 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonkey Jump : MoE-Style PEFT for Efficient Multi-Task Learning
Jan 09, 2026Mixture-of-experts variants of parameter-efficient fine-tuning enable per-token specialization, but they introduce additional trainable routers and expert parameters, increasing memory usage and training cost. This undermines the core goal of parameter-efficient fine-tuning. We propose Monkey Jump, a method that brings mixture-of-experts-style specialization to parameter-efficient fine-tuning without introducing extra trainable parameters for experts or routers. Instead of adding new adapters as experts, Monkey Jump treats the adapters already present in each Transformer block (such as query, key, value, up, and down projections) as implicit experts and routes tokens among them. Routing is performed using k-means clustering with exponentially moving averaged cluster centers, requiring no gradients and no learned parameters. We theoretically show that token-wise routing increases expressivity and can outperform shared adapters by avoiding cancellation effects. Across multi-task experiments covering 14 text, 14 image, and 19 video benchmarks, Monkey Jump achieves competitive performance with mixture-of-experts-based parameter-efficient fine-tuning methods while using 7 to 29 times fewer trainable parameters, up to 48 percent lower memory consumption, and 1.5 to 2 times faster training. Monkey Jump is architecture-agnostic and can be applied to any adapter-based parameter-efficient fine-tuning method.
Predicting Through Generation: Why Generation Is Better for Prediction
Feb 25, 2025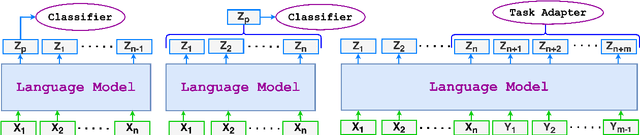
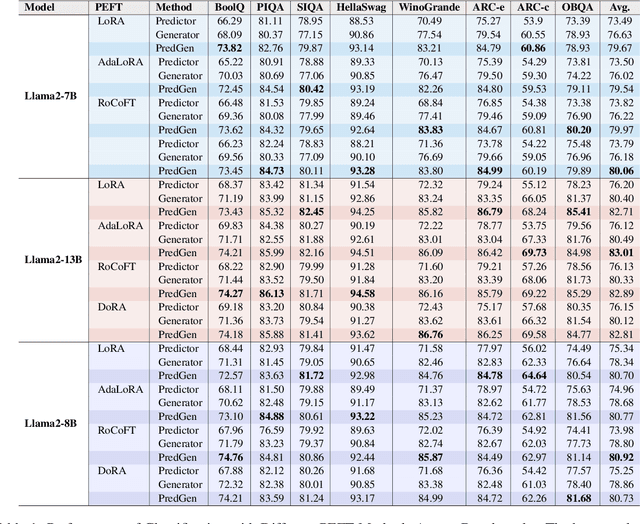
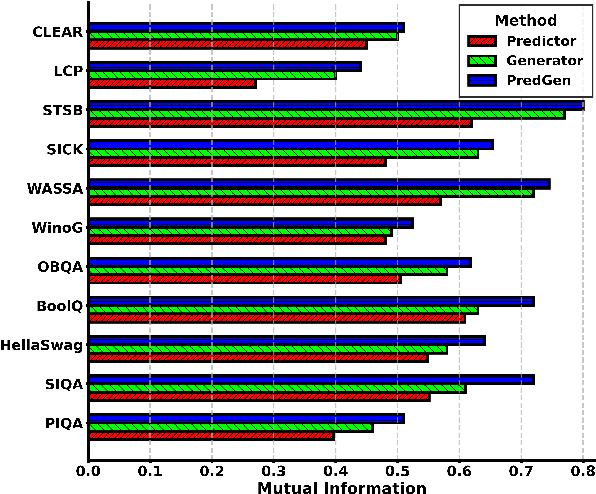
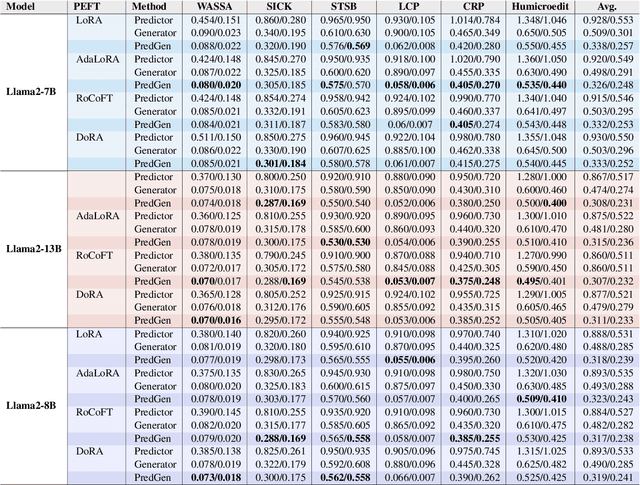
This paper argues that generating output tokens is more effective than using pooled representations for prediction tasks because token-level generation retains more mutual information. Since LLMs are trained on massive text corpora using next-token prediction, generation aligns naturally with their learned behavior. Using the Data Processing Inequality (DPI), we provide both theoretical and empirical evidence supporting this claim. However, autoregressive models face two key challenges when used for prediction: (1) exposure bias, where the model sees ground truth tokens during training but relies on its own predictions during inference, leading to errors, and (2) format mismatch, where discrete tokens do not always align with the tasks required output structure. To address these challenges, we introduce PredGen(Predicting Through Generating), an end to end framework that (i) uses scheduled sampling to reduce exposure bias, and (ii) introduces a task adapter to convert the generated tokens into structured outputs. Additionally, we introduce Writer-Director Alignment Loss (WDAL), which ensures consistency between token generation and final task predictions, improving both text coherence and numerical accuracy. We evaluate PredGen on multiple classification and regression benchmarks. Our results show that PredGen consistently outperforms standard baselines, demonstrating its effectiveness in structured prediction tasks.
Does Self-Attention Need Separate Weights in Transformers?
Nov 30, 2024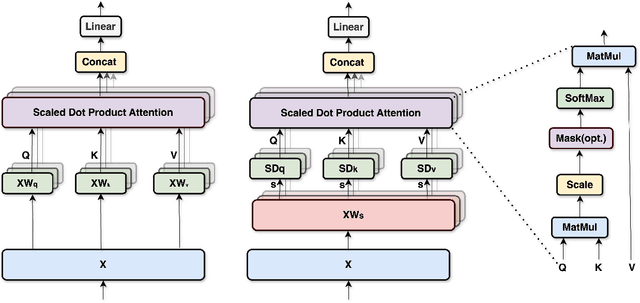

The success of self-attention lies in its ability to capture long-range dependencies and enhance context understanding, but it is limited by its computational complexity and challenges in handling sequential data with inherent directionality. This work introduces a shared weight self-attention-based BERT model that only learns one weight matrix for (Key, Value, and Query) representations instead of three individual matrices for each of them. Our shared weight attention reduces the training parameter size by more than half and training time by around one-tenth. Furthermore, we demonstrate higher prediction accuracy on small tasks of GLUE over the BERT baseline and in particular a generalization power on noisy and out-of-domain data. Experimental results indicate that our shared self-attention method achieves a parameter size reduction of 66.53% in the attention block. In the GLUE dataset, the shared weight self-attention-based BERT model demonstrates accuracy improvements of 0.38%, 5.81%, and 1.06% over the standard, symmetric, and pairwise attention-based BERT models, respectively. The model and source code are available at Anonymous.
RoCoFT: Efficient Finetuning of Large Language Models with Row-Column Updates
Oct 15, 2024



We propose RoCoFT, a parameter-efficient fine-tuning method for large-scale language models (LMs) based on updating only a few rows and columns of the weight matrices in transformers. Through extensive experiments with medium-size LMs like BERT and RoBERTa, and larger LMs like Bloom-7B, Llama2-7B, and Llama2-13B, we show that our method gives comparable or better accuracies than state-of-art PEFT methods while also being more memory and computation-efficient. We also study the reason behind the effectiveness of our method with tools from neural tangent kernel theory. We empirically demonstrate that our kernel, constructed using a restricted set of row and column parameters, are numerically close to the full-parameter kernel and gives comparable classification performance. Ablation studies are conducted to investigate the impact of different algorithmic choices, including the selection strategy for rows and columns as well as the optimal rank for effective implementation of our method.
A Study on Representation Transfer for Few-Shot Learning
Sep 05, 2022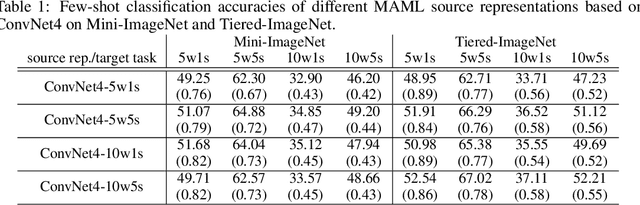
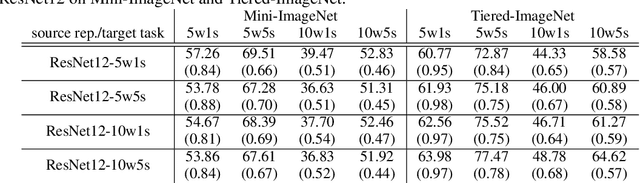
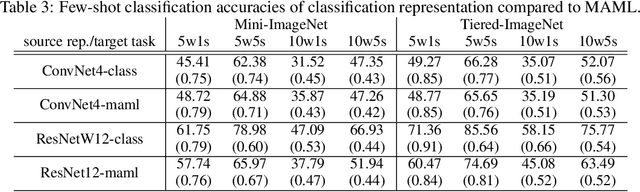
Few-shot classification aims to learn to classify new object categories well using only a few labeled examples. Transferring feature representations from other models is a popular approach for solving few-shot classification problems. In this work we perform a systematic study of various feature representations for few-shot classification, including representations learned from MAML, supervised classification, and several common self-supervised tasks. We find that learning from more complex tasks tend to give better representations for few-shot classification, and thus we propose the use of representations learned from multiple tasks for few-shot classification. Coupled with new tricks on feature selection and voting to handle the issue of small sample size, our direct transfer learning method offers performance comparable to state-of-art on several benchmark datasets.
A Direct Approach to Robust Deep Learning Using Adversarial Networks
May 23, 2019


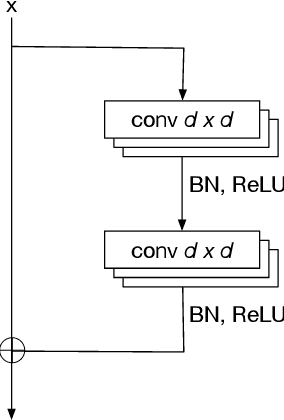
Deep neural networks have been shown to perform well in many classical machine learning problems, especially in image classification tasks. However, researchers have found that neural networks can be easily fooled, and they are surprisingly sensitive to small perturbations imperceptible to humans. Carefully crafted input images (adversarial examples) can force a well-trained neural network to provide arbitrary outputs. Including adversarial examples during training is a popular defense mechanism against adversarial attacks. In this paper we propose a new defensive mechanism under the generative adversarial network (GAN) framework. We model the adversarial noise using a generative network, trained jointly with a classification discriminative network as a minimax game. We show empirically that our adversarial network approach works well against black box attacks, with performance on par with state-of-art methods such as ensemble adversarial training and adversarial training with projected gradient descent.
* 15 pages
A Generalized Loop Correction Method for Approximate Inference in Graphical Models
Jun 18, 2012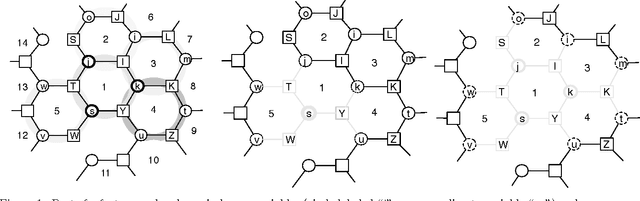

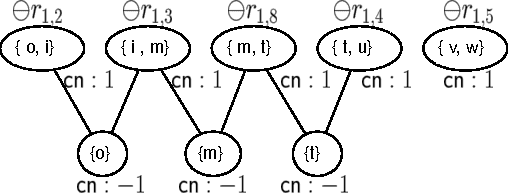
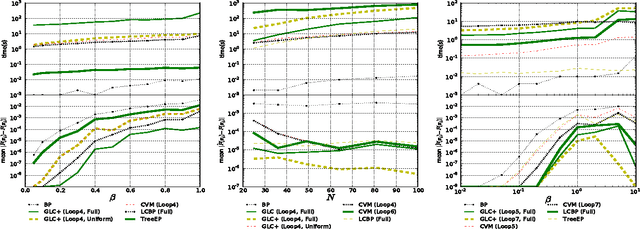
Belief Propagation (BP) is one of the most popular methods for inference in probabilistic graphical models. BP is guaranteed to return the correct answer for tree structures, but can be incorrect or non-convergent for loopy graphical models. Recently, several new approximate inference algorithms based on cavity distribution have been proposed. These methods can account for the effect of loops by incorporating the dependency between BP messages. Alternatively, region-based approximations (that lead to methods such as Generalized Belief Propagation) improve upon BP by considering interactions within small clusters of variables, thus taking small loops within these clusters into account. This paper introduces an approach, Generalized Loop Correction (GLC), that benefits from both of these types of loop correction. We show how GLC relates to these two families of inference methods, then provide empirical evidence that GLC works effectively in general, and can be significantly more accurate than both correction schemes.