 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePseudo-Labeling for Domain-Agnostic Bangla Automatic Speech Recognition
Nov 06, 2023



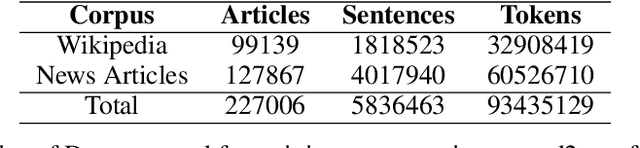
One of the major challenges for developing automatic speech recognition (ASR) for low-resource languages is the limited access to labeled data with domain-specific variations. In this study, we propose a pseudo-labeling approach to develop a large-scale domain-agnostic ASR dataset. With the proposed methodology, we developed a 20k+ hours labeled Bangla speech dataset covering diverse topics, speaking styles, dialects, noisy environments, and conversational scenarios. We then exploited the developed corpus to design a conformer-based ASR system. We benchmarked the trained ASR with publicly available datasets and compared it with other available models. To investigate the efficacy, we designed and developed a human-annotated domain-agnostic test set composed of news, telephony, and conversational data among others. Our results demonstrate the efficacy of the model trained on psuedo-label data for the designed test-set along with publicly-available Bangla datasets. The experimental resources will be publicly available.(https://github.com/hishab-nlp/Pseudo-Labeling-for-Domain-Agnostic-Bangla-ASR)
BNLP: Natural language processing toolkit for Bengali language
Jan 31, 2021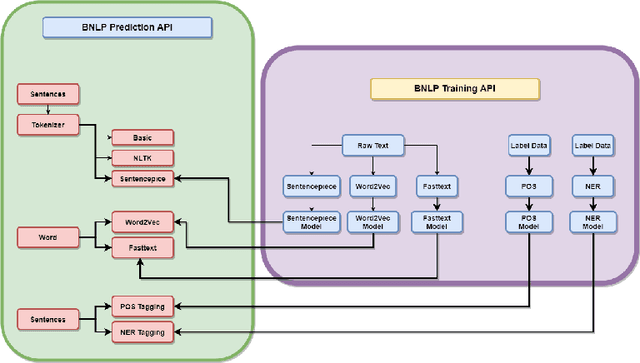


BNLP is an open source language processing toolkit for Bengali language consisting with tokenization, word embedding, POS tagging, NER tagging facilities. BNLP provides pre-trained model with high accuracy to do model based tokenization, embedding, POS tagging, NER tagging task for Bengali language. BNLP pre-trained model achieves significant results in Bengali text tokenization, word embedding, POS tagging and NER tagging task. BNLP is using widely in the Bengali research communities with 16K downloads, 119 stars and 31 forks. BNLP is available at https://github.com/sagorbrur/bnlp.