 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArMeme: Propagandistic Content in Arabic Memes
Paper and Code

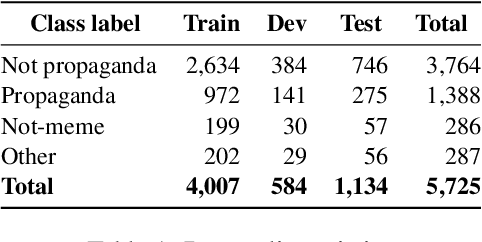


With the rise of digital communication, memes have become a significant medium for cultural and political expression that is often used to mislead audiences. Identification of such misleading and persuasive multimodal content has become more important among various stakeholders, including social media platforms, policymakers, and the broader society as they often cause harm to individuals, organizations, and/or society. While there has been effort to develop AI-based automatic systems for resource-rich languages (e.g., English), it is relatively little to none for medium to low resource languages. In this study, we focused on developing an Arabic memes dataset with manual annotations of propagandistic content. We annotated ~6K Arabic memes collected from various social media platforms, which is a first resource for Arabic multimodal research. We provide a comprehensive analysis aiming to develop computational tools for their detection. We will make them publicly available for the community.