared to standard approaches like LoRA while maintaining competitive performance across benchmarks.