 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThrough a fair looking-glass: mitigating bias in image datasets
Sep 18, 2022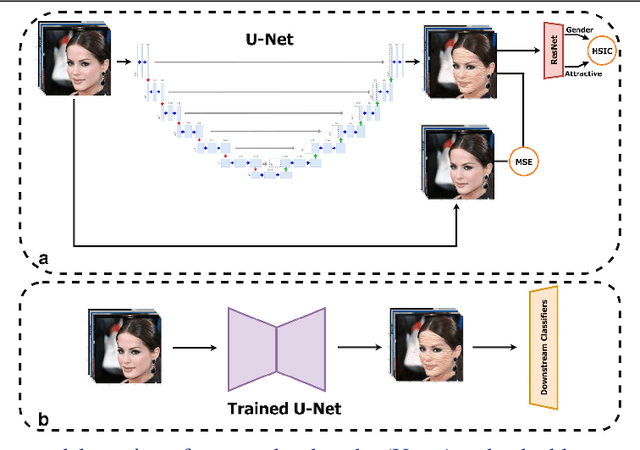



With the recent growth in computer vision applications, the question of how fair and unbiased they are has yet to be explored. There is abundant evidence that the bias present in training data is reflected in the models, or even amplified. Many previous methods for image dataset de-biasing, including models based on augmenting datasets, are computationally expensive to implement. In this study, we present a fast and effective model to de-bias an image dataset through reconstruction and minimizing the statistical dependence between intended variables. Our architecture includes a U-net to reconstruct images, combined with a pre-trained classifier which penalizes the statistical dependence between target attribute and the protected attribute. We evaluate our proposed model on CelebA dataset, compare the results with a state-of-the-art de-biasing method, and show that the model achieves a promising fairness-accuracy combination.
TabFairGAN: Fair Tabular Data Generation with Generative Adversarial Networks
Sep 02, 2021

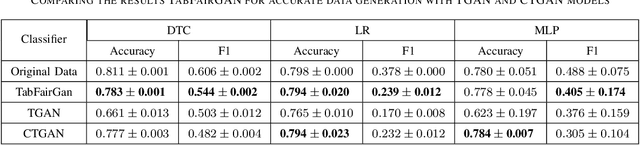

With the increasing reliance on automated decision making, the issue of algorithmic fairness has gained increasing importance. In this paper, we propose a Generative Adversarial Network for tabular data generation. The model includes two phases of training. In the first phase, the model is trained to accurately generate synthetic data similar to the reference dataset. In the second phase we modify the value function to add fairness constraint, and continue training the network to generate data that is both accurate and fair. We test our results in both cases of unconstrained, and constrained fair data generation. In the unconstrained case, i.e. when the model is only trained in the first phase and is only meant to generate accurate data following the same joint probability distribution of the real data, the results show that the model beats state-of-the-art GANs proposed in the literature to produce synthetic tabular data. Also, in the constrained case in which the first phase of training is followed by the second phase, we train the network and test it on four datasets studied in the fairness literature and compare our results with another state-of-the-art pre-processing method, and present the promising results that it achieves. Comparing to other studies utilizing GANs for fair data generation, our model is comparably more stable by using only one critic, and also by avoiding major problems of original GAN model, such as mode-dropping and non-convergence, by implementing a Wasserstein GAN.
A Stance Data Set on Polarized Conversations on Twitter about the Efficacy of Hydroxychloroquine as a Treatment for COVID-19
Sep 05, 2020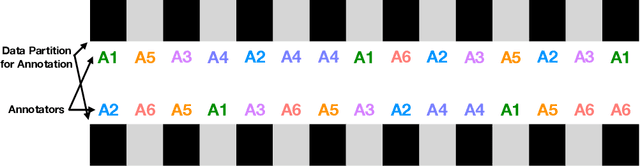
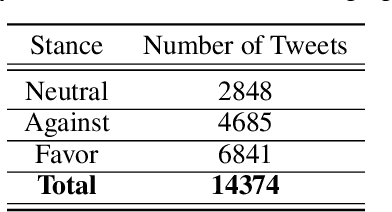

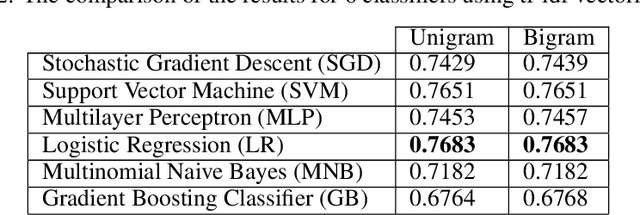
At the time of this study, the SARS-CoV-2 virus that caused the COVID-19 pandemic has spread significantly across the world. Considering the uncertainty about policies, health risks, financial difficulties, etc. the online media, specially the Twitter platform, is experiencing a high volume of activity related to this pandemic. Among the hot topics, the polarized debates about unconfirmed medicines for the treatment and prevention of the disease have attracted significant attention from online media users. In this work, we present a stance data set, COVID-CQ, of user-generated content on Twitter in the context of COVID-19. We investigated more than 14 thousand tweets and manually annotated the opinions of the tweet initiators regarding the use of "chloroquine" and "hydroxychloroquine" for the treatment or prevention of COVID-19. To the best of our knowledge, COVID-CQ is the first data set of Twitter users' stances in the context of the COVID-19 pandemic, and the largest Twitter data set on users' stances towards a claim, in any domain. We have made this data set available to the research community via GitHub. We expect this data set to be useful for many research purposes, including stance detection, evolution and dynamics of opinions regarding this outbreak, and changes in opinions in response to the exogenous shocks such as policy decisions and events.