 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMENASpeechBank: A Reference Voice Bank with Persona-Conditioned Multi-Turn Conversations for AudioLLMs
Feb 03, 2026Audio large language models (AudioLLMs) enable instruction-following over speech and general audio, but progress is increasingly limited by the lack of diverse, conversational, instruction-aligned speech-text data. This bottleneck is especially acute for persona-grounded interactions and dialectal coverage, where collecting and releasing real multi-speaker recordings is costly and slow. We introduce MENASpeechBank, a reference speech bank comprising about 18K high-quality utterances from 124 speakers spanning multiple MENA countries, covering English, Modern Standard Arabic (MSA), and regional Arabic varieties. Building on this resource, we develop a controllable synthetic data pipeline that: (i) constructs persona profiles enriched with World Values Survey-inspired attributes, (ii) defines a taxonomy of about 5K conversational scenarios, (iii) matches personas to scenarios via semantic similarity, (iv) generates about 417K role-play conversations with an LLM where the user speaks as the persona and the assistant behaves as a helpful agent, and (v) synthesizes the user turns by conditioning on reference speaker audio to preserve speaker identity and diversity. We evaluate both synthetic and human-recorded conversations and provide detailed analysis. We will release MENASpeechBank and the generated conversations publicly for the community.
BnTTS: Few-Shot Speaker Adaptation in Low-Resource Setting
Feb 09, 2025



This paper introduces BnTTS (Bangla Text-To-Speech), the first framework for Bangla speaker adaptation-based TTS, designed to bridge the gap in Bangla speech synthesis using minimal training data. Building upon the XTTS architecture, our approach integrates Bangla into a multilingual TTS pipeline, with modifications to account for the phonetic and linguistic characteristics of the language. We pre-train BnTTS on 3.85k hours of Bangla speech dataset with corresponding text labels and evaluate performance in both zero-shot and few-shot settings on our proposed test dataset. Empirical evaluations in few-shot settings show that BnTTS significantly improves the naturalness, intelligibility, and speaker fidelity of synthesized Bangla speech. Compared to state-of-the-art Bangla TTS systems, BnTTS exhibits superior performance in Subjective Mean Opinion Score (SMOS), Naturalness, and Clarity metrics.
Pseudo-Labeling for Domain-Agnostic Bangla Automatic Speech Recognition
Nov 06, 2023



One of the major challenges for developing automatic speech recognition (ASR) for low-resource languages is the limited access to labeled data with domain-specific variations. In this study, we propose a pseudo-labeling approach to develop a large-scale domain-agnostic ASR dataset. With the proposed methodology, we developed a 20k+ hours labeled Bangla speech dataset covering diverse topics, speaking styles, dialects, noisy environments, and conversational scenarios. We then exploited the developed corpus to design a conformer-based ASR system. We benchmarked the trained ASR with publicly available datasets and compared it with other available models. To investigate the efficacy, we designed and developed a human-annotated domain-agnostic test set composed of news, telephony, and conversational data among others. Our results demonstrate the efficacy of the model trained on psuedo-label data for the designed test-set along with publicly-available Bangla datasets. The experimental resources will be publicly available.(https://github.com/hishab-nlp/Pseudo-Labeling-for-Domain-Agnostic-Bangla-ASR)
QCRI at SemEval-2023 Task 3: News Genre, Framing and Persuasion Techniques Detection using Multilingual Models
May 05, 2023Misinformation spreading in mainstream and social media has been misleading users in different ways. Manual detection and verification efforts by journalists and fact-checkers can no longer cope with the great scale and quick spread of misleading information. This motivated research and industry efforts to develop systems for analyzing and verifying news spreading online. The SemEval-2023 Task 3 is an attempt to address several subtasks under this overarching problem, targeting writing techniques used in news articles to affect readers' opinions. The task addressed three subtasks with six languages, in addition to three ``surprise'' test languages, resulting in 27 different test setups. This paper describes our participating system to this task. Our team is one of the 6 teams that successfully submitted runs for all setups. The official results show that our system is ranked among the top 3 systems for 10 out of the 27 setups.
Device-friendly Guava fruit and leaf disease detection using deep learning
Sep 26, 2022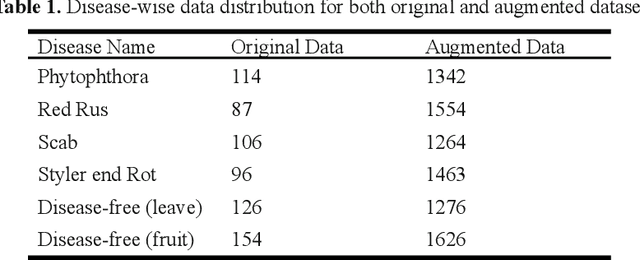

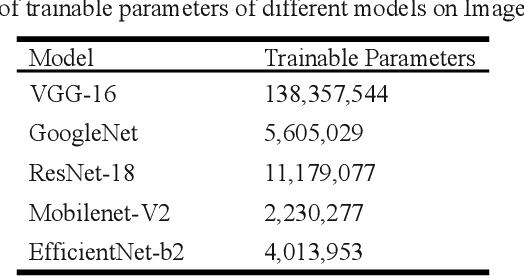
This work presents a deep learning-based plant disease diagnostic system using images of fruits and leaves. Five state-of-the-art convolutional neural networks (CNN) have been employed for implementing the system. Hitherto model accuracy has been the focus for such applications and model optimization has not been accounted for the model to be applicable to end-user devices. Two model quantization techniques such as float16 and dynamic range quantization have been applied to the five state-of-the-art CNN architectures. The study shows that the quantized GoogleNet model achieved the size of 0.143 MB with an accuracy of 97%, which is the best candidate model considering the size criterion. The EfficientNet model achieved the size of 4.2MB with an accuracy of 99%, which is the best model considering the performance criterion. The source codes are available at https://github.com/CompostieAI/Guava-disease-detection.
TeamX@DravidianLangTech-ACL2022: A Comparative Analysis for Troll-Based Meme Classification
May 09, 2022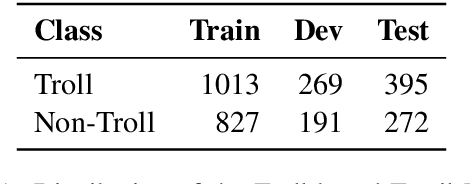
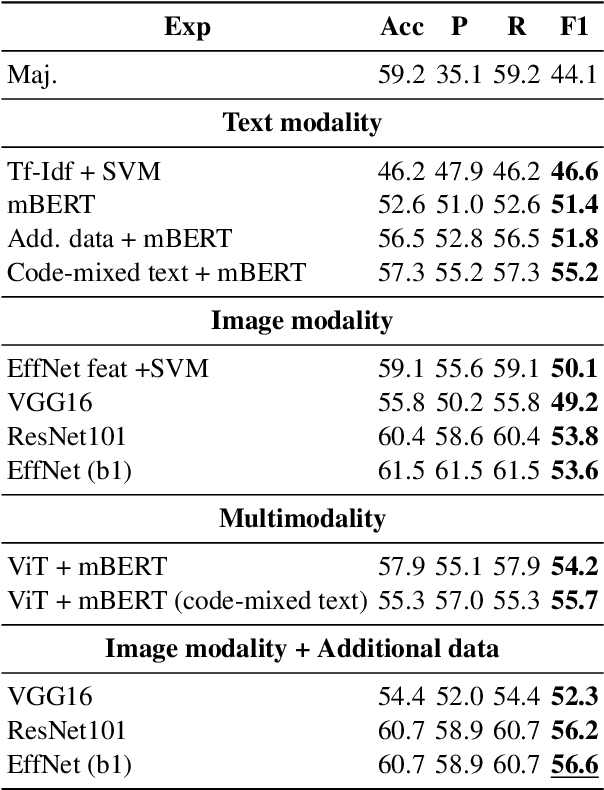
The spread of fake news, propaganda, misinformation, disinformation, and harmful content online raised concerns among social media platforms, government agencies, policymakers, and society as a whole. This is because such harmful or abusive content leads to several consequences to people such as physical, emotional, relational, and financial. Among different harmful content \textit{trolling-based} online content is one of them, where the idea is to post a message that is provocative, offensive, or menacing with an intent to mislead the audience. The content can be textual, visual, a combination of both, or a meme. In this study, we provide a comparative analysis of troll-based memes classification using the textual, visual, and multimodal content. We report several interesting findings in terms of code-mixed text, multimodal setting, and combining an additional dataset, which shows improvements over the majority baseline.
Detecting the Role of an Entity in Harmful Memes: Techniques and Their Limitations
May 09, 2022
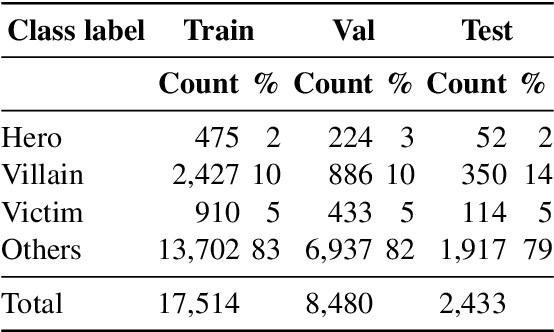

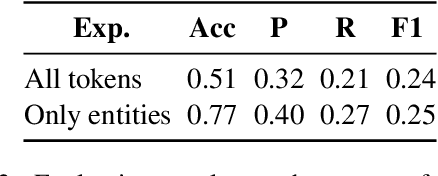
Harmful or abusive online content has been increasing over time, raising concerns for social media platforms, government agencies, and policymakers. Such harmful or abusive content can have major negative impact on society, e.g., cyberbullying can lead to suicides, rumors about COVID-19 can cause vaccine hesitance, promotion of fake cures for COVID-19 can cause health harms and deaths. The content that is posted and shared online can be textual, visual, or a combination of both, e.g., in a meme. Here, we describe our experiments in detecting the roles of the entities (hero, villain, victim) in harmful memes, which is part of the CONSTRAINT-2022 shared task, as well as our system for the task. We further provide a comparative analysis of different experimental settings (i.e., unimodal, multimodal, attention, and augmentation). For reproducibility, we make our experimental code publicly available. \url{https://github.com/robi56/harmful_memes_block_fusion}