 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairContrast: Enhancing Fairness through Contrastive learning and Customized Augmenting Methods on Tabular Data
Oct 02, 2025As AI systems become more embedded in everyday life, the development of fair and unbiased models becomes more critical. Considering the social impact of AI systems is not merely a technical challenge but a moral imperative. As evidenced in numerous research studies, learning fair and robust representations has proven to be a powerful approach to effectively debiasing algorithms and improving fairness while maintaining essential information for prediction tasks. Representation learning frameworks, particularly those that utilize self-supervised and contrastive learning, have demonstrated superior robustness and generalizability across various domains. Despite the growing interest in applying these approaches to tabular data, the issue of fairness in these learned representations remains underexplored. In this study, we introduce a contrastive learning framework specifically designed to address bias and learn fair representations in tabular datasets. By strategically selecting positive pair samples and employing supervised and self-supervised contrastive learning, we significantly reduce bias compared to existing state-of-the-art contrastive learning models for tabular data. Our results demonstrate the efficacy of our approach in mitigating bias with minimum trade-off in accuracy and leveraging the learned fair representations in various downstream tasks.
Fair Bilevel Neural Network (FairBiNN): On Balancing fairness and accuracy via Stackelberg Equilibrium
Oct 21, 2024



The persistent challenge of bias in machine learning models necessitates robust solutions to ensure parity and equal treatment across diverse groups, particularly in classification tasks. Current methods for mitigating bias often result in information loss and an inadequate balance between accuracy and fairness. To address this, we propose a novel methodology grounded in bilevel optimization principles. Our deep learning-based approach concurrently optimizes for both accuracy and fairness objectives, and under certain assumptions, achieving proven Pareto optimal solutions while mitigating bias in the trained model. Theoretical analysis indicates that the upper bound on the loss incurred by this method is less than or equal to the loss of the Lagrangian approach, which involves adding a regularization term to the loss function. We demonstrate the efficacy of our model primarily on tabular datasets such as UCI Adult and Heritage Health. When benchmarked against state-of-the-art fairness methods, our model exhibits superior performance, advancing fairness-aware machine learning solutions and bridging the accuracy-fairness gap. The implementation of FairBiNN is available on https://github.com/yazdanimehdi/FairBiNN.
FragXsiteDTI: Revealing Responsible Segments in Drug-Target Interaction with Transformer-Driven Interpretation
Nov 04, 2023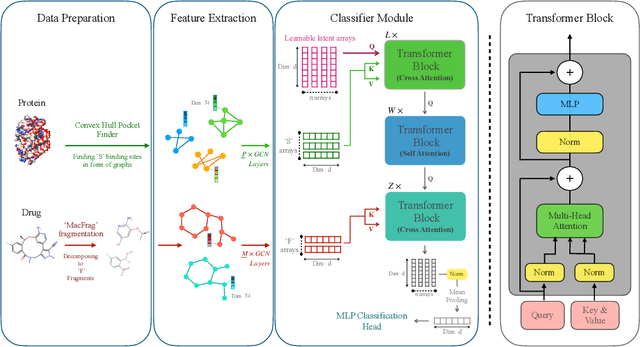
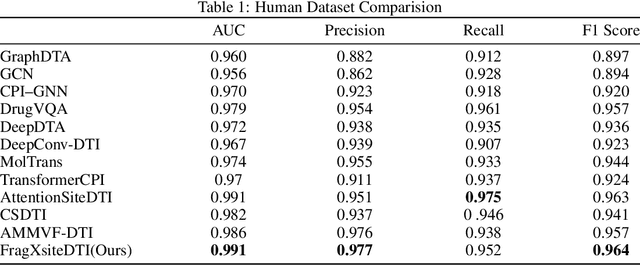
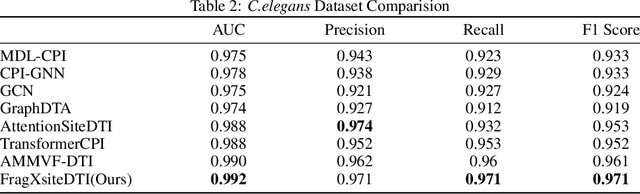
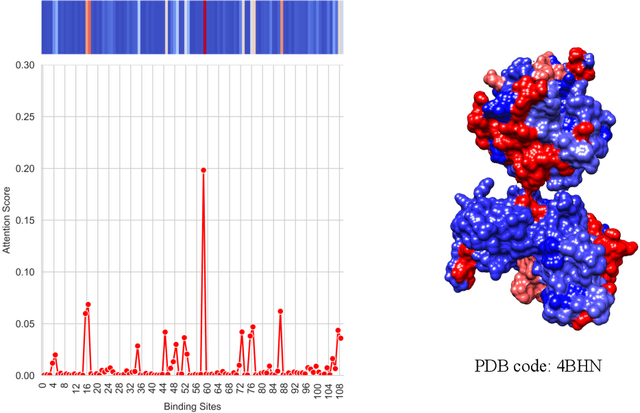
Drug-Target Interaction (DTI) prediction is vital for drug discovery, yet challenges persist in achieving model interpretability and optimizing performance. We propose a novel transformer-based model, FragXsiteDTI, that aims to address these challenges in DTI prediction. Notably, FragXsiteDTI is the first DTI model to simultaneously leverage drug molecule fragments and protein pockets. Our information-rich representations for both proteins and drugs offer a detailed perspective on their interaction. Inspired by the Perceiver IO framework, our model features a learnable latent array, initially interacting with protein binding site embeddings using cross-attention and later refined through self-attention and used as a query to the drug fragments in the drug's cross-attention transformer block. This learnable query array serves as a mediator and enables seamless information translation, preserving critical nuances in drug-protein interactions. Our computational results on three benchmarking datasets demonstrate the superior predictive power of our model over several state-of-the-art models. We also show the interpretability of our model in terms of the critical components of both target proteins and drug molecules within drug-target pairs.
Distraction is All You Need for Fairness
Mar 15, 2022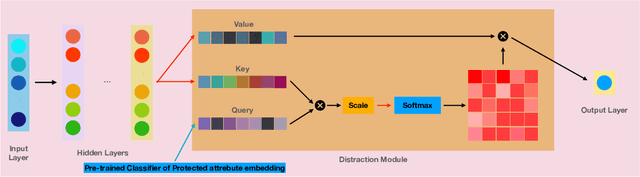
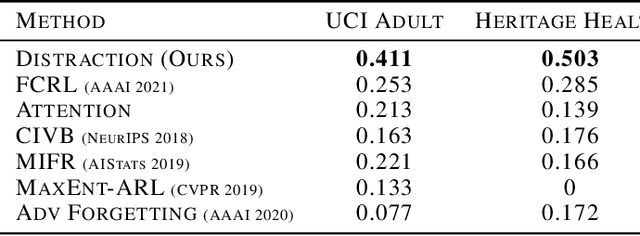
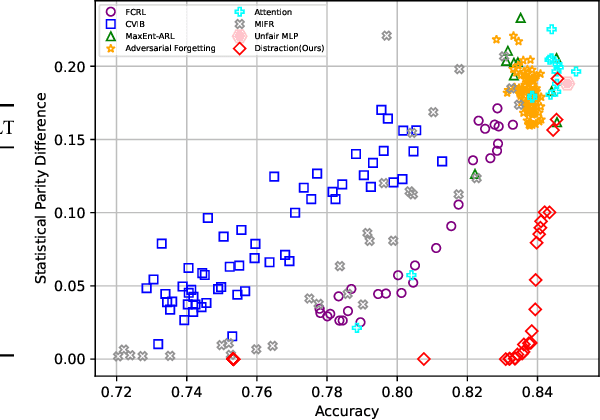
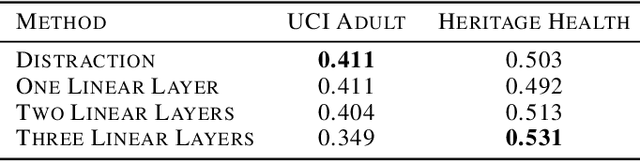
With the recent growth in artificial intelligence models and its expanding role in automated decision making, ensuring that these models are not biased is of vital importance. There is an abundance of evidence suggesting that these models could contain or even amplify the bias present in the data on which they are trained, inherent to their objective function and learning algorithms. In this paper, we propose a novel classification algorithm that improves fairness, while maintaining accuracy of the predictions. Utilizing the embedding layer of a pre-trained classifier for the protected attributes, the network uses an attention layer to distract the classification from depending on the protected attribute in its predictions. We compare our model with six state-of-the-art methodologies proposed in fairness literature, and show that the model is superior to those methods in terms of minimizing bias while maintaining accuracy.
A Stance Data Set on Polarized Conversations on Twitter about the Efficacy of Hydroxychloroquine as a Treatment for COVID-19
Sep 05, 2020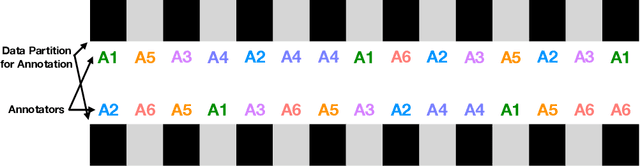
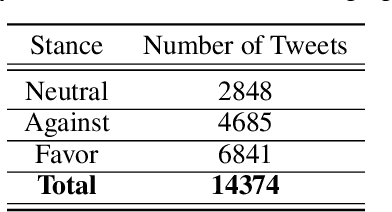

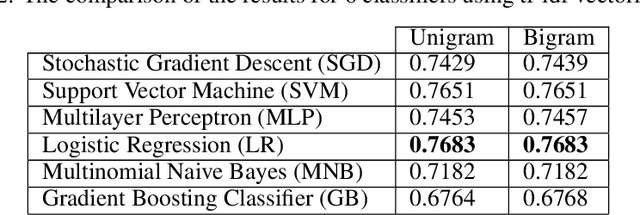
At the time of this study, the SARS-CoV-2 virus that caused the COVID-19 pandemic has spread significantly across the world. Considering the uncertainty about policies, health risks, financial difficulties, etc. the online media, specially the Twitter platform, is experiencing a high volume of activity related to this pandemic. Among the hot topics, the polarized debates about unconfirmed medicines for the treatment and prevention of the disease have attracted significant attention from online media users. In this work, we present a stance data set, COVID-CQ, of user-generated content on Twitter in the context of COVID-19. We investigated more than 14 thousand tweets and manually annotated the opinions of the tweet initiators regarding the use of "chloroquine" and "hydroxychloroquine" for the treatment or prevention of COVID-19. To the best of our knowledge, COVID-CQ is the first data set of Twitter users' stances in the context of the COVID-19 pandemic, and the largest Twitter data set on users' stances towards a claim, in any domain. We have made this data set available to the research community via GitHub. We expect this data set to be useful for many research purposes, including stance detection, evolution and dynamics of opinions regarding this outbreak, and changes in opinions in response to the exogenous shocks such as policy decisions and events.