 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly Prediction of Type 2 Diabetes Using Multimodal data and Tabular Transformers
Jan 19, 2026This study introduces a novel approach for early Type 2 Diabetes Mellitus (T2DM) risk prediction using a tabular transformer (TabTrans) architecture to analyze longitudinal patient data. By processing patients` longitudinal health records and bone-related tabular data, our model captures complex, long-range dependencies in disease progression that conventional methods often overlook. We validated our TabTrans model on a retrospective Qatar BioBank (QBB) cohort of 1,382 subjects, comprising 725 men (146 diabetic, 579 healthy) and 657 women (133 diabetic, 524 healthy). The study integrated electronic health records (EHR) with dual-energy X-ray absorptiometry (DXA) data. To address class imbalance, we employed SMOTE and SMOTE-ENN resampling techniques. The proposed model`s performance is evaluated against conventional machine learning (ML) and generative AI models, including Claude 3.5 Sonnet (Anthropic`s constitutional AI), GPT-4 (OpenAI`s generative pre-trained transformer), and Gemini Pro (Google`s multimodal language model). Our TabTrans model demonstrated superior predictive performance, achieving ROC AUC $\geq$ 79.7 % for T2DM prediction compared to both generative AI models and conventional ML approaches. Feature interpretation analysis identified key risk indicators, with visceral adipose tissue (VAT) mass and volume, ward bone mineral density (BMD) and bone mineral content (BMC), T and Z-scores, and L1-L4 scores emerging as the most important predictors associated with diabetes development in Qatari adults. These findings demonstrate the significant potential of TabTrans for analyzing complex tabular healthcare data, providing a powerful tool for proactive T2DM management and personalized clinical interventions in the Qatari population. Index Terms: tabular transformers, multimodal data, DXA data, diabetes, T2DM, feature interpretation, tabular data
An Annotated Corpus of Arabic Tweets for Hate Speech Analysis
May 17, 2025Identifying hate speech content in the Arabic language is challenging due to the rich quality of dialectal variations. This study introduces a multilabel hate speech dataset in the Arabic language. We have collected 10000 Arabic tweets and annotated each tweet, whether it contains offensive content or not. If a text contains offensive content, we further classify it into different hate speech targets such as religion, gender, politics, ethnicity, origin, and others. A text can contain either single or multiple targets. Multiple annotators are involved in the data annotation task. We calculated the inter-annotator agreement, which was reported to be 0.86 for offensive content and 0.71 for multiple hate speech targets. Finally, we evaluated the data annotation task by employing a different transformers-based model in which AraBERTv2 outperformed with a micro-F1 score of 0.7865 and an accuracy of 0.786.
EmoHopeSpeech: An Annotated Dataset of Emotions and Hope Speech in English and Arabic
May 17, 2025This research introduces a bilingual dataset comprising 23,456 entries for Arabic and 10,036 entries for English, annotated for emotions and hope speech, addressing the scarcity of multi-emotion (Emotion and hope) datasets. The dataset provides comprehensive annotations capturing emotion intensity, complexity, and causes, alongside detailed classifications and subcategories for hope speech. To ensure annotation reliability, Fleiss' Kappa was employed, revealing 0.75-0.85 agreement among annotators both for Arabic and English language. The evaluation metrics (micro-F1-Score=0.67) obtained from the baseline model (i.e., using a machine learning model) validate that the data annotations are worthy. This dataset offers a valuable resource for advancing natural language processing in underrepresented languages, fostering better cross-linguistic analysis of emotions and hope speech.
Propaganda to Hate: A Multimodal Analysis of Arabic Memes with Multi-Agent LLMs
Sep 11, 2024



In the past decade, social media platforms have been used for information dissemination and consumption. While a major portion of the content is posted to promote citizen journalism and public awareness, some content is posted to mislead users. Among different content types such as text, images, and videos, memes (text overlaid on images) are particularly prevalent and can serve as powerful vehicles for propaganda, hate, and humor. In the current literature, there have been efforts to individually detect such content in memes. However, the study of their intersection is very limited. In this study, we explore the intersection between propaganda and hate in memes using a multi-agent LLM-based approach. We extend the propagandistic meme dataset with coarse and fine-grained hate labels. Our finding suggests that there is an association between propaganda and hate in memes. We provide detailed experimental results that can serve as a baseline for future studies. We will make the experimental resources publicly available to the community.
Nullpointer at CheckThat! 2024: Identifying Subjectivity from Multilingual Text Sequence
Jul 14, 2024
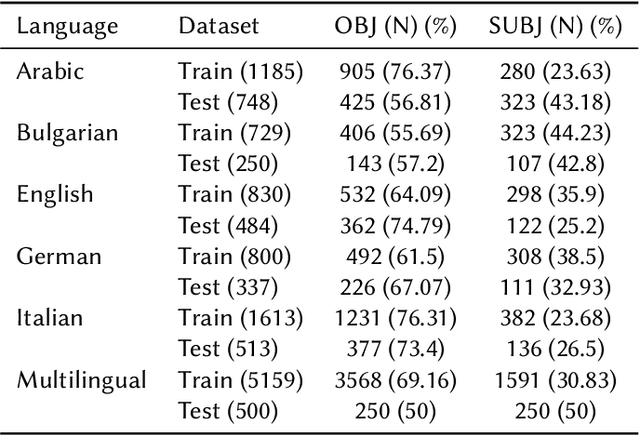
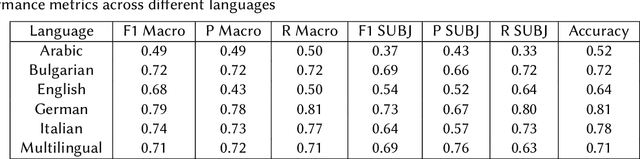
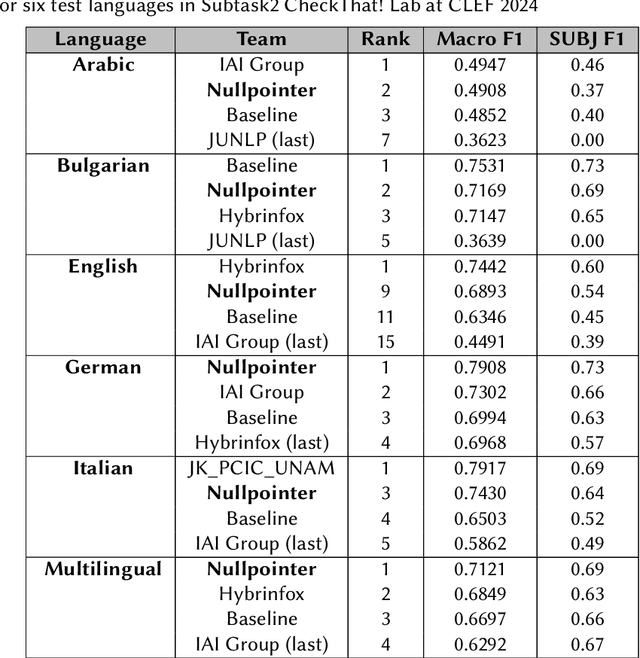
This study addresses a binary classification task to determine whether a text sequence, either a sentence or paragraph, is subjective or objective. The task spans five languages: Arabic, Bulgarian, English, German, and Italian, along with a multilingual category. Our approach involved several key techniques. Initially, we preprocessed the data through parts of speech (POS) tagging, identification of question marks, and application of attention masks. We fine-tuned the sentiment-based Transformer model 'MarieAngeA13/Sentiment-Analysis-BERT' on our dataset. Given the imbalance with more objective data, we implemented a custom classifier that assigned greater weight to objective data. Additionally, we translated non-English data into English to maintain consistency across the dataset. Our model achieved notable results, scoring top marks for the multilingual dataset (Macro F1=0.7121) and German (Macro F1=0.7908). It ranked second for Arabic (Macro F1=0.4908) and Bulgarian (Macro F1=0.7169), third for Italian (Macro F1=0.7430), and ninth for English (Macro F1=0.6893).
ArAIEval Shared Task: Propagandistic Techniques Detection in Unimodal and Multimodal Arabic Content
Jul 05, 2024
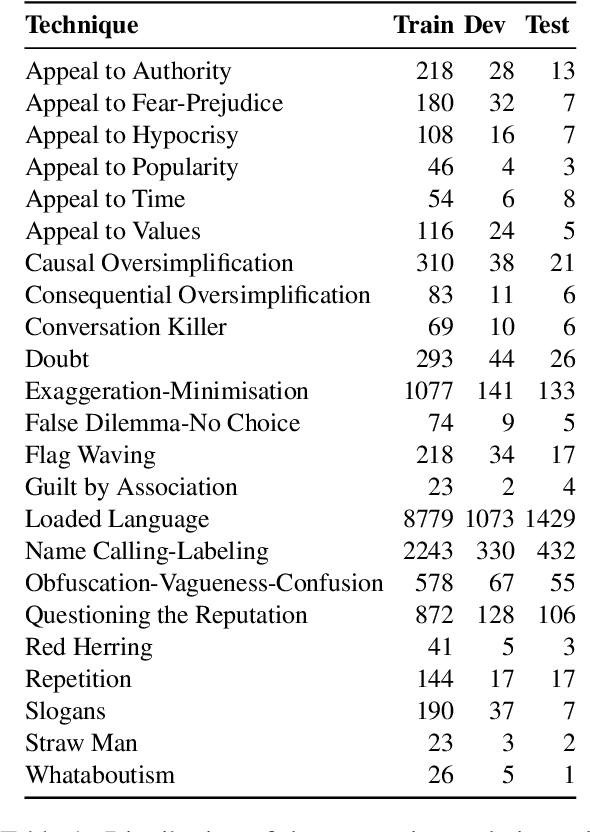


We present an overview of the second edition of the ArAIEval shared task, organized as part of the ArabicNLP 2024 conference co-located with ACL 2024. In this edition, ArAIEval offers two tasks: (i) detection of propagandistic textual spans with persuasion techniques identification in tweets and news articles, and (ii) distinguishing between propagandistic and non-propagandistic memes. A total of 14 teams participated in the final evaluation phase, with 6 and 9 teams participating in Tasks 1 and 2, respectively. Finally, 11 teams submitted system description papers. Across both tasks, we observed that fine-tuning transformer models such as AraBERT was at the core of the majority of the participating systems. We provide a description of the task setup, including a description of the dataset construction and the evaluation setup. We further provide a brief overview of the participating systems. All datasets and evaluation scripts are released to the research community (https://araieval.gitlab.io/). We hope this will enable further research on these important tasks in Arabic.
An Early Investigation into the Utility of Multimodal Large Language Models in Medical Imaging
Jun 02, 2024Recent developments in multimodal large language models (MLLMs) have spurred significant interest in their potential applications across various medical imaging domains. On the one hand, there is a temptation to use these generative models to synthesize realistic-looking medical image data, while on the other hand, the ability to identify synthetic image data in a pool of data is also significantly important. In this study, we explore the potential of the Gemini (\textit{gemini-1.0-pro-vision-latest}) and GPT-4V (gpt-4-vision-preview) models for medical image analysis using two modalities of medical image data. Utilizing synthetic and real imaging data, both Gemini AI and GPT-4V are first used to classify real versus synthetic images, followed by an interpretation and analysis of the input images. Experimental results demonstrate that both Gemini and GPT-4 could perform some interpretation of the input images. In this specific experiment, Gemini was able to perform slightly better than the GPT-4V on the classification task. In contrast, responses associated with GPT-4V were mostly generic in nature. Our early investigation presented in this work provides insights into the potential of MLLMs to assist with the classification and interpretation of retinal fundoscopy and lung X-ray images. We also identify key limitations associated with the early investigation study on MLLMs for specialized tasks in medical image analysis.
Pushing Boundaries: Exploring Zero Shot Object Classification with Large Multimodal Models
Dec 30, 2023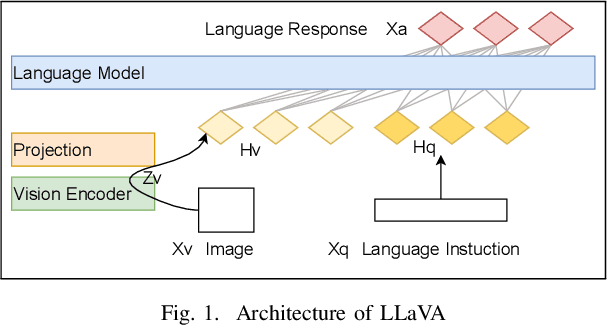
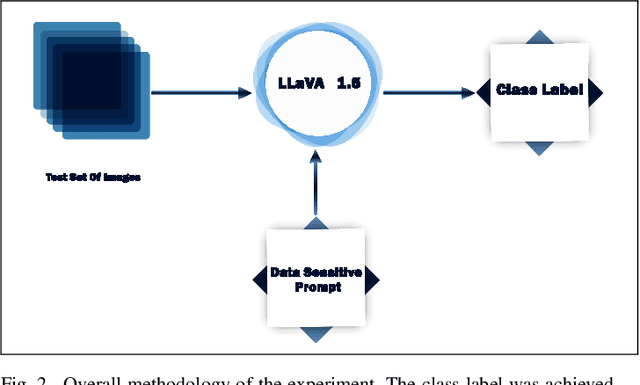


$ $The synergy of language and vision models has given rise to Large Language and Vision Assistant models (LLVAs), designed to engage users in rich conversational experiences intertwined with image-based queries. These comprehensive multimodal models seamlessly integrate vision encoders with Large Language Models (LLMs), expanding their applications in general-purpose language and visual comprehension. The advent of Large Multimodal Models (LMMs) heralds a new era in Artificial Intelligence (AI) assistance, extending the horizons of AI utilization. This paper takes a unique perspective on LMMs, exploring their efficacy in performing image classification tasks using tailored prompts designed for specific datasets. We also investigate the LLVAs zero-shot learning capabilities. Our study includes a benchmarking analysis across four diverse datasets: MNIST, Cats Vs. Dogs, Hymnoptera (Ants Vs. Bees), and an unconventional dataset comprising Pox Vs. Non-Pox skin images. The results of our experiments demonstrate the model's remarkable performance, achieving classification accuracies of 85\%, 100\%, 77\%, and 79\% for the respective datasets without any fine-tuning. To bolster our analysis, we assess the model's performance post fine-tuning for specific tasks. In one instance, fine-tuning is conducted over a dataset comprising images of faces of children with and without autism. Prior to fine-tuning, the model demonstrated a test accuracy of 55\%, which significantly improved to 83\% post fine-tuning. These results, coupled with our prior findings, underscore the transformative potential of LLVAs and their versatile applications in real-world scenarios.
* 5 pages,6 figures, 4 tables, Accepted on The International Symposium on Foundation and Large Language Models (FLLM2023)
Can ChatGPT be Your Personal Medical Assistant?
Dec 19, 2023The advanced large language model (LLM) ChatGPT has shown its potential in different domains and remains unbeaten due to its characteristics compared to other LLMs. This study aims to evaluate the potential of using a fine-tuned ChatGPT model as a personal medical assistant in the Arabic language. To do so, this study uses publicly available online questions and answering datasets in Arabic language. There are almost 430K questions and answers for 20 disease-specific categories. GPT-3.5-turbo model was fine-tuned with a portion of this dataset. The performance of this fine-tuned model was evaluated through automated and human evaluation. The automated evaluations include perplexity, coherence, similarity, and token count. Native Arabic speakers with medical knowledge evaluated the generated text by calculating relevance, accuracy, precision, logic, and originality. The overall result shows that ChatGPT has a bright future in medical assistance.
* 5 pages, 7 figures, two tables, Accepted on The International Symposium on Foundation and Large Language Models (FLLM2023)