 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Based Multi-Task Bangla Hate Speech Detection: Type, Severity, and Target
Oct 02, 2025Online social media platforms are central to everyday communication and information seeking. While these platforms serve positive purposes, they also provide fertile ground for the spread of hate speech, offensive language, and bullying content targeting individuals, organizations, and communities. Such content undermines safety, participation, and equity online. Reliable detection systems are therefore needed, especially for low-resource languages where moderation tools are limited. In Bangla, prior work has contributed resources and models, but most are single-task (e.g., binary hate/offense) with limited coverage of multi-facet signals (type, severity, target). We address these gaps by introducing the first multi-task Bangla hate-speech dataset, BanglaMultiHate, one of the largest manually annotated corpus to date. Building on this resource, we conduct a comprehensive, controlled comparison spanning classical baselines, monolingual pretrained models, and LLMs under zero-shot prompting and LoRA fine-tuning. Our experiments assess LLM adaptability in a low-resource setting and reveal a consistent trend: although LoRA-tuned LLMs are competitive with BanglaBERT, culturally and linguistically grounded pretraining remains critical for robust performance. Together, our dataset and findings establish a stronger benchmark for developing culturally aligned moderation tools in low-resource contexts. For reproducibility, we will release the dataset and all related scripts.
CultranAI at PalmX 2025: Data Augmentation for Cultural Knowledge Representation
Aug 24, 2025In this paper, we report our participation to the PalmX cultural evaluation shared task. Our system, CultranAI, focused on data augmentation and LoRA fine-tuning of large language models (LLMs) for Arabic cultural knowledge representation. We benchmarked several LLMs to identify the best-performing model for the task. In addition to utilizing the PalmX dataset, we augmented it by incorporating the Palm dataset and curated a new dataset of over 22K culturally grounded multiple-choice questions (MCQs). Our experiments showed that the Fanar-1-9B-Instruct model achieved the highest performance. We fine-tuned this model on the combined augmented dataset of 22K+ MCQs. On the blind test set, our submitted system ranked 5th with an accuracy of 70.50%, while on the PalmX development set, it achieved an accuracy of 84.1%.
SpokenNativQA: Multilingual Everyday Spoken Queries for LLMs
May 25, 2025Large Language Models (LLMs) have demonstrated remarkable performance across various disciplines and tasks. However, benchmarking their capabilities with multilingual spoken queries remains largely unexplored. In this study, we introduce SpokenNativQA, the first multilingual and culturally aligned spoken question-answering (SQA) dataset designed to evaluate LLMs in real-world conversational settings. The dataset comprises approximately 33,000 naturally spoken questions and answers in multiple languages, including low-resource and dialect-rich languages, providing a robust benchmark for assessing LLM performance in speech-based interactions. SpokenNativQA addresses the limitations of text-based QA datasets by incorporating speech variability, accents, and linguistic diversity. We benchmark different ASR systems and LLMs for SQA and present our findings. We released the data at (https://huggingface.co/datasets/QCRI/SpokenNativQA) and the experimental scripts at (https://llmebench.qcri.org/) for the research community.
NativQA Framework: Enabling LLMs with Native, Local, and Everyday Knowledge
Apr 08, 2025The rapid advancement of large language models (LLMs) has raised concerns about cultural bias, fairness, and their applicability in diverse linguistic and underrepresented regional contexts. To enhance and benchmark the capabilities of LLMs, there is a need to develop large-scale resources focused on multilingual, local, and cultural contexts. In this study, we propose a framework, NativQA, that can seamlessly construct large-scale, culturally and regionally aligned QA datasets in native languages. The framework utilizes user-defined seed queries and leverages search engines to collect location-specific, everyday information. It has been evaluated across 39 locations in 24 countries and in 7 languages, ranging from extremely low-resource to high-resource languages, which resulted over 300K Question Answer (QA) pairs. The developed resources can be used for LLM benchmarking and further fine-tuning. The framework has been made publicly available for the community (https://gitlab.com/nativqa/nativqa-framework).
Reasoning About Persuasion: Can LLMs Enable Explainable Propaganda Detection?
Feb 23, 2025There has been significant research on propagandistic content detection across different modalities and languages. However, most studies have primarily focused on detection, with little attention given to explanations justifying the predicted label. This is largely due to the lack of resources that provide explanations alongside annotated labels. To address this issue, we propose a multilingual (i.e., Arabic and English) explanation-enhanced dataset, the first of its kind. Additionally, we introduce an explanation-enhanced LLM for both label detection and rationale-based explanation generation. Our findings indicate that the model performs comparably while also generating explanations. We will make the dataset and experimental resources publicly available for the research community.
MemeIntel: Explainable Detection of Propagandistic and Hateful Memes
Feb 23, 2025The proliferation of multimodal content on social media presents significant challenges in understanding and moderating complex, context-dependent issues such as misinformation, hate speech, and propaganda. While efforts have been made to develop resources and propose new methods for automatic detection, limited attention has been given to label detection and the generation of explanation-based rationales for predicted labels. To address this challenge, we introduce MemeIntel, an explanation-enhanced dataset for propaganda memes in Arabic and hateful memes in English, making it the first large-scale resource for these tasks. To solve these tasks, we propose a multi-stage optimization approach and train Vision-Language Models (VLMs). Our results demonstrate that this approach significantly improves performance over the base model for both \textbf{label detection} and explanation generation, outperforming the current state-of-the-art with an absolute improvement of ~3% on ArMeme and ~7% on Hateful Memes. For reproducibility and future research, we aim to make the MemeIntel dataset and experimental resources publicly available.
Depthwise Separable Convolutions with Deep Residual Convolutions
Nov 12, 2024

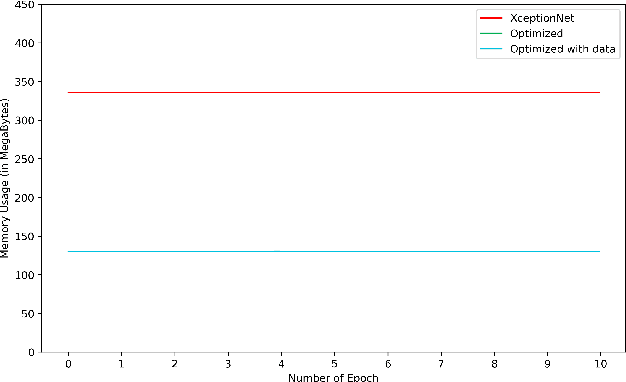
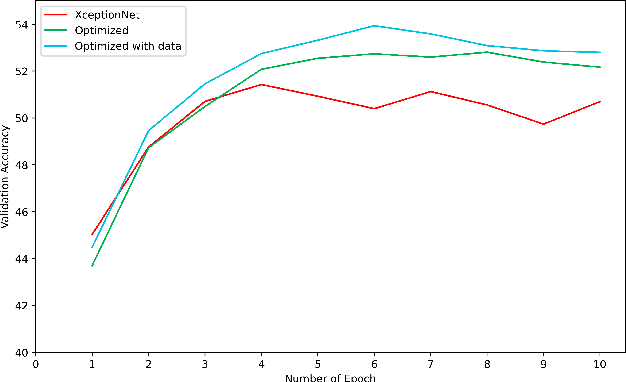
The recent advancement of edge computing enables researchers to optimize various deep learning architectures to employ them in edge devices. In this study, we aim to optimize Xception architecture which is one of the most popular deep learning algorithms for computer vision applications. The Xception architecture is highly effective for object detection tasks. However, it comes with a significant computational cost. The computational complexity of Xception sometimes hinders its deployment on resource-constrained edge devices. To address this, we propose an optimized Xception architecture tailored for edge devices, aiming for lightweight and efficient deployment. We incorporate the depthwise separable convolutions with deep residual convolutions of the Xception architecture to develop a small and efficient model for edge devices. The resultant architecture reduces parameters, memory usage, and computational load. The proposed architecture is evaluated on the CIFAR 10 object detection dataset. The evaluation result of our experiment also shows the proposed architecture is smaller in parameter size and requires less training time while outperforming Xception architecture performance.
ArMeme: Propagandistic Content in Arabic Memes
Jun 06, 2024
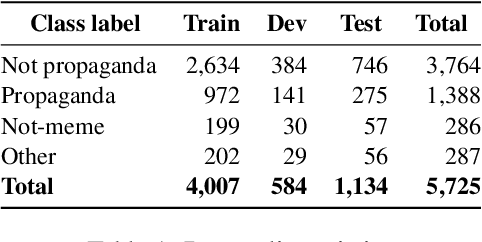


With the rise of digital communication, memes have become a significant medium for cultural and political expression that is often used to mislead audiences. Identification of such misleading and persuasive multimodal content has become more important among various stakeholders, including social media platforms, policymakers, and the broader society as they often cause harm to individuals, organizations, and/or society. While there has been effort to develop AI-based automatic systems for resource-rich languages (e.g., English), it is relatively little to none for medium to low resource languages. In this study, we focused on developing an Arabic memes dataset with manual annotations of propagandistic content. We annotated ~6K Arabic memes collected from various social media platforms, which is a first resource for Arabic multimodal research. We provide a comprehensive analysis aiming to develop computational tools for their detection. We will make them publicly available for the community.
Ensemble Language Models for Multilingual Sentiment Analysis
Mar 10, 2024The rapid advancement of social media enables us to analyze user opinions. In recent times, sentiment analysis has shown a prominent research gap in understanding human sentiment based on the content shared on social media. Although sentiment analysis for commonly spoken languages has advanced significantly, low-resource languages like Arabic continue to get little research due to resource limitations. In this study, we explore sentiment analysis on tweet texts from SemEval-17 and the Arabic Sentiment Tweet dataset. Moreover, We investigated four pretrained language models and proposed two ensemble language models. Our findings include monolingual models exhibiting superior performance and ensemble models outperforming the baseline while the majority voting ensemble outperforms the English language.