 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Stable Predictors from Weak Supervision under Distribution Shift
Apr 05, 2026Learning from weak or proxy supervision is common when ground-truth labels are unavailable, yet robustness under distribution shift remains poorly understood, especially when the supervision mechanism itself changes. We formalize this as supervision drift, defined as changes in P(y | x, c) across contexts, and study it in CRISPR-Cas13d experiments where guide efficacy is inferred indirectly from RNA-seq responses. Using data from two human cell lines and multiple time points, we build a controlled non-IID benchmark with explicit domain and temporal shifts while keeping the weak-label construction fixed. Models achieve strong in-domain performance (ridge R^2 = 0.356, Spearman rho = 0.442) and partial cross-cell-line transfer (rho ~ 0.40). However, temporal transfer fails across all models, with negative R^2 and near-zero correlation (e.g., XGBoost R^2 = -0.155, rho = 0.056). Additional analyses confirm this pattern. Feature-label relationships remain stable across cell lines but change sharply over time, indicating that failures arise from supervision drift rather than model limitations. These findings highlight feature stability as a simple diagnostic for detecting non-transferability before deployment.
Hybrid Diffusion Model for Breast Ultrasound Image Augmentation
Mar 27, 2026We propose a hybrid diffusion-based augmentation framework to overcome the critical challenge of ultrasound data augmentation in breast ultrasound (BUS) datasets. Unlike conventional diffusion-based augmentations, our approach improves visual fidelity and preserves ultrasound texture by combining text-to-image generation with image-to-image (img2img) refinement, as well as fine-tuning with low-rank adaptation (LoRA) and textual inversion (TI). Our method generated realistic, class-consistent images on an open-source Kaggle breast ultrasound image dataset (BUSI). Compared to the Stable Diffusion v1.5 baseline, incorporating TI and img2img refinement reduced the Frechet Inception Distance (FID) from 45.97 to 33.29, demonstrating a substantial gain in fidelity while maintaining comparable downstream classification performance. Overall, the proposed framework effectively mitigates the low-fidelity limitations of synthetic ultrasound images and enhances the quality of augmentation for robust diagnostic modeling.
Validating Interpretability in siRNA Efficacy Prediction: A Perturbation-Based, Dataset-Aware Protocol
Feb 09, 2026Saliency maps are increasingly used as \emph{design guidance} in siRNA efficacy prediction, yet attribution methods are rarely validated before motivating sequence edits. We introduce a \textbf{pre-synthesis gate}: a protocol for \emph{counterfactual sensitivity faithfulness} that tests whether mutating high-saliency positions changes model output more than composition-matched controls. Cross-dataset transfer reveals two failure modes that would otherwise go undetected: \emph{faithful-but-wrong} (saliency valid, predictions fail) and \emph{inverted saliency} (top-saliency edits less impactful than random). Strikingly, models trained on mRNA-level assays collapse on a luciferase reporter dataset, demonstrating that protocol shifts can silently invalidate deployment. Across four benchmarks, 19/20 fold instances pass; the single failure shows inverted saliency. A biology-informed regularizer (BioPrior) strengthens saliency faithfulness with modest, dataset-dependent predictive trade-offs. Our results establish saliency validation as essential pre-deployment practice for explanation-guided therapeutic design. Code is available at https://github.com/shadi97kh/BioPrior.
UAT-LITE: Inference-Time Uncertainty-Aware Attention for Pretrained Transformers
Feb 03, 2026Neural NLP models are often miscalibrated, assigning high confidence to incorrect predictions, which undermines selective prediction and high-stakes deployment. Post-hoc calibration methods adjust output probabilities but leave internal computation unchanged, while ensemble and Bayesian approaches improve uncertainty at substantial training or storage cost. We propose UAT-LITE, an inference-time framework that makes self-attention uncertainty-aware using approximate Bayesian inference via Monte Carlo dropout in pretrained transformer classifiers. Token-level epistemic uncertainty is estimated from stochastic forward passes and used to modulate self-attention during contextualization, without modifying pretrained weights or training objectives. We additionally introduce a layerwise variance decomposition to diagnose how predictive uncertainty accumulates across transformer depth. Across the SQuAD 2.0 answerability, MNLI, and SST-2, UAT-LITE reduces Expected Calibration Error by approximately 20% on average relative to a fine-tuned BERT-base baseline while preserving task accuracy, and improves selective prediction and robustness under distribution shift.
Explainable Detection of Implicit Influential Patterns in Conversations via Data Augmentation
Jun 17, 2025In the era of digitalization, as individuals increasingly rely on digital platforms for communication and news consumption, various actors employ linguistic strategies to influence public perception. While models have become proficient at detecting explicit patterns, which typically appear in texts as single remarks referred to as utterances, such as social media posts, malicious actors have shifted toward utilizing implicit influential verbal patterns embedded within conversations. These verbal patterns aim to mentally penetrate the victim's mind in order to influence them, enabling the actor to obtain the desired information through implicit means. This paper presents an improved approach for detecting such implicit influential patterns. Furthermore, the proposed model is capable of identifying the specific locations of these influential elements within a conversation. To achieve this, the existing dataset was augmented using the reasoning capabilities of state-of-the-art language models. Our designed framework resulted in a 6% improvement in the detection of implicit influential patterns in conversations. Moreover, this approach improved the multi-label classification tasks related to both the techniques used for influence and the vulnerability of victims by 33% and 43%, respectively.
Predicting Through Generation: Why Generation Is Better for Prediction
Feb 25, 2025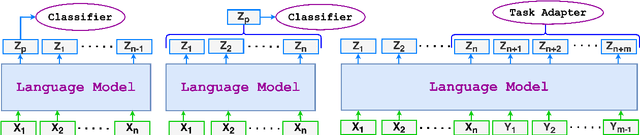
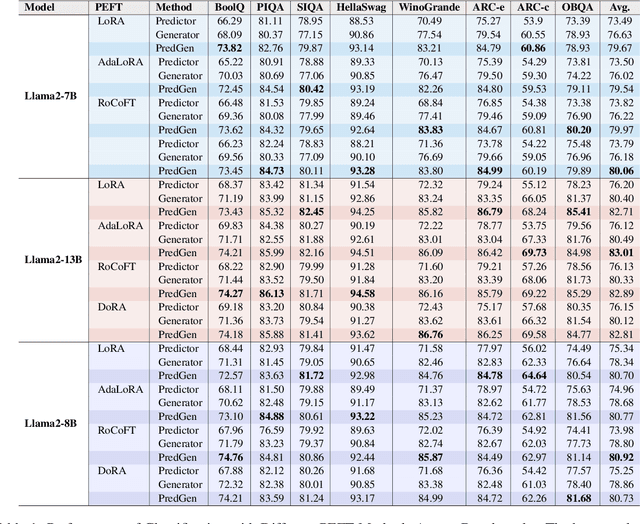
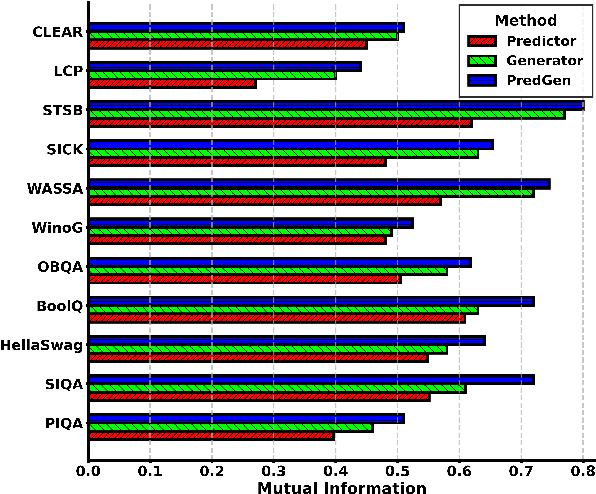
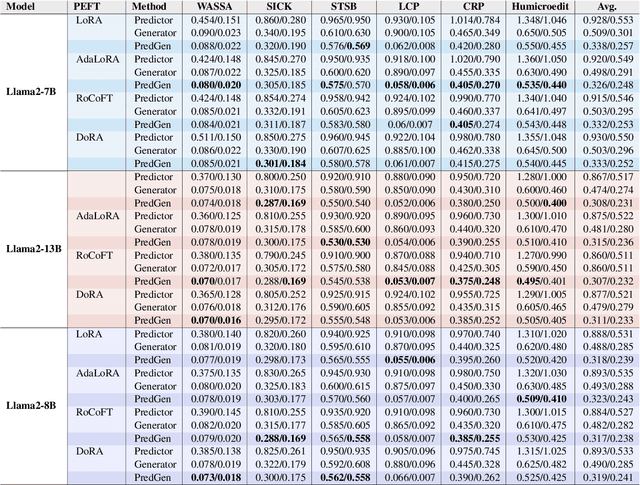
This paper argues that generating output tokens is more effective than using pooled representations for prediction tasks because token-level generation retains more mutual information. Since LLMs are trained on massive text corpora using next-token prediction, generation aligns naturally with their learned behavior. Using the Data Processing Inequality (DPI), we provide both theoretical and empirical evidence supporting this claim. However, autoregressive models face two key challenges when used for prediction: (1) exposure bias, where the model sees ground truth tokens during training but relies on its own predictions during inference, leading to errors, and (2) format mismatch, where discrete tokens do not always align with the tasks required output structure. To address these challenges, we introduce PredGen(Predicting Through Generating), an end to end framework that (i) uses scheduled sampling to reduce exposure bias, and (ii) introduces a task adapter to convert the generated tokens into structured outputs. Additionally, we introduce Writer-Director Alignment Loss (WDAL), which ensures consistency between token generation and final task predictions, improving both text coherence and numerical accuracy. We evaluate PredGen on multiple classification and regression benchmarks. Our results show that PredGen consistently outperforms standard baselines, demonstrating its effectiveness in structured prediction tasks.
BnTTS: Few-Shot Speaker Adaptation in Low-Resource Setting
Feb 09, 2025



This paper introduces BnTTS (Bangla Text-To-Speech), the first framework for Bangla speaker adaptation-based TTS, designed to bridge the gap in Bangla speech synthesis using minimal training data. Building upon the XTTS architecture, our approach integrates Bangla into a multilingual TTS pipeline, with modifications to account for the phonetic and linguistic characteristics of the language. We pre-train BnTTS on 3.85k hours of Bangla speech dataset with corresponding text labels and evaluate performance in both zero-shot and few-shot settings on our proposed test dataset. Empirical evaluations in few-shot settings show that BnTTS significantly improves the naturalness, intelligibility, and speaker fidelity of synthesized Bangla speech. Compared to state-of-the-art Bangla TTS systems, BnTTS exhibits superior performance in Subjective Mean Opinion Score (SMOS), Naturalness, and Clarity metrics.
LLM-Mixer: Multiscale Mixing in LLMs for Time Series Forecasting
Oct 15, 2024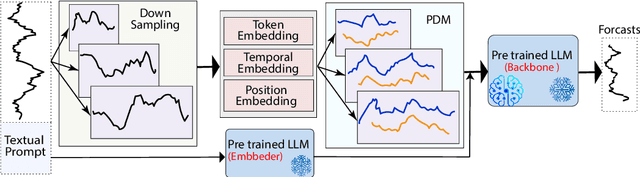


Time series forecasting remains a challenging task, particularly in the context of complex multiscale temporal patterns. This study presents LLM-Mixer, a framework that improves forecasting accuracy through the combination of multiscale time-series decomposition with pre-trained LLMs (Large Language Models). LLM-Mixer captures both short-term fluctuations and long-term trends by decomposing the data into multiple temporal resolutions and processing them with a frozen LLM, guided by a textual prompt specifically designed for time-series data. Extensive experiments conducted on multivariate and univariate datasets demonstrate that LLM-Mixer achieves competitive performance, outperforming recent state-of-the-art models across various forecasting horizons. This work highlights the potential of combining multiscale analysis and LLMs for effective and scalable time-series forecasting.
RoCoFT: Efficient Finetuning of Large Language Models with Row-Column Updates
Oct 15, 2024



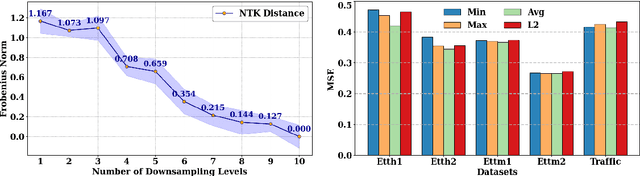
We propose RoCoFT, a parameter-efficient fine-tuning method for large-scale language models (LMs) based on updating only a few rows and columns of the weight matrices in transformers. Through extensive experiments with medium-size LMs like BERT and RoBERTa, and larger LMs like Bloom-7B, Llama2-7B, and Llama2-13B, we show that our method gives comparable or better accuracies than state-of-art PEFT methods while also being more memory and computation-efficient. We also study the reason behind the effectiveness of our method with tools from neural tangent kernel theory. We empirically demonstrate that our kernel, constructed using a restricted set of row and column parameters, are numerically close to the full-parameter kernel and gives comparable classification performance. Ablation studies are conducted to investigate the impact of different algorithmic choices, including the selection strategy for rows and columns as well as the optimal rank for effective implementation of our method.
Parameter-Efficient Fine-Tuning of Large Language Models using Semantic Knowledge Tuning
Oct 11, 2024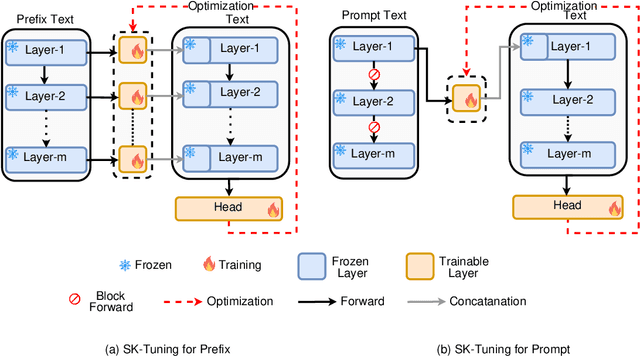
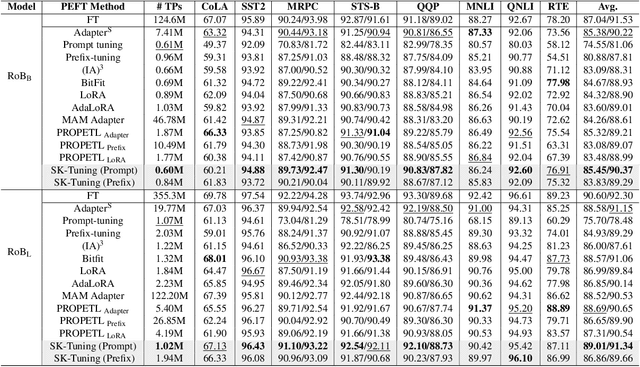
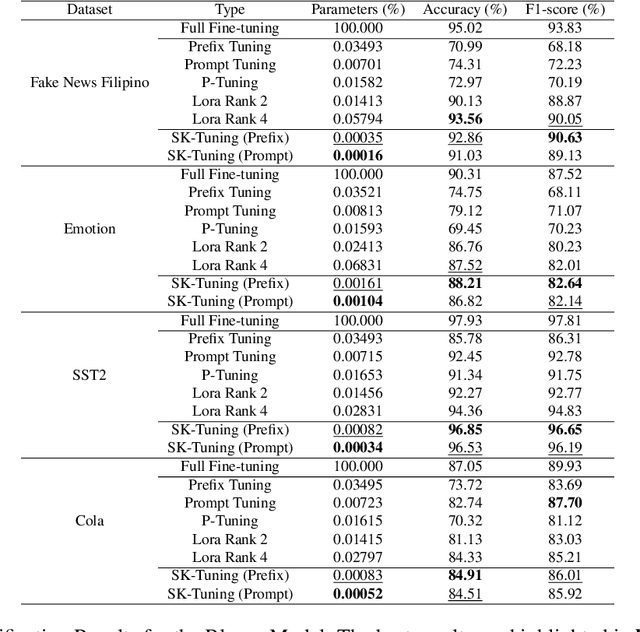
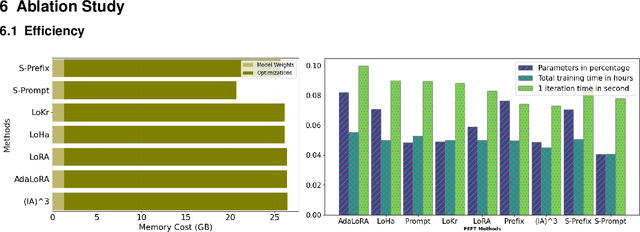
Large Language Models (LLMs) are gaining significant popularity in recent years for specialized tasks using prompts due to their low computational cost. Standard methods like prefix tuning utilize special, modifiable tokens that lack semantic meaning and require extensive training for best performance, often falling short. In this context, we propose a novel method called Semantic Knowledge Tuning (SK-Tuning) for prompt and prefix tuning that employs meaningful words instead of random tokens. This method involves using a fixed LLM to understand and process the semantic content of the prompt through zero-shot capabilities. Following this, it integrates the processed prompt with the input text to improve the model's performance on particular tasks. Our experimental results show that SK-Tuning exhibits faster training times, fewer parameters, and superior performance on tasks such as text classification and understanding compared to other tuning methods. This approach offers a promising method for optimizing the efficiency and effectiveness of LLMs in processing language tasks.