 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabFairGAN: Fair Tabular Data Generation with Generative Adversarial Networks
Paper and Code
Sep 02, 2021

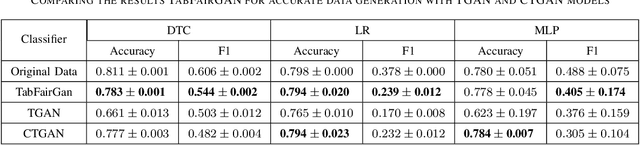

With the increasing reliance on automated decision making, the issue of algorithmic fairness has gained increasing importance. In this paper, we propose a Generative Adversarial Network for tabular data generation. The model includes two phases of training. In the first phase, the model is trained to accurately generate synthetic data similar to the reference dataset. In the second phase we modify the value function to add fairness constraint, and continue training the network to generate data that is both accurate and fair. We test our results in both cases of unconstrained, and constrained fair data generation. In the unconstrained case, i.e. when the model is only trained in the first phase and is only meant to generate accurate data following the same joint probability distribution of the real data, the results show that the model beats state-of-the-art GANs proposed in the literature to produce synthetic tabular data. Also, in the constrained case in which the first phase of training is followed by the second phase, we train the network and test it on four datasets studied in the fairness literature and compare our results with another state-of-the-art pre-processing method, and present the promising results that it achieves. Comparing to other studies utilizing GANs for fair data generation, our model is comparably more stable by using only one critic, and also by avoiding major problems of original GAN model, such as mode-dropping and non-convergence, by implementing a Wasserstein GAN.