 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Open Source Advantage in Large Language Models (LLMs)
Dec 16, 2024
Large language models (LLMs) mark a key shift in natural language processing (NLP), having advanced text generation, translation, and domain-specific reasoning. Closed-source models like GPT-4, powered by proprietary datasets and extensive computational resources, lead with state-of-the-art performance today. However, they face criticism for their "black box" nature and for limiting accessibility in a manner that hinders reproducibility and equitable AI development. By contrast, open-source initiatives like LLaMA and BLOOM prioritize democratization through community-driven development and computational efficiency. These models have significantly reduced performance gaps, particularly in linguistic diversity and domain-specific applications, while providing accessible tools for global researchers and developers. Notably, both paradigms rely on foundational architectural innovations, such as the Transformer framework by Vaswani et al. (2017). Closed-source models excel by scaling effectively, while open-source models adapt to real-world applications in underrepresented languages and domains. Techniques like Low-Rank Adaptation (LoRA) and instruction-tuning datasets enable open-source models to achieve competitive results despite limited resources. To be sure, the tension between closed-source and open-source approaches underscores a broader debate on transparency versus proprietary control in AI. Ethical considerations further highlight this divide. Closed-source systems restrict external scrutiny, while open-source models promote reproducibility and collaboration but lack standardized auditing documentation frameworks to mitigate biases. Hybrid approaches that leverage the strengths of both paradigms are likely to shape the future of LLM innovation, ensuring accessibility, competitive technical performance, and ethical deployment.
Resilience from Diversity: Population-based approach to harden models against adversarial attacks
Nov 19, 2021

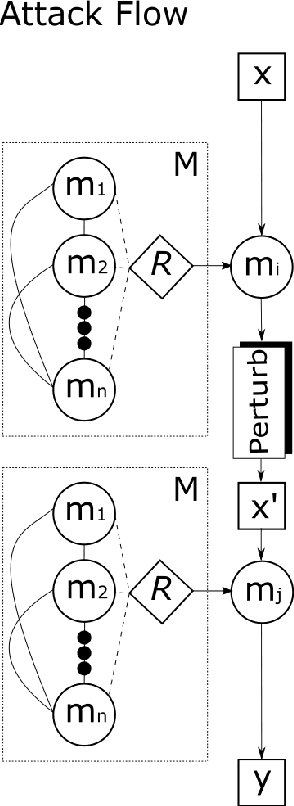

Traditional deep learning models exhibit intriguing vulnerabilities that allow an attacker to force them to fail at their task. Notorious attacks such as the Fast Gradient Sign Method (FGSM) and the more powerful Projected Gradient Descent (PGD) generate adversarial examples by adding a magnitude of perturbation $\epsilon$ to the input's computed gradient, resulting in a deterioration of the effectiveness of the model's classification. This work introduces a model that is resilient to adversarial attacks. Our model leverages a well established principle from biological sciences: population diversity produces resilience against environmental changes. More precisely, our model consists of a population of $n$ diverse submodels, each one of them trained to individually obtain a high accuracy for the task at hand, while forced to maintain meaningful differences in their weight tensors. Each time our model receives a classification query, it selects a submodel from its population at random to answer the query. To introduce and maintain diversity in population of submodels, we introduce the concept of counter linking weights. A Counter-Linked Model (CLM) consists of submodels of the same architecture where a periodic random similarity examination is conducted during the simultaneous training to guarantee diversity while maintaining accuracy. In our testing, CLM robustness got enhanced by around 20% when tested on the MNIST dataset and at least 15% when tested on the CIFAR-10 dataset. When implemented with adversarially trained submodels, this methodology achieves state-of-the-art robustness. On the MNIST dataset with $\epsilon=0.3$, it achieved 94.34% against FGSM and 91% against PGD. On the CIFAR-10 dataset with $\epsilon=8/255$, it achieved 62.97% against FGSM and 59.16% against PGD.
A Stance Data Set on Polarized Conversations on Twitter about the Efficacy of Hydroxychloroquine as a Treatment for COVID-19
Sep 05, 2020
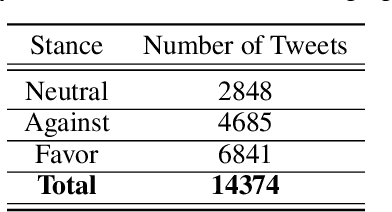

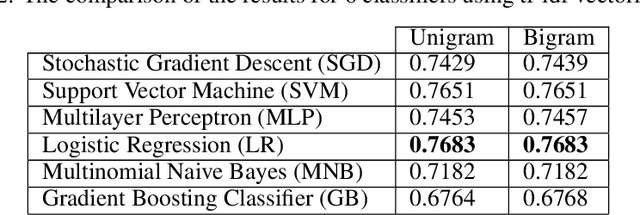
At the time of this study, the SARS-CoV-2 virus that caused the COVID-19 pandemic has spread significantly across the world. Considering the uncertainty about policies, health risks, financial difficulties, etc. the online media, specially the Twitter platform, is experiencing a high volume of activity related to this pandemic. Among the hot topics, the polarized debates about unconfirmed medicines for the treatment and prevention of the disease have attracted significant attention from online media users. In this work, we present a stance data set, COVID-CQ, of user-generated content on Twitter in the context of COVID-19. We investigated more than 14 thousand tweets and manually annotated the opinions of the tweet initiators regarding the use of "chloroquine" and "hydroxychloroquine" for the treatment or prevention of COVID-19. To the best of our knowledge, COVID-CQ is the first data set of Twitter users' stances in the context of the COVID-19 pandemic, and the largest Twitter data set on users' stances towards a claim, in any domain. We have made this data set available to the research community via GitHub. We expect this data set to be useful for many research purposes, including stance detection, evolution and dynamics of opinions regarding this outbreak, and changes in opinions in response to the exogenous shocks such as policy decisions and events.
Probabilistic Model of Narratives Over Topical Trends in Social Media: A Discrete Time Model
Apr 14, 2020
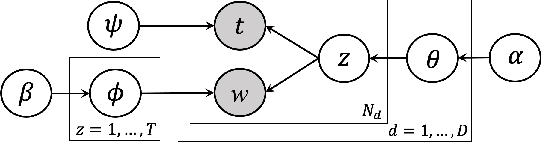
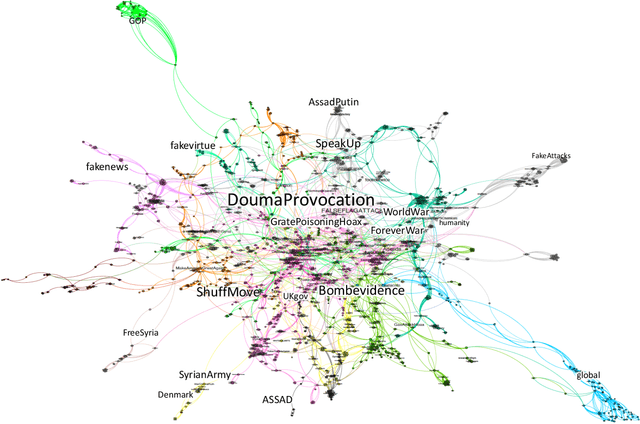

Online social media platforms are turning into the prime source of news and narratives about worldwide events. However,a systematic summarization-based narrative extraction that can facilitate communicating the main underlying events is lacking. To address this issue, we propose a novel event-based narrative summary extraction framework. Our proposed framework is designed as a probabilistic topic model, with categorical time distribution, followed by extractive text summarization. Our topic model identifies topics' recurrence over time with a varying time resolution. This framework not only captures the topic distributions from the data, but also approximates the user activity fluctuations over time. Furthermore, we define significance-dispersity trade-off (SDT) as a comparison measure to identify the topic with the highest lifetime attractiveness in a timestamped corpus. We evaluate our model on a large corpus of Twitter data, including more than one million tweets in the domain of the disinformation campaigns conducted against the White Helmets of Syria. Our results indicate that the proposed framework is effective in identifying topical trends, as well as extracting narrative summaries from text corpus with timestamped data.