 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArAIEval Shared Task: Propagandistic Techniques Detection in Unimodal and Multimodal Arabic Content
Jul 05, 2024
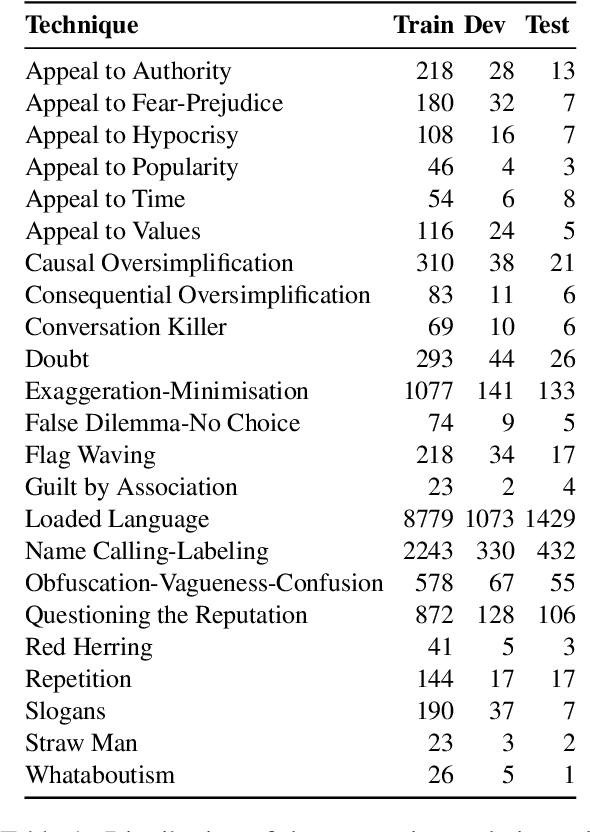


We present an overview of the second edition of the ArAIEval shared task, organized as part of the ArabicNLP 2024 conference co-located with ACL 2024. In this edition, ArAIEval offers two tasks: (i) detection of propagandistic textual spans with persuasion techniques identification in tweets and news articles, and (ii) distinguishing between propagandistic and non-propagandistic memes. A total of 14 teams participated in the final evaluation phase, with 6 and 9 teams participating in Tasks 1 and 2, respectively. Finally, 11 teams submitted system description papers. Across both tasks, we observed that fine-tuning transformer models such as AraBERT was at the core of the majority of the participating systems. We provide a description of the task setup, including a description of the dataset construction and the evaluation setup. We further provide a brief overview of the participating systems. All datasets and evaluation scripts are released to the research community (https://araieval.gitlab.io/). We hope this will enable further research on these important tasks in Arabic.
ArMeme: Propagandistic Content in Arabic Memes
Jun 06, 2024
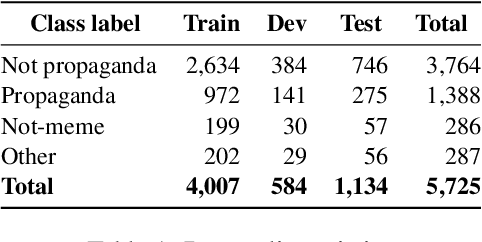


With the rise of digital communication, memes have become a significant medium for cultural and political expression that is often used to mislead audiences. Identification of such misleading and persuasive multimodal content has become more important among various stakeholders, including social media platforms, policymakers, and the broader society as they often cause harm to individuals, organizations, and/or society. While there has been effort to develop AI-based automatic systems for resource-rich languages (e.g., English), it is relatively little to none for medium to low resource languages. In this study, we focused on developing an Arabic memes dataset with manual annotations of propagandistic content. We annotated ~6K Arabic memes collected from various social media platforms, which is a first resource for Arabic multimodal research. We provide a comprehensive analysis aiming to develop computational tools for their detection. We will make them publicly available for the community.
Can GPT-4 Identify Propaganda? Annotation and Detection of Propaganda Spans in News Articles
Feb 27, 2024


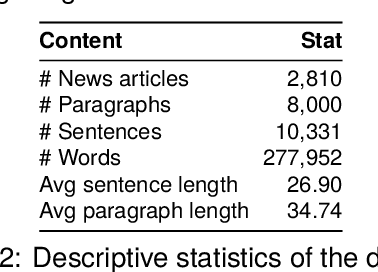
The use of propaganda has spiked on mainstream and social media, aiming to manipulate or mislead users. While efforts to automatically detect propaganda techniques in textual, visual, or multimodal content have increased, most of them primarily focus on English content. The majority of the recent initiatives targeting medium to low-resource languages produced relatively small annotated datasets, with a skewed distribution, posing challenges for the development of sophisticated propaganda detection models. To address this challenge, we carefully develop the largest propaganda dataset to date, ArPro, comprised of 8K paragraphs from newspaper articles, labeled at the text span level following a taxonomy of 23 propagandistic techniques. Furthermore, our work offers the first attempt to understand the performance of large language models (LLMs), using GPT-4, for fine-grained propaganda detection from text. Results showed that GPT-4's performance degrades as the task moves from simply classifying a paragraph as propagandistic or not, to the fine-grained task of detecting propaganda techniques and their manifestation in text. Compared to models fine-tuned on the dataset for propaganda detection at different classification granularities, GPT-4 is still far behind. Finally, we evaluate GPT-4 on a dataset consisting of six other languages for span detection, and results suggest that the model struggles with the task across languages. Our dataset and resources will be released to the community.
Large Language Models for Propaganda Span Annotation
Nov 16, 2023



The use of propagandistic techniques in online communication has increased in recent years, aiming to manipulate online audiences. Efforts to automatically detect and debunk such content have been made, addressing various modeling scenarios. These include determining whether the content (text, image, or multimodal) (i) is propagandistic, (ii) employs one or more techniques, and (iii) includes techniques with identifiable spans. Significant research efforts have been devoted to the first two scenarios compared to the latter. Therefore, in this study, we focus on the task of detecting propagandistic textual spans. We investigate whether large language models such as GPT-4 can be utilized to perform the task of an annotator. For the experiments, we used an in-house developed dataset consisting of annotations from multiple annotators. Our results suggest that providing more information to the model as prompts improves the annotation agreement and performance compared to human annotations. We plan to make the annotated labels from multiple annotators, including GPT-4, available for the community.