 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairContrast: Enhancing Fairness through Contrastive learning and Customized Augmenting Methods on Tabular Data
Oct 02, 2025As AI systems become more embedded in everyday life, the development of fair and unbiased models becomes more critical. Considering the social impact of AI systems is not merely a technical challenge but a moral imperative. As evidenced in numerous research studies, learning fair and robust representations has proven to be a powerful approach to effectively debiasing algorithms and improving fairness while maintaining essential information for prediction tasks. Representation learning frameworks, particularly those that utilize self-supervised and contrastive learning, have demonstrated superior robustness and generalizability across various domains. Despite the growing interest in applying these approaches to tabular data, the issue of fairness in these learned representations remains underexplored. In this study, we introduce a contrastive learning framework specifically designed to address bias and learn fair representations in tabular datasets. By strategically selecting positive pair samples and employing supervised and self-supervised contrastive learning, we significantly reduce bias compared to existing state-of-the-art contrastive learning models for tabular data. Our results demonstrate the efficacy of our approach in mitigating bias with minimum trade-off in accuracy and leveraging the learned fair representations in various downstream tasks.
Equi-mRNA: Protein Translation Equivariant Encoding for mRNA Language Models
Aug 20, 2025The growing importance of mRNA therapeutics and synthetic biology highlights the need for models that capture the latent structure of synonymous codon (different triplets encoding the same amino acid) usage, which subtly modulates translation efficiency and gene expression. While recent efforts incorporate codon-level inductive biases through auxiliary objectives, they often fall short of explicitly modeling the structured relationships that arise from the genetic code's inherent symmetries. We introduce Equi-mRNA, the first codon-level equivariant mRNA language model that explicitly encodes synonymous codon symmetries as cyclic subgroups of 2D Special Orthogonal matrix (SO(2)). By combining group-theoretic priors with an auxiliary equivariance loss and symmetry-aware pooling, Equi-mRNA learns biologically grounded representations that outperform vanilla baselines across multiple axes. On downstream property-prediction tasks including expression, stability, and riboswitch switching Equi-mRNA delivers up to approximately 10% improvements in accuracy. In sequence generation, it produces mRNA constructs that are up to approximately 4x more realistic under Frechet BioDistance metrics and approximately 28% better preserve functional properties compared to vanilla baseline. Interpretability analyses further reveal that learned codon-rotation distributions recapitulate known GC-content biases and tRNA abundance patterns, offering novel insights into codon usage. Equi-mRNA establishes a new biologically principled paradigm for mRNA modeling, with significant implications for the design of next-generation therapeutics.
BoKDiff: Best-of-K Diffusion Alignment for Target-Specific 3D Molecule Generation
Jan 26, 2025Structure-based drug design (SBDD) leverages the 3D structure of biomolecular targets to guide the creation of new therapeutic agents. Recent advances in generative models, including diffusion models and geometric deep learning, have demonstrated promise in optimizing ligand generation. However, the scarcity of high-quality protein-ligand complex data and the inherent challenges in aligning generated ligands with target proteins limit the effectiveness of these methods. We propose BoKDiff, a novel framework that enhances ligand generation by combining multi-objective optimization and Best-of-K alignment methodologies. Built upon the DecompDiff model, BoKDiff generates diverse candidates and ranks them using a weighted evaluation of molecular properties such as QED, SA, and docking scores. To address alignment challenges, we introduce a method that relocates the center of mass of generated ligands to their docking poses, enabling accurate sub-component extraction. Additionally, we integrate a Best-of-N (BoN) sampling approach, which selects the optimal ligand from multiple generated candidates without requiring fine-tuning. BoN achieves exceptional results, with QED values exceeding 0.6, SA scores above 0.75, and a success rate surpassing 35%, demonstrating its efficiency and practicality. BoKDiff achieves state-of-the-art results on the CrossDocked2020 dataset, including a -8.58 average Vina docking score and a 26% success rate in molecule generation. This study is the first to apply Best-of-K alignment and Best-of-N sampling to SBDD, highlighting their potential to bridge generative modeling with practical drug discovery requirements. The code is provided at https://github.com/khodabandeh-ali/BoKDiff.git.
Fair Bilevel Neural Network (FairBiNN): On Balancing fairness and accuracy via Stackelberg Equilibrium
Oct 21, 2024



The persistent challenge of bias in machine learning models necessitates robust solutions to ensure parity and equal treatment across diverse groups, particularly in classification tasks. Current methods for mitigating bias often result in information loss and an inadequate balance between accuracy and fairness. To address this, we propose a novel methodology grounded in bilevel optimization principles. Our deep learning-based approach concurrently optimizes for both accuracy and fairness objectives, and under certain assumptions, achieving proven Pareto optimal solutions while mitigating bias in the trained model. Theoretical analysis indicates that the upper bound on the loss incurred by this method is less than or equal to the loss of the Lagrangian approach, which involves adding a regularization term to the loss function. We demonstrate the efficacy of our model primarily on tabular datasets such as UCI Adult and Heritage Health. When benchmarked against state-of-the-art fairness methods, our model exhibits superior performance, advancing fairness-aware machine learning solutions and bridging the accuracy-fairness gap. The implementation of FairBiNN is available on https://github.com/yazdanimehdi/FairBiNN.
HELM: Hierarchical Encoding for mRNA Language Modeling
Oct 16, 2024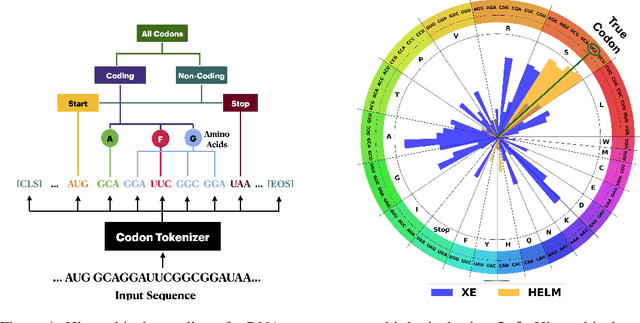
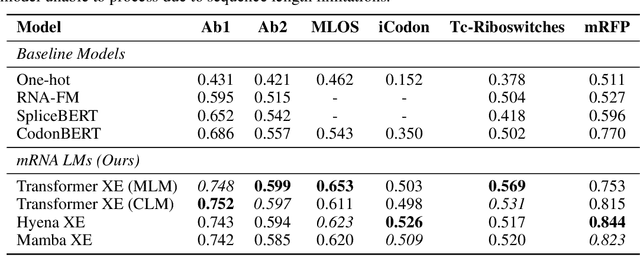
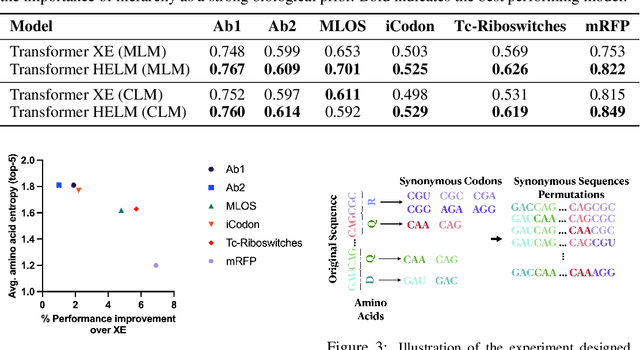
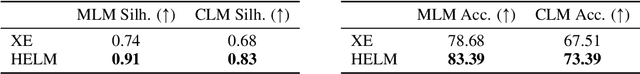
Messenger RNA (mRNA) plays a crucial role in protein synthesis, with its codon structure directly impacting biological properties. While Language Models (LMs) have shown promise in analyzing biological sequences, existing approaches fail to account for the hierarchical nature of mRNA's codon structure. We introduce Hierarchical Encoding for mRNA Language Modeling (HELM), a novel pre-training strategy that incorporates codon-level hierarchical structure into language model training. HELM modulates the loss function based on codon synonymity, aligning the model's learning process with the biological reality of mRNA sequences. We evaluate HELM on diverse mRNA datasets and tasks, demonstrating that HELM outperforms standard language model pre-training as well as existing foundation model baselines on six diverse downstream property prediction tasks and an antibody region annotation tasks on average by around 8\%. Additionally, HELM enhances the generative capabilities of language model, producing diverse mRNA sequences that better align with the underlying true data distribution compared to non-hierarchical baselines.
FragXsiteDTI: Revealing Responsible Segments in Drug-Target Interaction with Transformer-Driven Interpretation
Nov 04, 2023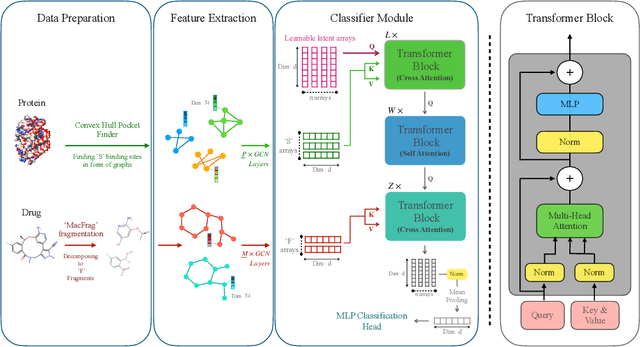
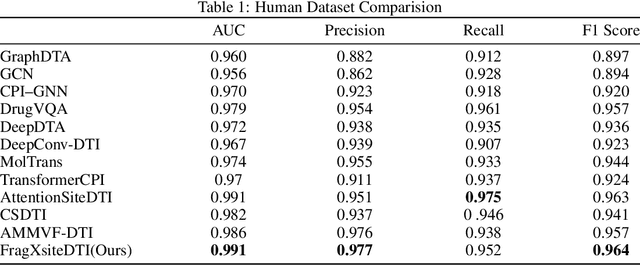
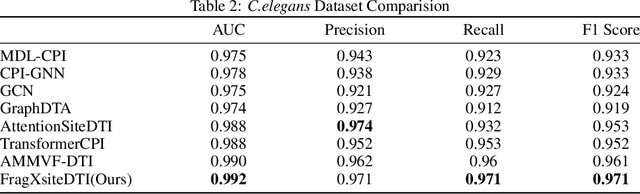
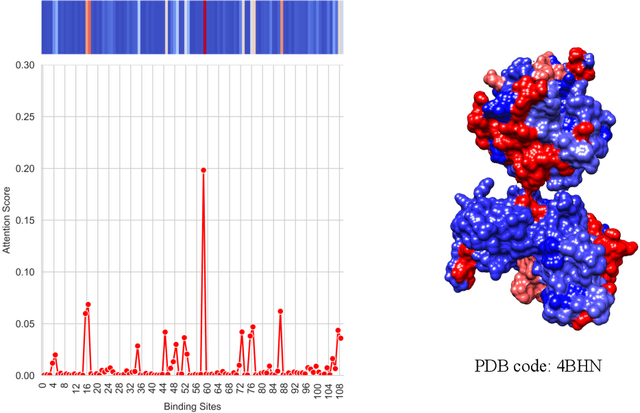
Drug-Target Interaction (DTI) prediction is vital for drug discovery, yet challenges persist in achieving model interpretability and optimizing performance. We propose a novel transformer-based model, FragXsiteDTI, that aims to address these challenges in DTI prediction. Notably, FragXsiteDTI is the first DTI model to simultaneously leverage drug molecule fragments and protein pockets. Our information-rich representations for both proteins and drugs offer a detailed perspective on their interaction. Inspired by the Perceiver IO framework, our model features a learnable latent array, initially interacting with protein binding site embeddings using cross-attention and later refined through self-attention and used as a query to the drug fragments in the drug's cross-attention transformer block. This learnable query array serves as a mediator and enables seamless information translation, preserving critical nuances in drug-protein interactions. Our computational results on three benchmarking datasets demonstrate the superior predictive power of our model over several state-of-the-art models. We also show the interpretability of our model in terms of the critical components of both target proteins and drug molecules within drug-target pairs.
Through a fair looking-glass: mitigating bias in image datasets
Sep 18, 2022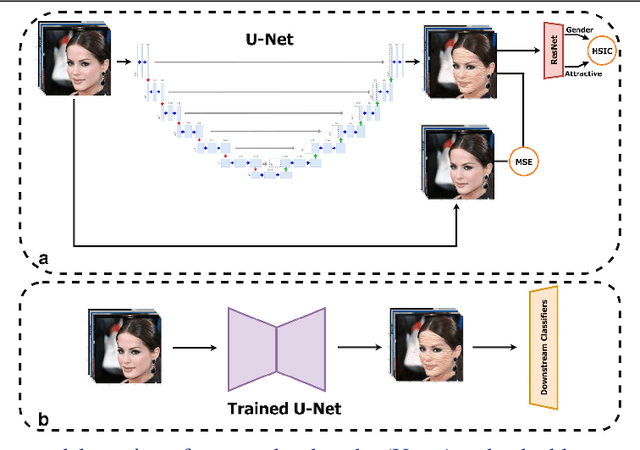



With the recent growth in computer vision applications, the question of how fair and unbiased they are has yet to be explored. There is abundant evidence that the bias present in training data is reflected in the models, or even amplified. Many previous methods for image dataset de-biasing, including models based on augmenting datasets, are computationally expensive to implement. In this study, we present a fast and effective model to de-bias an image dataset through reconstruction and minimizing the statistical dependence between intended variables. Our architecture includes a U-net to reconstruct images, combined with a pre-trained classifier which penalizes the statistical dependence between target attribute and the protected attribute. We evaluate our proposed model on CelebA dataset, compare the results with a state-of-the-art de-biasing method, and show that the model achieves a promising fairness-accuracy combination.
Distraction is All You Need for Fairness
Mar 15, 2022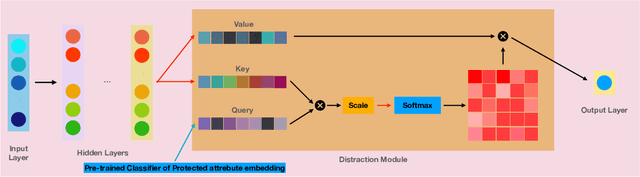
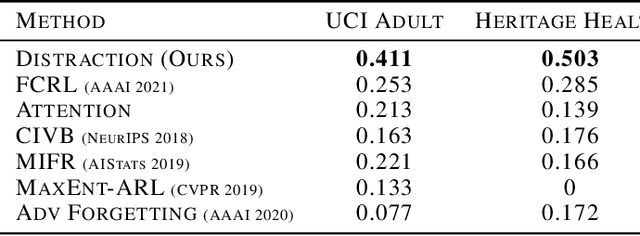
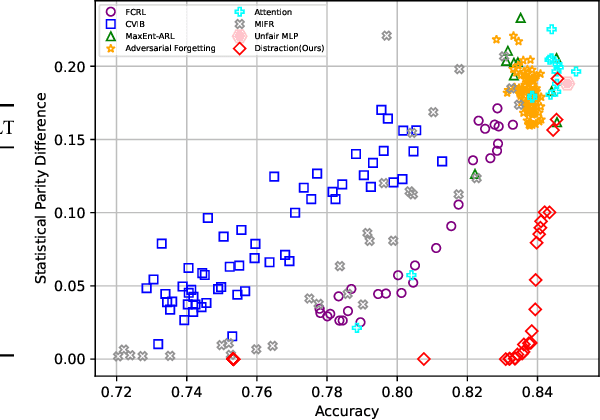
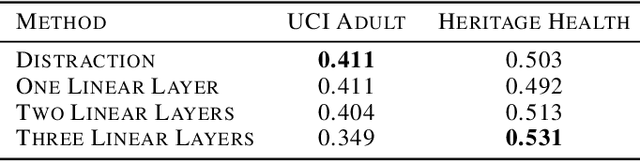
With the recent growth in artificial intelligence models and its expanding role in automated decision making, ensuring that these models are not biased is of vital importance. There is an abundance of evidence suggesting that these models could contain or even amplify the bias present in the data on which they are trained, inherent to their objective function and learning algorithms. In this paper, we propose a novel classification algorithm that improves fairness, while maintaining accuracy of the predictions. Utilizing the embedding layer of a pre-trained classifier for the protected attributes, the network uses an attention layer to distract the classification from depending on the protected attribute in its predictions. We compare our model with six state-of-the-art methodologies proposed in fairness literature, and show that the model is superior to those methods in terms of minimizing bias while maintaining accuracy.