 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Mixer: Multiscale Mixing in LLMs for Time Series Forecasting
Oct 15, 2024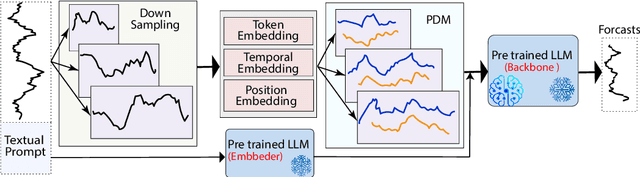


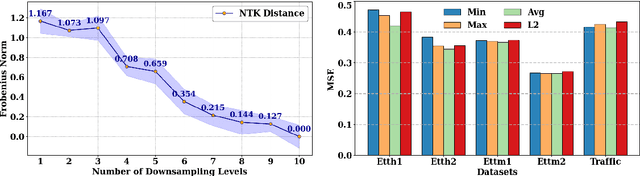
Time series forecasting remains a challenging task, particularly in the context of complex multiscale temporal patterns. This study presents LLM-Mixer, a framework that improves forecasting accuracy through the combination of multiscale time-series decomposition with pre-trained LLMs (Large Language Models). LLM-Mixer captures both short-term fluctuations and long-term trends by decomposing the data into multiple temporal resolutions and processing them with a frozen LLM, guided by a textual prompt specifically designed for time-series data. Extensive experiments conducted on multivariate and univariate datasets demonstrate that LLM-Mixer achieves competitive performance, outperforming recent state-of-the-art models across various forecasting horizons. This work highlights the potential of combining multiscale analysis and LLMs for effective and scalable time-series forecasting.
Parameter-Efficient Fine-Tuning of Large Language Models using Semantic Knowledge Tuning
Oct 11, 2024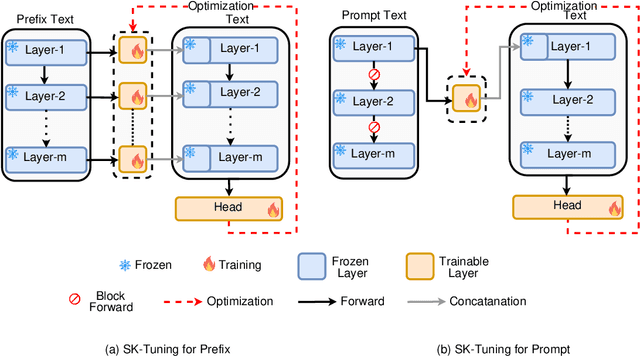
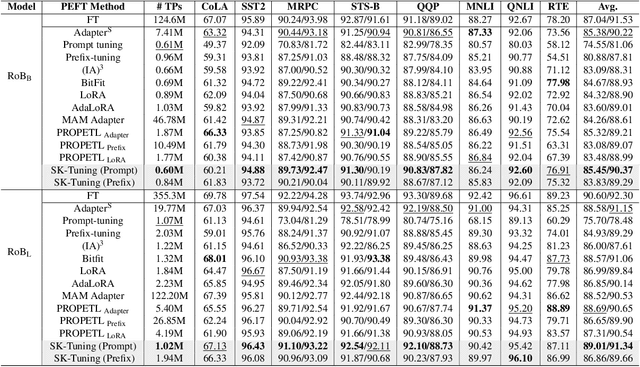
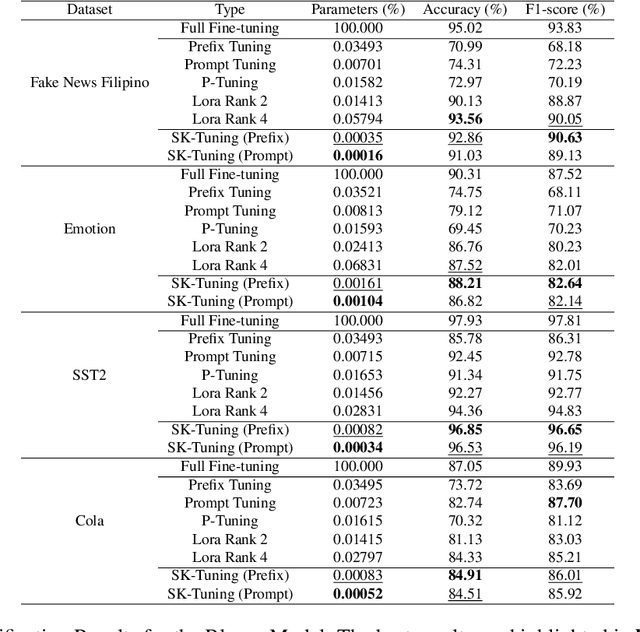
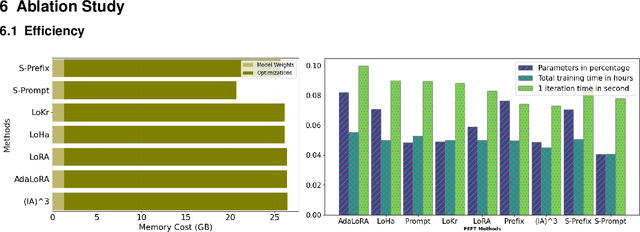
Large Language Models (LLMs) are gaining significant popularity in recent years for specialized tasks using prompts due to their low computational cost. Standard methods like prefix tuning utilize special, modifiable tokens that lack semantic meaning and require extensive training for best performance, often falling short. In this context, we propose a novel method called Semantic Knowledge Tuning (SK-Tuning) for prompt and prefix tuning that employs meaningful words instead of random tokens. This method involves using a fixed LLM to understand and process the semantic content of the prompt through zero-shot capabilities. Following this, it integrates the processed prompt with the input text to improve the model's performance on particular tasks. Our experimental results show that SK-Tuning exhibits faster training times, fewer parameters, and superior performance on tasks such as text classification and understanding compared to other tuning methods. This approach offers a promising method for optimizing the efficiency and effectiveness of LLMs in processing language tasks.
A Classical Approach to Handcrafted Feature Extraction Techniques for Bangla Handwritten Digit Recognition
Jan 25, 2022



Bangla Handwritten Digit recognition is a significant step forward in the development of Bangla OCR. However, intricate shape, structural likeness and distinctive composition style of Bangla digits makes it relatively challenging to distinguish. Thus, in this paper, we benchmarked four rigorous classifiers to recognize Bangla Handwritten Digit: K-Nearest Neighbor (KNN), Support Vector Machine (SVM), Random Forest (RF), and Gradient-Boosted Decision Trees (GBDT) based on three handcrafted feature extraction techniques: Histogram of Oriented Gradients (HOG), Local Binary Pattern (LBP), and Gabor filter on four publicly available Bangla handwriting digits datasets: NumtaDB, CMARTdb, Ekush and BDRW. Here, handcrafted feature extraction methods are used to extract features from the dataset image, which are then utilized to train machine learning classifiers to identify Bangla handwritten digits. We further fine-tuned the hyperparameters of the classification algorithms in order to acquire the finest Bangla handwritten digits recognition performance from these algorithms, and among all the models we employed, the HOG features combined with SVM model (HOG+SVM) attained the best performance metrics across all datasets. The recognition accuracy of the HOG+SVM method on the NumtaDB, CMARTdb, Ekush and BDRW datasets reached 93.32%, 98.08%, 95.68% and 89.68%, respectively as well as we compared the model performance with recent state-of-art methods.