 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Stable Predictors from Weak Supervision under Distribution Shift
Apr 05, 2026Learning from weak or proxy supervision is common when ground-truth labels are unavailable, yet robustness under distribution shift remains poorly understood, especially when the supervision mechanism itself changes. We formalize this as supervision drift, defined as changes in P(y | x, c) across contexts, and study it in CRISPR-Cas13d experiments where guide efficacy is inferred indirectly from RNA-seq responses. Using data from two human cell lines and multiple time points, we build a controlled non-IID benchmark with explicit domain and temporal shifts while keeping the weak-label construction fixed. Models achieve strong in-domain performance (ridge R^2 = 0.356, Spearman rho = 0.442) and partial cross-cell-line transfer (rho ~ 0.40). However, temporal transfer fails across all models, with negative R^2 and near-zero correlation (e.g., XGBoost R^2 = -0.155, rho = 0.056). Additional analyses confirm this pattern. Feature-label relationships remain stable across cell lines but change sharply over time, indicating that failures arise from supervision drift rather than model limitations. These findings highlight feature stability as a simple diagnostic for detecting non-transferability before deployment.
UAT-LITE: Inference-Time Uncertainty-Aware Attention for Pretrained Transformers
Feb 03, 2026Neural NLP models are often miscalibrated, assigning high confidence to incorrect predictions, which undermines selective prediction and high-stakes deployment. Post-hoc calibration methods adjust output probabilities but leave internal computation unchanged, while ensemble and Bayesian approaches improve uncertainty at substantial training or storage cost. We propose UAT-LITE, an inference-time framework that makes self-attention uncertainty-aware using approximate Bayesian inference via Monte Carlo dropout in pretrained transformer classifiers. Token-level epistemic uncertainty is estimated from stochastic forward passes and used to modulate self-attention during contextualization, without modifying pretrained weights or training objectives. We additionally introduce a layerwise variance decomposition to diagnose how predictive uncertainty accumulates across transformer depth. Across the SQuAD 2.0 answerability, MNLI, and SST-2, UAT-LITE reduces Expected Calibration Error by approximately 20% on average relative to a fine-tuned BERT-base baseline while preserving task accuracy, and improves selective prediction and robustness under distribution shift.
Explainable Detection of Implicit Influential Patterns in Conversations via Data Augmentation
Jun 17, 2025In the era of digitalization, as individuals increasingly rely on digital platforms for communication and news consumption, various actors employ linguistic strategies to influence public perception. While models have become proficient at detecting explicit patterns, which typically appear in texts as single remarks referred to as utterances, such as social media posts, malicious actors have shifted toward utilizing implicit influential verbal patterns embedded within conversations. These verbal patterns aim to mentally penetrate the victim's mind in order to influence them, enabling the actor to obtain the desired information through implicit means. This paper presents an improved approach for detecting such implicit influential patterns. Furthermore, the proposed model is capable of identifying the specific locations of these influential elements within a conversation. To achieve this, the existing dataset was augmented using the reasoning capabilities of state-of-the-art language models. Our designed framework resulted in a 6% improvement in the detection of implicit influential patterns in conversations. Moreover, this approach improved the multi-label classification tasks related to both the techniques used for influence and the vulnerability of victims by 33% and 43%, respectively.
Predicting Through Generation: Why Generation Is Better for Prediction
Feb 25, 2025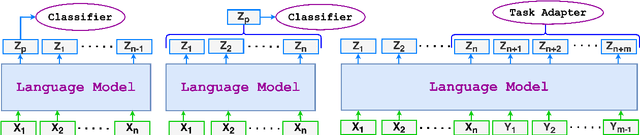
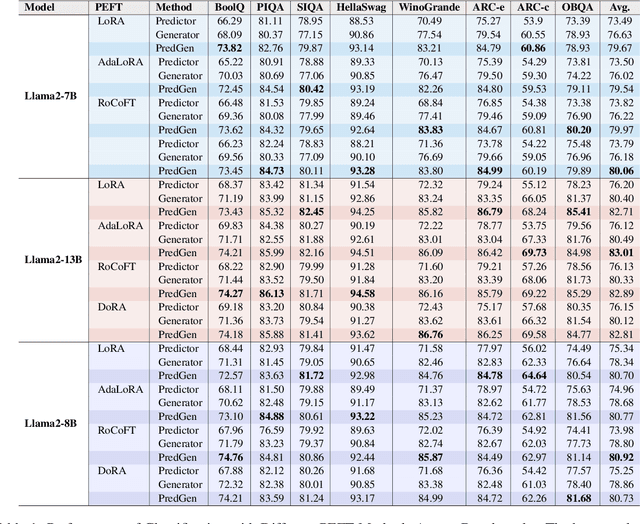
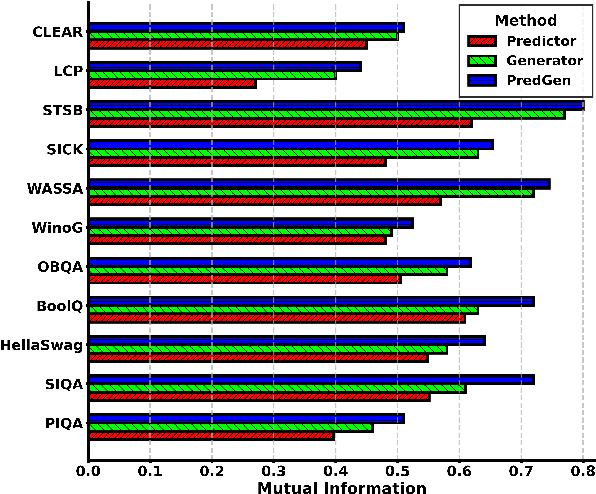
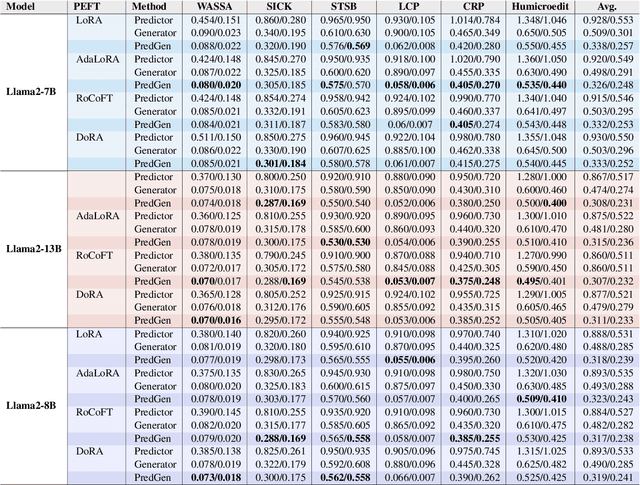
This paper argues that generating output tokens is more effective than using pooled representations for prediction tasks because token-level generation retains more mutual information. Since LLMs are trained on massive text corpora using next-token prediction, generation aligns naturally with their learned behavior. Using the Data Processing Inequality (DPI), we provide both theoretical and empirical evidence supporting this claim. However, autoregressive models face two key challenges when used for prediction: (1) exposure bias, where the model sees ground truth tokens during training but relies on its own predictions during inference, leading to errors, and (2) format mismatch, where discrete tokens do not always align with the tasks required output structure. To address these challenges, we introduce PredGen(Predicting Through Generating), an end to end framework that (i) uses scheduled sampling to reduce exposure bias, and (ii) introduces a task adapter to convert the generated tokens into structured outputs. Additionally, we introduce Writer-Director Alignment Loss (WDAL), which ensures consistency between token generation and final task predictions, improving both text coherence and numerical accuracy. We evaluate PredGen on multiple classification and regression benchmarks. Our results show that PredGen consistently outperforms standard baselines, demonstrating its effectiveness in structured prediction tasks.
Fair Bilevel Neural Network (FairBiNN): On Balancing fairness and accuracy via Stackelberg Equilibrium
Oct 21, 2024



The persistent challenge of bias in machine learning models necessitates robust solutions to ensure parity and equal treatment across diverse groups, particularly in classification tasks. Current methods for mitigating bias often result in information loss and an inadequate balance between accuracy and fairness. To address this, we propose a novel methodology grounded in bilevel optimization principles. Our deep learning-based approach concurrently optimizes for both accuracy and fairness objectives, and under certain assumptions, achieving proven Pareto optimal solutions while mitigating bias in the trained model. Theoretical analysis indicates that the upper bound on the loss incurred by this method is less than or equal to the loss of the Lagrangian approach, which involves adding a regularization term to the loss function. We demonstrate the efficacy of our model primarily on tabular datasets such as UCI Adult and Heritage Health. When benchmarked against state-of-the-art fairness methods, our model exhibits superior performance, advancing fairness-aware machine learning solutions and bridging the accuracy-fairness gap. The implementation of FairBiNN is available on https://github.com/yazdanimehdi/FairBiNN.
Dominant Set-based Active Learning for Text Classification and its Application to Online Social Media
Jan 28, 2022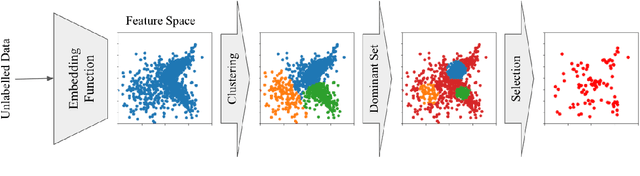



Recent advances in natural language processing (NLP) in online social media are evidently owed to large-scale datasets. However, labeling, storing, and processing a large number of textual data points, e.g., tweets, has remained challenging. On top of that, in applications such as hate speech detection, labeling a sufficiently large dataset containing offensive content can be mentally and emotionally taxing for human annotators. Thus, NLP methods that can make the best use of significantly less labeled data points are of great interest. In this paper, we present a novel pool-based active learning method that can be used for the training of large unlabeled corpus with minimum annotation cost. For that, we propose to find the dominant sets of local clusters in the feature space. These sets represent maximally cohesive structures in the data. Then, the samples that do not belong to any of the dominant sets are selected to be used to train the model, as they represent the boundaries of the local clusters and are more challenging to classify. Our proposed method does not have any parameters to be tuned, making it dataset-independent, and it can approximately achieve the same classification accuracy as full training data, with significantly fewer data points. Additionally, our method achieves a higher performance in comparison to the state-of-the-art active learning strategies. Furthermore, our proposed algorithm is able to incorporate conventional active learning scores, such as uncertainty-based scores, into its selection criteria. We show the effectiveness of our method on different datasets and using different neural network architectures.
Resilience from Diversity: Population-based approach to harden models against adversarial attacks
Nov 19, 2021

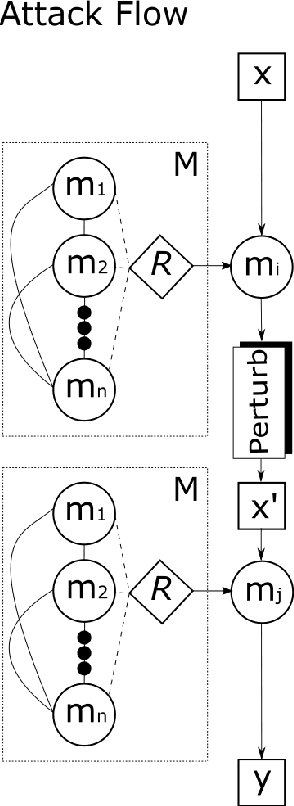

Traditional deep learning models exhibit intriguing vulnerabilities that allow an attacker to force them to fail at their task. Notorious attacks such as the Fast Gradient Sign Method (FGSM) and the more powerful Projected Gradient Descent (PGD) generate adversarial examples by adding a magnitude of perturbation $\epsilon$ to the input's computed gradient, resulting in a deterioration of the effectiveness of the model's classification. This work introduces a model that is resilient to adversarial attacks. Our model leverages a well established principle from biological sciences: population diversity produces resilience against environmental changes. More precisely, our model consists of a population of $n$ diverse submodels, each one of them trained to individually obtain a high accuracy for the task at hand, while forced to maintain meaningful differences in their weight tensors. Each time our model receives a classification query, it selects a submodel from its population at random to answer the query. To introduce and maintain diversity in population of submodels, we introduce the concept of counter linking weights. A Counter-Linked Model (CLM) consists of submodels of the same architecture where a periodic random similarity examination is conducted during the simultaneous training to guarantee diversity while maintaining accuracy. In our testing, CLM robustness got enhanced by around 20% when tested on the MNIST dataset and at least 15% when tested on the CIFAR-10 dataset. When implemented with adversarially trained submodels, this methodology achieves state-of-the-art robustness. On the MNIST dataset with $\epsilon=0.3$, it achieved 94.34% against FGSM and 91% against PGD. On the CIFAR-10 dataset with $\epsilon=8/255$, it achieved 62.97% against FGSM and 59.16% against PGD.
Ethical AI for Social Good
Jul 14, 2021

The concept of AI for Social Good(AI4SG) is gaining momentum in both information societies and the AI community. Through all the advancement of AI-based solutions, it can solve societal issues effectively. To date, however, there is only a rudimentary grasp of what constitutes AI socially beneficial in principle, what constitutes AI4SG in reality, and what are the policies and regulations needed to ensure it. This paper fills the vacuum by addressing the ethical aspects that are critical for future AI4SG efforts. Some of these characteristics are new to AI, while others have greater importance due to its usage.
Interpretable Multi-Head Self-Attention model for Sarcasm Detection in social media
Jan 14, 2021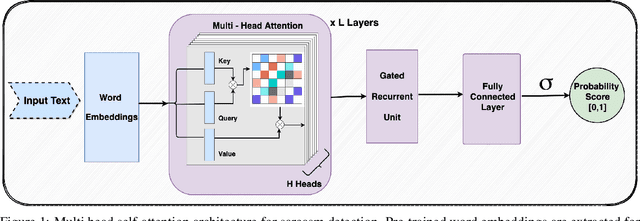

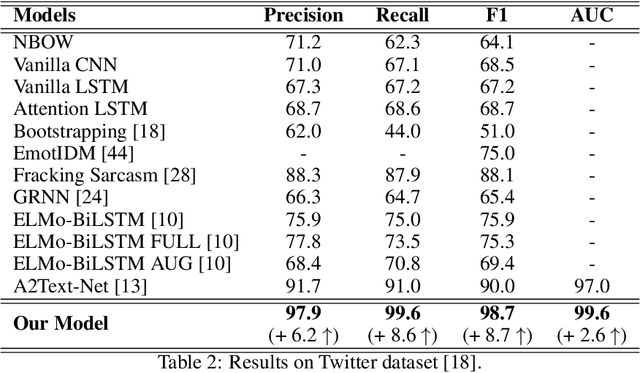
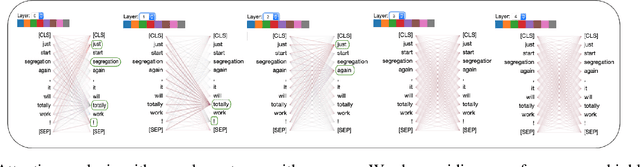
Sarcasm is a linguistic expression often used to communicate the opposite of what is said, usually something that is very unpleasant with an intention to insult or ridicule. Inherent ambiguity in sarcastic expressions, make sarcasm detection very difficult. In this work, we focus on detecting sarcasm in textual conversations from various social networking platforms and online media. To this end, we develop an interpretable deep learning model using multi-head self-attention and gated recurrent units. Multi-head self-attention module aids in identifying crucial sarcastic cue-words from the input, and the recurrent units learn long-range dependencies between these cue-words to better classify the input text. We show the effectiveness of our approach by achieving state-of-the-art results on multiple datasets from social networking platforms and online media. Models trained using our proposed approach are easily interpretable and enable identifying sarcastic cues in the input text which contribute to the final classification score. We visualize the learned attention weights on few sample input texts to showcase the effectiveness and interpretability of our model.
A Stance Data Set on Polarized Conversations on Twitter about the Efficacy of Hydroxychloroquine as a Treatment for COVID-19
Sep 05, 2020
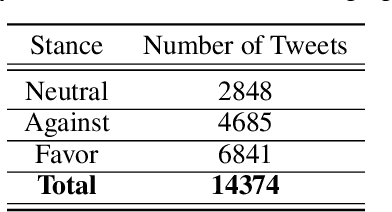

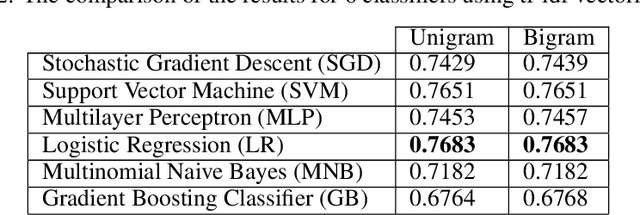
At the time of this study, the SARS-CoV-2 virus that caused the COVID-19 pandemic has spread significantly across the world. Considering the uncertainty about policies, health risks, financial difficulties, etc. the online media, specially the Twitter platform, is experiencing a high volume of activity related to this pandemic. Among the hot topics, the polarized debates about unconfirmed medicines for the treatment and prevention of the disease have attracted significant attention from online media users. In this work, we present a stance data set, COVID-CQ, of user-generated content on Twitter in the context of COVID-19. We investigated more than 14 thousand tweets and manually annotated the opinions of the tweet initiators regarding the use of "chloroquine" and "hydroxychloroquine" for the treatment or prevention of COVID-19. To the best of our knowledge, COVID-CQ is the first data set of Twitter users' stances in the context of the COVID-19 pandemic, and the largest Twitter data set on users' stances towards a claim, in any domain. We have made this data set available to the research community via GitHub. We expect this data set to be useful for many research purposes, including stance detection, evolution and dynamics of opinions regarding this outbreak, and changes in opinions in response to the exogenous shocks such as policy decisions and events.