 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBALSAM: A Platform for Benchmarking Arabic Large Language Models
Jul 30, 2025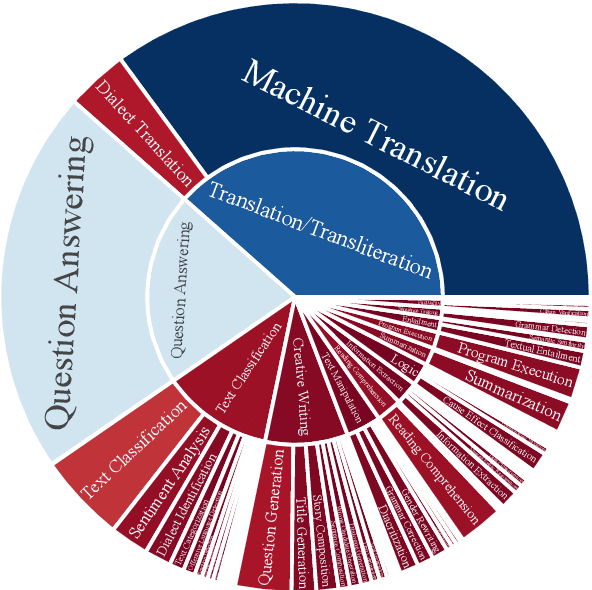



The impressive advancement of Large Language Models (LLMs) in English has not been matched across all languages. In particular, LLM performance in Arabic lags behind, due to data scarcity, linguistic diversity of Arabic and its dialects, morphological complexity, etc. Progress is further hindered by the quality of Arabic benchmarks, which typically rely on static, publicly available data, lack comprehensive task coverage, or do not provide dedicated platforms with blind test sets. This makes it challenging to measure actual progress and to mitigate data contamination. Here, we aim to bridge these gaps. In particular, we introduce BALSAM, a comprehensive, community-driven benchmark aimed at advancing Arabic LLM development and evaluation. It includes 78 NLP tasks from 14 broad categories, with 52K examples divided into 37K test and 15K development, and a centralized, transparent platform for blind evaluation. We envision BALSAM as a unifying platform that sets standards and promotes collaborative research to advance Arabic LLM capabilities.
Reasoning About Persuasion: Can LLMs Enable Explainable Propaganda Detection?
Feb 23, 2025There has been significant research on propagandistic content detection across different modalities and languages. However, most studies have primarily focused on detection, with little attention given to explanations justifying the predicted label. This is largely due to the lack of resources that provide explanations alongside annotated labels. To address this issue, we propose a multilingual (i.e., Arabic and English) explanation-enhanced dataset, the first of its kind. Additionally, we introduce an explanation-enhanced LLM for both label detection and rationale-based explanation generation. Our findings indicate that the model performs comparably while also generating explanations. We will make the dataset and experimental resources publicly available for the research community.
LlamaLens: Specialized Multilingual LLM for Analyzing News and Social Media Content
Oct 20, 2024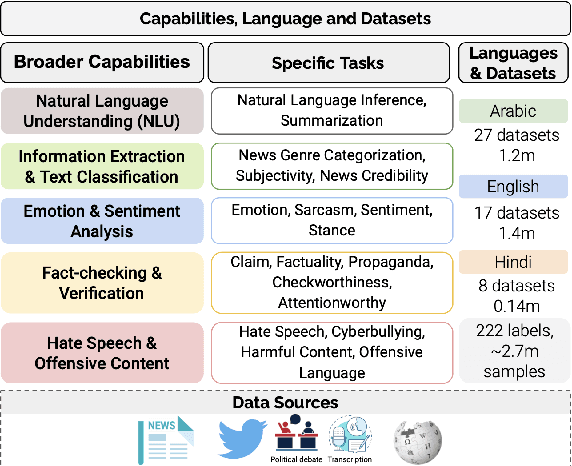
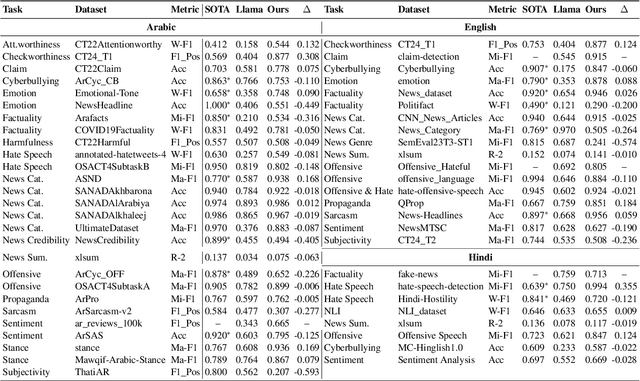
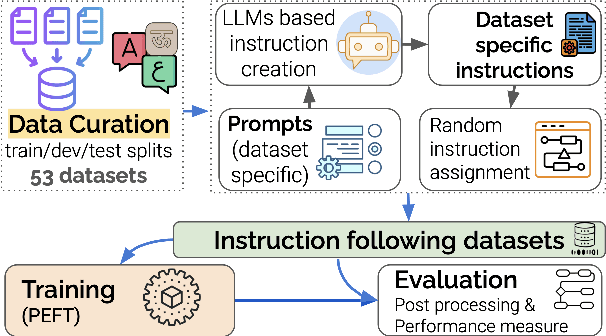
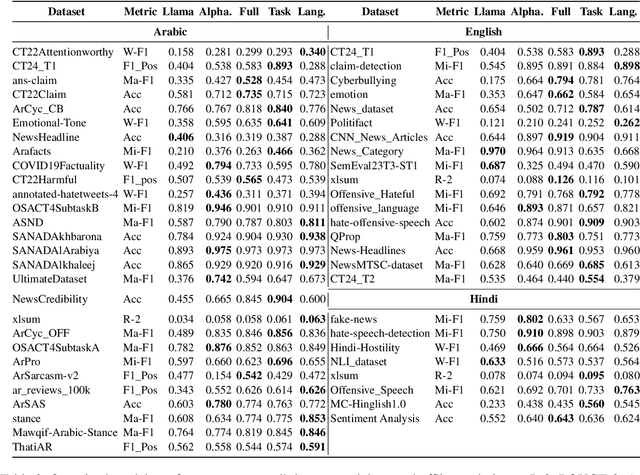
Large Language Models (LLMs) have demonstrated remarkable success as general-purpose task solvers across various fields, including NLP, healthcare, finance, and law. However, their capabilities remain limited when addressing domain-specific problems, particularly in downstream NLP tasks. Research has shown that models fine-tuned on instruction-based downstream NLP datasets outperform those that are not fine-tuned. While most efforts in this area have primarily focused on resource-rich languages like English and broad domains, little attention has been given to multilingual settings and specific domains. To address this gap, this study focuses on developing a specialized LLM, LlamaLens, for analyzing news and social media content in a multilingual context. To the best of our knowledge, this is the first attempt to tackle both domain specificity and multilinguality, with a particular focus on news and social media. Our experimental setup includes 19 tasks, represented by 52 datasets covering Arabic, English, and Hindi. We demonstrate that LlamaLens outperforms the current state-of-the-art (SOTA) on 16 testing sets, and achieves comparable performance on 10 sets. We make the models and resources publicly available for the research community.(https://huggingface.co/QCRI)
AraDiCE: Benchmarks for Dialectal and Cultural Capabilities in LLMs
Sep 17, 2024Arabic, with its rich diversity of dialects, remains significantly underrepresented in Large Language Models, particularly in dialectal variations. We address this gap by introducing seven synthetic datasets in dialects alongside Modern Standard Arabic (MSA), created using Machine Translation (MT) combined with human post-editing. We present AraDiCE, a benchmark for Arabic Dialect and Cultural Evaluation. We evaluate LLMs on dialect comprehension and generation, focusing specifically on low-resource Arabic dialects. Additionally, we introduce the first-ever fine-grained benchmark designed to evaluate cultural awareness across the Gulf, Egypt, and Levant regions, providing a novel dimension to LLM evaluation. Our findings demonstrate that while Arabic-specific models like Jais and AceGPT outperform multilingual models on dialectal tasks, significant challenges persist in dialect identification, generation, and translation. This work contributes ~45K post-edited samples, a cultural benchmark, and highlights the importance of tailored training to improve LLM performance in capturing the nuances of diverse Arabic dialects and cultural contexts. We will release the dialectal translation models and benchmarks curated in this study.
Native vs Non-Native Language Prompting: A Comparative Analysis
Sep 11, 2024



Large language models (LLMs) have shown remarkable abilities in different fields, including standard Natural Language Processing (NLP) tasks. To elicit knowledge from LLMs, prompts play a key role, consisting of natural language instructions. Most open and closed source LLMs are trained on available labeled and unlabeled resources--digital content such as text, images, audio, and videos. Hence, these models have better knowledge for high-resourced languages but struggle with low-resourced languages. Since prompts play a crucial role in understanding their capabilities, the language used for prompts remains an important research question. Although there has been significant research in this area, it is still limited, and less has been explored for medium to low-resourced languages. In this study, we investigate different prompting strategies (native vs. non-native) on 11 different NLP tasks associated with 12 different Arabic datasets (9.7K data points). In total, we conducted 197 experiments involving 3 LLMs, 12 datasets, and 3 prompting strategies. Our findings suggest that, on average, the non-native prompt performs the best, followed by mixed and native prompts.
NativQA: Multilingual Culturally-Aligned Natural Query for LLMs
Jul 13, 2024Natural Question Answering (QA) datasets play a crucial role in developing and evaluating the capabilities of large language models (LLMs), ensuring their effective usage in real-world applications. Despite the numerous QA datasets that have been developed, there is a notable lack of region-specific datasets generated by native users in their own languages. This gap hinders the effective benchmarking of LLMs for regional and cultural specificities. In this study, we propose a scalable framework, NativQA, to seamlessly construct culturally and regionally aligned QA datasets in native languages, for LLM evaluation and tuning. Moreover, to demonstrate the efficacy of the proposed framework, we designed a multilingual natural QA dataset, MultiNativQA, consisting of ~72K QA pairs in seven languages, ranging from high to extremely low resource, based on queries from native speakers covering 18 topics. We benchmark the MultiNativQA dataset with open- and closed-source LLMs. We made both the framework NativQA and MultiNativQA dataset publicly available for the community. (https://nativqa.gitlab.io)
ArAIEval Shared Task: Propagandistic Techniques Detection in Unimodal and Multimodal Arabic Content
Jul 05, 2024


We present an overview of the second edition of the ArAIEval shared task, organized as part of the ArabicNLP 2024 conference co-located with ACL 2024. In this edition, ArAIEval offers two tasks: (i) detection of propagandistic textual spans with persuasion techniques identification in tweets and news articles, and (ii) distinguishing between propagandistic and non-propagandistic memes. A total of 14 teams participated in the final evaluation phase, with 6 and 9 teams participating in Tasks 1 and 2, respectively. Finally, 11 teams submitted system description papers. Across both tasks, we observed that fine-tuning transformer models such as AraBERT was at the core of the majority of the participating systems. We provide a description of the task setup, including a description of the dataset construction and the evaluation setup. We further provide a brief overview of the participating systems. All datasets and evaluation scripts are released to the research community (https://araieval.gitlab.io/). We hope this will enable further research on these important tasks in Arabic.
ThatiAR: Subjectivity Detection in Arabic News Sentences
Jun 08, 2024
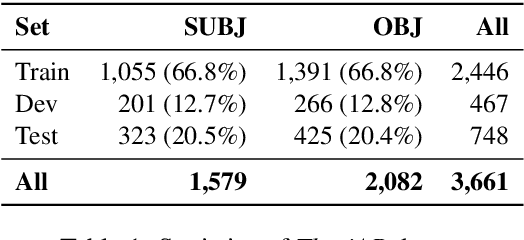
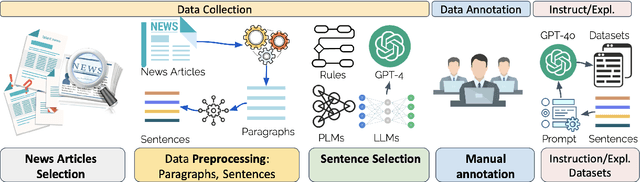
Detecting subjectivity in news sentences is crucial for identifying media bias, enhancing credibility, and combating misinformation by flagging opinion-based content. It provides insights into public sentiment, empowers readers to make informed decisions, and encourages critical thinking. While research has developed methods and systems for this purpose, most efforts have focused on English and other high-resourced languages. In this study, we present the first large dataset for subjectivity detection in Arabic, consisting of ~3.6K manually annotated sentences, and GPT-4o based explanation. In addition, we included instructions (both in English and Arabic) to facilitate LLM based fine-tuning. We provide an in-depth analysis of the dataset, annotation process, and extensive benchmark results, including PLMs and LLMs. Our analysis of the annotation process highlights that annotators were strongly influenced by their political, cultural, and religious backgrounds, especially at the beginning of the annotation process. The experimental results suggest that LLMs with in-context learning provide better performance. We aim to release the dataset and resources for the community.
ArMeme: Propagandistic Content in Arabic Memes
Jun 06, 2024
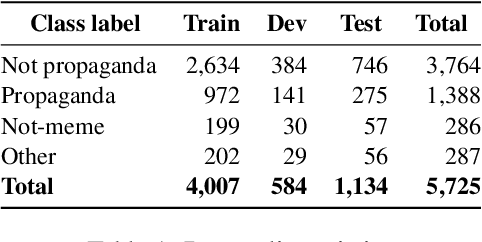


With the rise of digital communication, memes have become a significant medium for cultural and political expression that is often used to mislead audiences. Identification of such misleading and persuasive multimodal content has become more important among various stakeholders, including social media platforms, policymakers, and the broader society as they often cause harm to individuals, organizations, and/or society. While there has been effort to develop AI-based automatic systems for resource-rich languages (e.g., English), it is relatively little to none for medium to low resource languages. In this study, we focused on developing an Arabic memes dataset with manual annotations of propagandistic content. We annotated ~6K Arabic memes collected from various social media platforms, which is a first resource for Arabic multimodal research. We provide a comprehensive analysis aiming to develop computational tools for their detection. We will make them publicly available for the community.
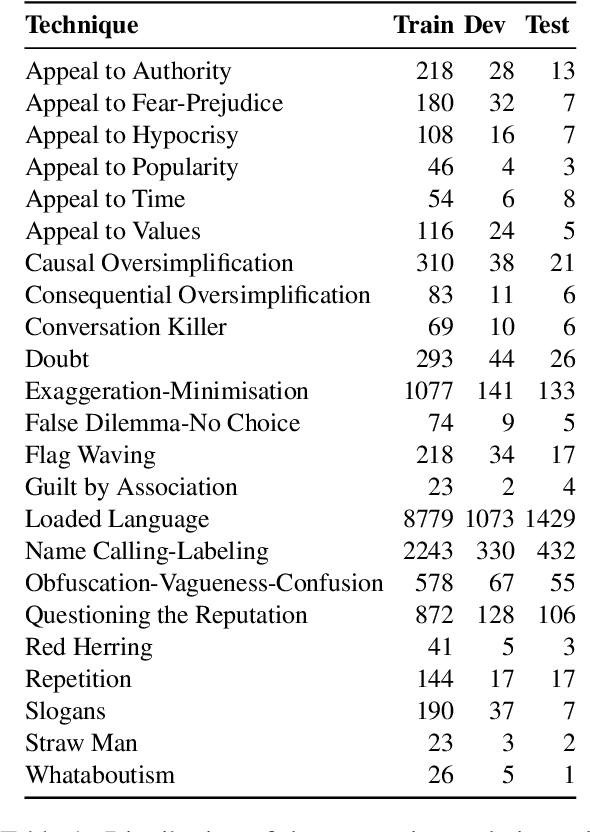
Can GPT-4 Identify Propaganda? Annotation and Detection of Propaganda Spans in News Articles
Feb 27, 2024


The use of propaganda has spiked on mainstream and social media, aiming to manipulate or mislead users. While efforts to automatically detect propaganda techniques in textual, visual, or multimodal content have increased, most of them primarily focus on English content. The majority of the recent initiatives targeting medium to low-resource languages produced relatively small annotated datasets, with a skewed distribution, posing challenges for the development of sophisticated propaganda detection models. To address this challenge, we carefully develop the largest propaganda dataset to date, ArPro, comprised of 8K paragraphs from newspaper articles, labeled at the text span level following a taxonomy of 23 propagandistic techniques. Furthermore, our work offers the first attempt to understand the performance of large language models (LLMs), using GPT-4, for fine-grained propaganda detection from text. Results showed that GPT-4's performance degrades as the task moves from simply classifying a paragraph as propagandistic or not, to the fine-grained task of detecting propaganda techniques and their manifestation in text. Compared to models fine-tuned on the dataset for propaganda detection at different classification granularities, GPT-4 is still far behind. Finally, we evaluate GPT-4 on a dataset consisting of six other languages for span detection, and results suggest that the model struggles with the task across languages. Our dataset and resources will be released to the community.