 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDominant Set-based Active Learning for Text Classification and its Application to Online Social Media
Jan 28, 2022Recent advances in natural language processing (NLP) in online social media are evidently owed to large-scale datasets. However, labeling, storing, and processing a large number of textual data points, e.g., tweets, has remained challenging. On top of that, in applications such as hate speech detection, labeling a sufficiently large dataset containing offensive content can be mentally and emotionally taxing for human annotators. Thus, NLP methods that can make the best use of significantly less labeled data points are of great interest. In this paper, we present a novel pool-based active learning method that can be used for the training of large unlabeled corpus with minimum annotation cost. For that, we propose to find the dominant sets of local clusters in the feature space. These sets represent maximally cohesive structures in the data. Then, the samples that do not belong to any of the dominant sets are selected to be used to train the model, as they represent the boundaries of the local clusters and are more challenging to classify. Our proposed method does not have any parameters to be tuned, making it dataset-independent, and it can approximately achieve the same classification accuracy as full training data, with significantly fewer data points. Additionally, our method achieves a higher performance in comparison to the state-of-the-art active learning strategies. Furthermore, our proposed algorithm is able to incorporate conventional active learning scores, such as uncertainty-based scores, into its selection criteria. We show the effectiveness of our method on different datasets and using different neural network architectures.
A Stance Data Set on Polarized Conversations on Twitter about the Efficacy of Hydroxychloroquine as a Treatment for COVID-19
Sep 05, 2020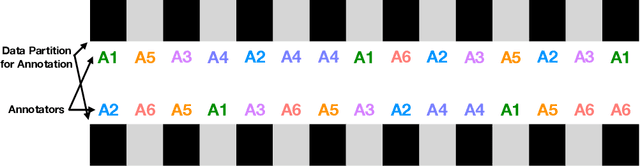
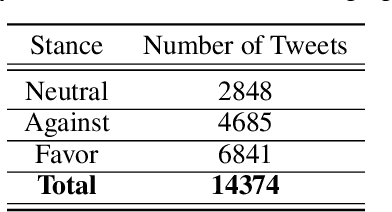

At the time of this study, the SARS-CoV-2 virus that caused the COVID-19 pandemic has spread significantly across the world. Considering the uncertainty about policies, health risks, financial difficulties, etc. the online media, specially the Twitter platform, is experiencing a high volume of activity related to this pandemic. Among the hot topics, the polarized debates about unconfirmed medicines for the treatment and prevention of the disease have attracted significant attention from online media users. In this work, we present a stance data set, COVID-CQ, of user-generated content on Twitter in the context of COVID-19. We investigated more than 14 thousand tweets and manually annotated the opinions of the tweet initiators regarding the use of "chloroquine" and "hydroxychloroquine" for the treatment or prevention of COVID-19. To the best of our knowledge, COVID-CQ is the first data set of Twitter users' stances in the context of the COVID-19 pandemic, and the largest Twitter data set on users' stances towards a claim, in any domain. We have made this data set available to the research community via GitHub. We expect this data set to be useful for many research purposes, including stance detection, evolution and dynamics of opinions regarding this outbreak, and changes in opinions in response to the exogenous shocks such as policy decisions and events.
Probabilistic Model of Narratives Over Topical Trends in Social Media: A Discrete Time Model
Apr 14, 2020
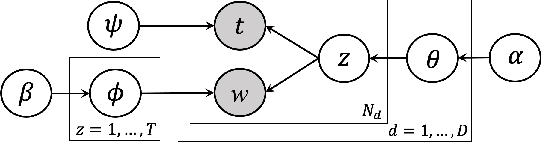
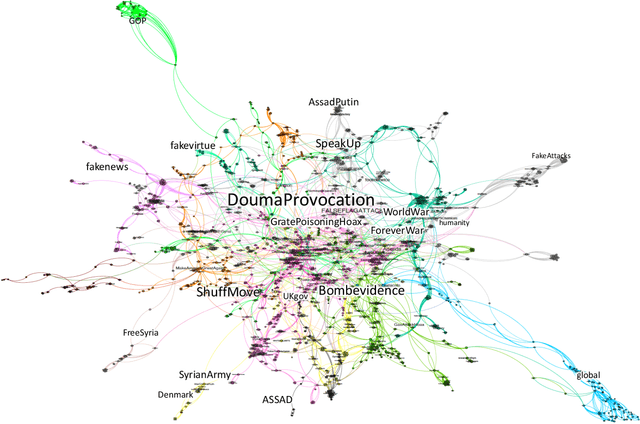

Online social media platforms are turning into the prime source of news and narratives about worldwide events. However,a systematic summarization-based narrative extraction that can facilitate communicating the main underlying events is lacking. To address this issue, we propose a novel event-based narrative summary extraction framework. Our proposed framework is designed as a probabilistic topic model, with categorical time distribution, followed by extractive text summarization. Our topic model identifies topics' recurrence over time with a varying time resolution. This framework not only captures the topic distributions from the data, but also approximates the user activity fluctuations over time. Furthermore, we define significance-dispersity trade-off (SDT) as a comparison measure to identify the topic with the highest lifetime attractiveness in a timestamped corpus. We evaluate our model on a large corpus of Twitter data, including more than one million tweets in the domain of the disinformation campaigns conducted against the White Helmets of Syria. Our results indicate that the proposed framework is effective in identifying topical trends, as well as extracting narrative summaries from text corpus with timestamped data.